第3章 从提示工程到上下文工程:范式跃迁
本章来源:综合自 ce101/basics(上下文工程基础与技术栈)、Hello-Agents/chapter9(上下文工程实践)、agentic-design-patterns/Appendix A(高级提示技术与上下文工程)
核心问题 —— 本章要解答什么
当智能体从"单轮问答工具"演化为"自主任务执行系统"时,驱动其行为的不再是一句精心措辞的提示词,而是一个动态构建的、包含多层信息的上下文环境。提示工程(Prompt Engineering)关注的是"如何措辞一句话",上下文工程(Context Engineering)关注的则是"如何为模型构建一个完整的操作图景"。这一范式跃迁是智能体工程化的核心命题。本章聚焦以下关键问题:
- 提示工程为什么在智能体场景中触及天花板?其根本性局限是什么?
- 上下文工程与提示工程的本质区别是什么?为什么Andrej Karpathy将其视为"新的核心技能"?
- 上下文窗口面临哪些系统性问题(信息中毒、注意力失焦、语义冲突)?
- 上下文工程技术栈的三大支柱(增强、优化、持久化)分别解决什么问题?
- 在实际智能体系统中,GSSC流水线如何将上下文工程落地为可执行的工程实践?
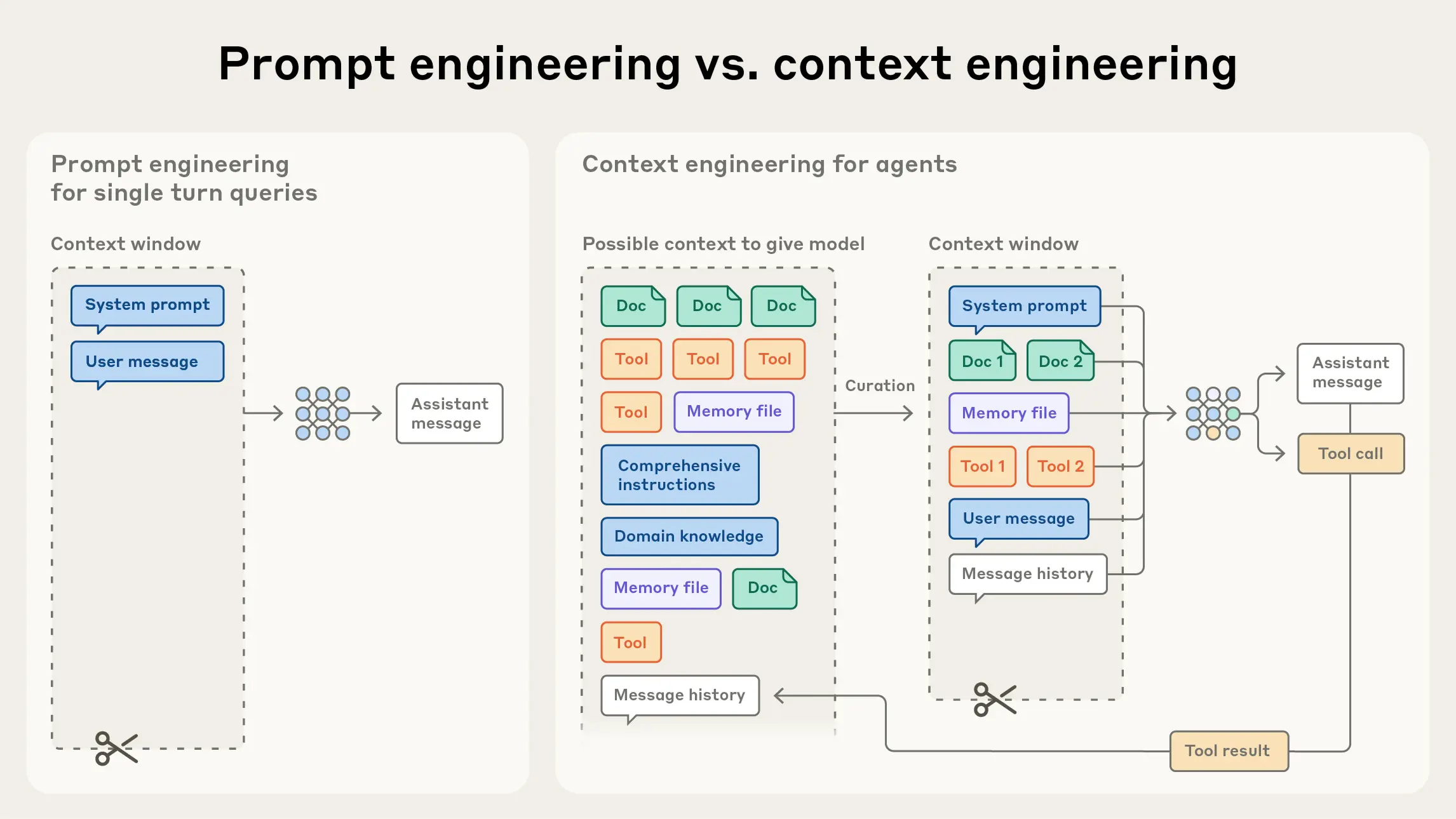
设计空间 —— 可选方案与取舍
围绕"上下文构建"的设计存在一组核心取舍:
| 维度 | 取值范围 | 设计考量 |
|---|---|---|
| 信息来源 | 静态系统提示 ↔ 动态多源汇聚 | 静态提示简单可控,但无法适应任务变化;动态汇聚灵活但引入复杂性 |
| 上下文容量管理 | 全量填充 ↔ 选择性填充 ↔ 压缩填充 | 全量填充浪费Token且可能引入噪声;选择性填充需要相关性评估;压缩填充有信息损失风险 |
| 持久化策略 | 无持久化 ↔ 会话级缓存 ↔ 跨会话记忆 | 无持久化每次从零开始;会话级缓存覆盖单次任务;跨会话记忆支持长期学习但复杂度高 |
| 构建时机 | 预构建 ↔ 即时构建(JIT) | 预构建延迟低但可能包含过时信息;JIT构建信息最新但增加响应延迟 |
| 结构化程度 | 自由拼接 ↔ 分区模板 | 自由拼接灵活但模型可能混淆不同来源的信息;分区模板清晰但不够灵活 |
架构解析 —— 从提示词到上下文的范式演进
3.3.1 提示工程的成就与天花板
提示工程是与LLM交互的起点。它的核心原则包括清晰性与具体性、简洁性、善用动词、指令优于约束、以及实验与迭代。在这些原则的指导下,提示工程发展出了一系列成熟的技术:
- 系统提示(System Prompting):设定模型的角色、行为准则和交互风格,为整个会话提供基础框架。
- 角色提示(Role Prompting):赋予模型特定身份和专业背景,使其输出更贴合特定场景需求。
- 分隔符使用(Delimiters):用三重反引号、XML标签或标记线等符号分隔指令、上下文和输入,减少模型的误解。
- 结构化输出:指定JSON、XML等机器可读格式,使LLM输出可被程序化解析。
- 思维链与推理增强:通过CoT [Wei et al., 2022]、Self-Consistency、ToT [Yao et al., 2023] 等技术提升复杂推理能力。
这些技术在单轮或少量轮次的交互中效果显著。但当我们将LLM置于智能体的角色中——需要它在多步任务中持续做出正确决策——提示工程触及了其根本性天花板:
天花板一:静态性。 提示词一旦写好就是固定的。但智能体面对的任务是动态的——用户意图在变化,环境状态在更新,工具执行结果在反馈。静态提示无法响应这些变化。
天花板二:信息平面化。 提示工程将所有信息压缩在一段文本中,缺乏层次结构。系统指令、用户意图、历史对话、检索结果、工具输出等不同性质的信息被混在一起,模型难以正确区分各自的角色和权重。
天花板三:无持久化能力。 提示工程是无状态的。每次交互都从零开始构建提示,无法利用之前积累的经验和知识。对于需要长期记忆和持续学习的智能体,这是致命缺陷。
天花板四:不可扩展。 随着智能体系统复杂度增长(更多工具、更长的任务链、多Agent协作),手工调优提示词的方式无法扩展。
3.3.2 上下文工程的定义与核心理念
Andrej Karpathy在2025年提出了一个精辟的定义:
"Context Engineering is the subtle art and science of filling the context window with just the right information for the next step."
上下文工程是一门精妙的艺术和科学,其核心在于用恰好正确的信息填充上下文窗口,以支撑模型的下一步决策。
这个定义揭示了上下文工程的三个本质特征:
- "恰好正确"而非"尽可能多":上下文窗口是有限的稀缺资源,关键不在于塞入更多信息,而在于选择最相关的信息。
- "下一步"而非"整个任务":上下文应该针对模型即将执行的具体步骤进行优化,而非试图一次性覆盖所有可能性。
- "科学"而非"技巧":上下文构建应该是系统化、可量化、可迭代的工程过程,而非依赖经验和直觉的黑箱调优。
上下文工程与提示工程的本质区别可以概括为:提示工程优化的是"如何措辞一个请求",上下文工程优化的是"如何为模型构建一个完整的操作环境"。 提示工程是上下文工程的子集——一条好的提示词仍然重要,但它只是上下文的组成部分之一。
在Agentic系统中,上下文工程是支撑智能体核心能力(记忆持久化、决策制定、跨子任务协调)的基础设施。具备动态上下文管道的智能体能够维持长期目标、调整策略、并与其他智能体或工具协作——这些是实现长期自主性的关键特质。
3.3.3 上下文窗口的系统性问题
上下文窗口是LLM接收信息的唯一通道,也是上下文工程的核心约束。在智能体的长时任务执行中,上下文窗口面临三类系统性问题:
问题一:信息中毒(Context Poisoning)
当错误的、过时的或不相关的信息混入上下文时,会"中毒"模型的决策过程。例如:RAG检索返回了看似相关但实际不准确的文档片段;历史对话中包含了已被纠正的错误信息;工具调用返回了异常结果。
信息中毒的危险在于LLM倾向于"相信"上下文中提供的信息。如果一条错误信息以高置信度出现在上下文中,模型很可能会基于它做出错误决策,即使模型自身的训练知识是正确的。
问题二:注意力失焦(Attention Misalignment)
研究表明,LLM的注意力分配并不均匀——模型对上下文开头和结尾的信息关注度最高,对中间部分的关注度最低("lost in the middle"效应)[Liu et al., 2023]。在20篇文档的检索增强实验中,当关键信息位于中间位置时,模型性能下降超过20个百分点。当上下文窗口填满大量信息时,关键信息可能被淹没在中间位置而被模型忽视。
此外,不同类型的信息(指令、证据、背景)如果没有清晰的结构化分隔,模型可能将背景信息误当作需要执行的指令,或将指令误当作需要回答的问题。
问题三:语义冲突(Semantic Conflict)
当上下文中包含来自不同来源的、相互矛盾的信息时,模型面临语义冲突。例如:系统指令要求"简洁回答",但用户提示要求"详细解释";RAG检索到的两篇文档对同一问题给出了相反的结论。
语义冲突迫使模型在矛盾的指令间做出隐式选择,而这种选择往往不可预测、不可控制。
3.3.4 上下文工程技术栈:三大支柱
针对上述问题,上下文工程发展出了一个系统化的技术栈,可以归纳为三大支柱:
支柱一:上下文增强(Context Augmentation)
解决的问题是"如何让模型获取到它不知道的信息"。核心技术包括:
- 检索增强生成(RAG):在生成之前从外部知识库检索相关信息,注入到上下文中。RAG是缓解模型幻觉和知识过时的最成熟方案。
- 工具输出注入:将工具调用的返回结果(如API响应、代码执行结果、搜索结果)作为证据注入上下文,为模型决策提供事实基础。
- 即时上下文(JIT Context):在模型执行的每一步,根据当前状态动态计算并注入最相关的信息,而非在会话开始时一次性加载所有可能需要的信息。
支柱二:上下文优化(Context Optimization)
解决的问题是"如何在有限的上下文窗口中最大化信息价值"。核心技术包括:
- 相关性排序与选择:对候选信息按照与当前任务的相关性进行评分,优先选择得分最高的信息填入上下文。
- Token感知压缩:当上下文总量超过窗口限制时,通过摘要、截断或分区压缩等策略减少Token消耗,同时尽量保留关键信息。Claude Code的压缩提示就是这一技术的工程实践——它在上下文接近窗口限制时自动触发对话历史压缩,保留关键决策和结论,丢弃冗余的中间过程。
- 结构化分区:将上下文组织为清晰的分区(Role & Policies、Task、Evidence、Context、Output),帮助模型区分不同类型信息的角色和权重,缓解注意力失焦和语义冲突。
支柱三:上下文持久化(Context Persistence)
解决的问题是"如何让信息跨越单次对话的边界"。核心技术包括:
- 会话存储:将对话历史持久化到数据库(如Redis),支持会话的中断和恢复。
- 语义记忆:将重要信息提取为结构化的记忆条目,通过向量检索在未来的交互中召回相关记忆。
- 结构化笔记:在长时任务中维护一份持续更新的结构化笔记(类似Claude Code的auto memory),记录关键决策、进度和待办事项,作为跨对话的"工作台"。
3.3.5 GSSC流水线:上下文工程的工程落地
将上述三大支柱整合为一个可执行的工程流程,就是GSSC(Gather-Select-Structure-Compress)流水线。它将上下文构建分解为四个清晰的阶段:
阶段一:Gather(汇集)
从多个来源收集候选信息:系统指令(最高优先级,始终保留)、记忆系统检索结果、RAG知识库检索结果、最近的对话历史、自定义信息包。每个来源的调用都带有容错机制,确保单个来源的失败不影响整体流程。
阶段二:Select(选择)
对候选信息进行评分和排序。综合分数由两个维度加权计算:
其中
阶段三:Structure(结构化)
将选中的信息按类型组织为分区模板:
[Role & Policies] ← 系统指令和角色定义
[Task] ← 当前用户查询
[Evidence] ← 从RAG/知识库检索的证据
[Context] ← 对话历史和相关记忆
[Output] ← 输出格式要求和约束这种分区结构为模型提供了清晰的信息层次,帮助其正确区分指令、证据和背景信息。
阶段四:Compress(压缩)
当结构化后的上下文仍超出Token预算时,执行兜底压缩。压缩策略遵循"保持结构完整性"的原则——优先保留完整的分区,在不得不截断时标注"[... 内容已压缩 ...]",确保模型知道信息是不完整的。
GSSC流水线的工程价值在于它将上下文工程从"经验调优"提升为"系统过程":每个阶段的逻辑清晰、可独立测试、可参数化配置。当上下文质量出现问题时,可以精确定位到哪个阶段出了问题(收集遗漏?选择偏差?结构混乱?压缩损失?),而非在一团混沌的提示词中摸索。
关键实现决策 —— 上下文工程的工程化选择
决策一:上下文预算分配策略
有限的上下文窗口如何在不同类型的信息之间分配?一个经过实践验证的策略是"预留制":
- 为系统指令预留固定比例(如20%),确保角色定义和行为准则始终存在。
- 为用户当前查询和输出格式预留固定空间。
- 剩余空间在RAG证据、对话历史和记忆之间按相关性动态分配。
reserve_ratio 参数化了这一策略,使其可以根据不同类型的智能体进行调优:面向知识问答的智能体可能需要更多空间给RAG证据,而面向多轮对话的智能体则需要更多空间给对话历史。
决策二:信息新鲜度的衰减模型
在长时运行的智能体中,旧信息的价值会随时间递减。指数衰减模型提供了一个合理的近似:
其中
决策三:长时任务中的上下文管理
当智能体执行的任务跨度超过单次上下文窗口时,需要专门的管理策略:
- 对话压缩(Compaction):当对话历史接近窗口限制时,触发自动压缩——保留关键结论和决策,将冗余的中间过程替换为摘要。
- 结构化笔记(Structured Notes):维护一份持续更新的笔记文件,记录任务目标、当前进度、关键发现和待办事项。每次新的对话轮次开始时,加载这份笔记作为上下文的一部分。
- 子智能体分治(Sub-Agent Dispatch):将独立的子任务分派给子智能体处理,子智能体拥有独立的上下文窗口,完成后只将结果摘要返回主智能体。这有效地将上下文需求分散到多个窗口中。
前沿动态 —— 上下文工程的演进方向
趋势一:从手工构建到自动化流水线
早期的上下文工程依赖开发者的经验和直觉。未来的方向是将上下文构建自动化——通过评估指标(如上下文质量分数、任务完成率、Token利用率等)建立反馈循环,自动优化每个GSSC阶段的参数配置。Google的Vertex AI Prompt Optimizer已经在这个方向上迈出了第一步。
趋势二:上下文窗口的持续扩展与其悖论
模型的上下文窗口持续增大(从4K到128K再到1M甚至10M Token)。RULER基准测试 [Hsieh et al., 2024] 表明,大多数声称支持长上下文的模型在实际有效长度上远低于标称值。更大的窗口并不意味着更好的上下文工程——"lost in the middle"效应随窗口增大而加剧,注意力资源的稀释使得关键信息更容易被忽视。这形成了一个悖论:窗口越大,精细化的上下文管理反而越重要。
趋势三:多模态上下文
随着LLM的多模态能力增强,上下文不再局限于文本。图像、音频、视频、结构化数据等都可以成为上下文的组成部分。这对GSSC流水线提出了新的要求:多模态信息的Token估算、跨模态的相关性评估、以及混合模态的结构化组织。
本章小结
本章描绘了从提示工程到上下文工程的范式跃迁:
- 为什么需要跃迁:提示工程的静态性、信息平面化、无持久化和不可扩展性,使其无法支撑智能体的复杂需求。上下文工程通过动态、多层、持久化的信息管理来填补这一空白。
- 核心问题域:上下文窗口面临信息中毒、注意力失焦和语义冲突三类系统性挑战,每一类都需要有针对性的技术方案。
- 三大技术支柱:增强(让模型获取新信息)、优化(在有限窗口中最大化信息价值)、持久化(让信息跨越对话边界),构成了上下文工程的完整技术栈。
- 工程落地:GSSC流水线(Gather-Select-Structure-Compress)将上下文工程系统化为可测试、可参数化、可迭代的工程过程。
⚠️ 已知局限:上下文工程的核心假设是"正确的信息+正确的位置=正确的决策",但这一假设在多个场景下会失效。当检索系统返回高置信度但事实错误的文档时(信息中毒),精心设计的上下文结构反而会放大错误——模型更倾向于相信结构化上下文中的信息而忽视自身训练知识。此外,当前的GSSC流水线在多模态上下文(图文混合)场景中缺乏成熟的Token预算分配方案。
上下文工程是连接LLM能力与智能体系统需求的桥梁。从第4章开始,我们将进入智能体的经典范式领域——ReAct、Plan-and-Solve、Reflection——这些范式的每一个都深度依赖于高质量的上下文构建来实现其推理-行动循环。