第12章 记忆架构设计:从短期到长期
本章来源:综合自 Hello-Agents 第8章(四层记忆类型的详细设计与读写策略)、Agentic Design Patterns 第8章(Memory Management 中的 Session/State/Memory 实现)
核心问题 -- 本章要解答什么
上一章建立了从认知科学到智能体记忆的理论映射。本章深入每种记忆类型的具体架构设计——工作记忆如何管理有限的上下文空间?情景记忆如何高效存储和检索交互历史?语义记忆如何构建和维护知识网络?感知记忆如何处理多模态信息?
这些不是抽象的架构讨论,而是直接影响智能体行为质量的工程决策。一个工作记忆管理不当的智能体会在长对话中丢失关键上下文;一个情景记忆检索不佳的智能体无法从历史经验中学习;一个语义记忆组织混乱的智能体无法建立有效的知识体系。
设计空间 -- 可选方案与取舍
12.1 工作记忆(Working Memory)
12.1.1 设计目标与约束
工作记忆是智能体的"即时认知空间",核心约束是容量有限且生命周期短暂。设计目标是在有限空间内保持最相关的信息,使智能体在当前任务中拥有足够的上下文。
关键参数:
- 容量限制:典型设定为 50-100 条记忆项,或按 token 数限制
- 生命周期:绑定到会话或任务,会话结束自动清理
- 访问速度:必须极快(纯内存操作),因为每次 LLM 调用都需要从工作记忆构建上下文
12.1.2 TTL 管理
工作记忆中的每条信息都有生存时间(Time-to-Live)。超过 TTL 的信息自动过期,为新信息腾出空间。TTL 的设计需要权衡:
- 固定 TTL:所有信息统一过期时间(如 30 分钟)。简单但不区分信息重要性。
- 动态 TTL:根据信息重要性动态调整过期时间。重要信息(如用户偏好)TTL 长,普通对话 TTL 短。
- 引用延寿:每次被检索或引用时重置 TTL。类似缓存的 LRU 策略,确保常用信息不被淘汰。
12.1.3 溢出策略
当工作记忆达到容量上限时,需要决定如何处理新信息:
- LRU 淘汰:移除最久未被访问的记忆项。简单高效,但可能丢失虽不常访问但很重要的信息。
- 重要性淘汰:移除重要性评分最低的记忆项。更智能,但需要维护评分。
- 整合淘汰:将低优先级信息整合(摘要压缩)到长期记忆后删除。兼顾空间释放和信息保留,但增加计算开销。
12.2 情景记忆(Episodic Memory)
12.2.1 设计目标
情景记忆存储具体的、带时间戳的交互事件。它是智能体的"自传"——记录了发生过什么、什么时候发生的、在什么上下文中发生的。与工作记忆的临时性不同,情景记忆具有长期持久性。
每条情景记忆包含丰富的元数据:
- 核心内容:记忆的文本内容
- 时间戳:创建时间、最后访问时间
- 上下文信息:当时的对话主题、用户状态
- 重要性评分:由系统或 LLM 评估的重要性级别
- 情感标签:正面/负面/中性
- 关联关系:与其他记忆的关联链接
12.2.2 存储架构
情景记忆通常采用双存储架构:
结构化存储(SQLite):存储记忆的元数据和结构化字段——ID、时间戳、类型、重要性、标签等。支持精确的条件查询(如"检索过去一周重要性大于0.7的所有交互")。
向量存储(Qdrant):存储记忆内容的向量嵌入。支持语义搜索(如"找到与'机器学习'相关的所有讨论")。
两种存储协同工作:语义搜索先从向量存储中获取候选集,再用结构化查询进行过滤和排序。这种组合提供了语义理解和精确过滤的双重能力。
12.2.3 检索策略
情景记忆的检索需要平衡相关性和时间性:
纯语义检索:只基于查询与记忆内容的语义相似度排序。优势是能找到最相关的内容,劣势是忽略时间因素——一年前的对话可能与当前查询高度相关但已过时。
时间加权检索:在语义相似度的基础上引入时间衰减因子。越近的记忆权重越高。公式通常为:score = similarity * decay(age),其中 decay 是递减函数(如指数衰减)。
混合检索:先用语义搜索获取候选集,再按时间和重要性排序。最灵活但计算成本也最高。
12.2.4 遗忘与维护
情景记忆不能无限增长。遗忘策略包括:
- 时间衰减删除:超过特定时间阈值(如90天)且重要性低于阈值的记忆自动删除
- 容量触发清理:当总记忆数超过上限时,按"重要性 x 新近度"的综合评分从低到高删除
- 主题压缩:将同一主题的多条记忆压缩为一条摘要记忆
12.3 语义记忆(Semantic Memory)

12.3.1 设计目标
Generative Agents [Park et al., 2023] 首次在大规模模拟中验证了记忆检索、反思和规划的完整认知闭环,其中情景记忆的时间加权检索机制成为后续工作的标准范式。语义记忆存储抽象的知识、概念和规则——从具体经历中提炼出的通用知识。例如,"用户张三偏好简洁的代码风格"是语义记忆(抽象偏好),而"昨天张三要求我把函数缩短到10行以内"是情景记忆(具体事件)。
语义记忆的核心特征是关系性——知识不是孤立的条目,而是通过概念间的关系形成网络。"Python"与"编程语言"是 IS-A 关系,"张三"与"Python 开发者"是 HAS-ROLE 关系。这些关系使语义记忆支持关联推理。
12.3.2 双存储架构
语义记忆采用向量存储 + 图存储的双存储架构:
向量存储(Qdrant):存储知识的向量嵌入,支持语义相似度搜索。适合回答"与 X 相关的知识有哪些?"这类模糊查询。
图存储(Neo4j):存储实体和关系,形成知识图谱。适合回答"X 和 Y 是什么关系?"这类关系查询。图结构天然支持多跳推理——从一个实体出发,沿关系边遍历,可以发现间接关联。
两种存储的协同使语义记忆兼具语义理解(通过向量搜索找到概念上相关的知识)和关系推理(通过图遍历发现结构化的实体关系)。
12.3.3 知识抽取
将自然语言转化为结构化的实体-关系知识是语义记忆的核心挑战。主要方法:
NLP 管线:使用命名实体识别(NER)+ 关系抽取(RE)的传统 NLP 管线。例如,使用 spaCy 识别实体,使用训练好的分类器识别关系。精度可控但需要针对领域训练。
LLM 抽取:使用 LLM 从文本中直接提取实体和关系。更灵活,能处理复杂的隐式关系,但成本更高且结果可能不一致。
混合方法:先用 NLP 管线做初步抽取,再用 LLM 处理复杂情况。兼顾成本和质量。
12.3.4 知识图谱的维护
随着交互积累,知识图谱需要持续维护:
- 冲突检测:新知识可能与已有知识矛盾(如"张三的编程语言从 Python 改为 Go")。系统需要检测冲突并决定更新策略。
- 去重合并:不同对话中提到的同一实体需要识别和合并(实体对齐问题)。
- 关系推理:基于已有关系推导新关系。如果"张三是开发者"且"开发者使用编程语言",则可推导"张三使用编程语言"。
12.4 感知记忆(Perceptual Memory)
12.4.1 设计目标
感知记忆处理多模态信息——图像、音频、视频等非文本数据。在多模态智能体中,用户可能发送图片请求分析、语音消息需要理解、或需要智能体处理视频内容。感知记忆为这些多模态数据提供存储和检索能力。
12.4.2 存储架构
感知记忆同样采用双存储设计:
文件/文档存储(SQLite):存储原始多模态数据的元数据——文件路径、格式、大小、创建时间等结构化信息。原始文件本身可以存储在文件系统或对象存储中。
向量存储(Qdrant):存储多模态数据的向量嵌入。图像使用 CLIP 等模型生成嵌入,音频使用语音嵌入模型。这些嵌入使跨模态检索成为可能——可以用文本查询搜索相关图像。
12.4.3 跨模态检索
感知记忆的独特能力是跨模态检索——用一种模态的查询检索另一种模态的信息。例如:
- 文本 → 图像:搜索"上次用户发的那张架构图"
- 图像 → 文本:基于图像找到相关的文字描述和讨论
这依赖于将不同模态映射到共享的向量空间。CLIP 等模型就是为此设计的——将图像和文本嵌入到同一个空间中,使语义相似的跨模态内容在向量空间中距离接近。
架构解析 -- 深入分析主流架构
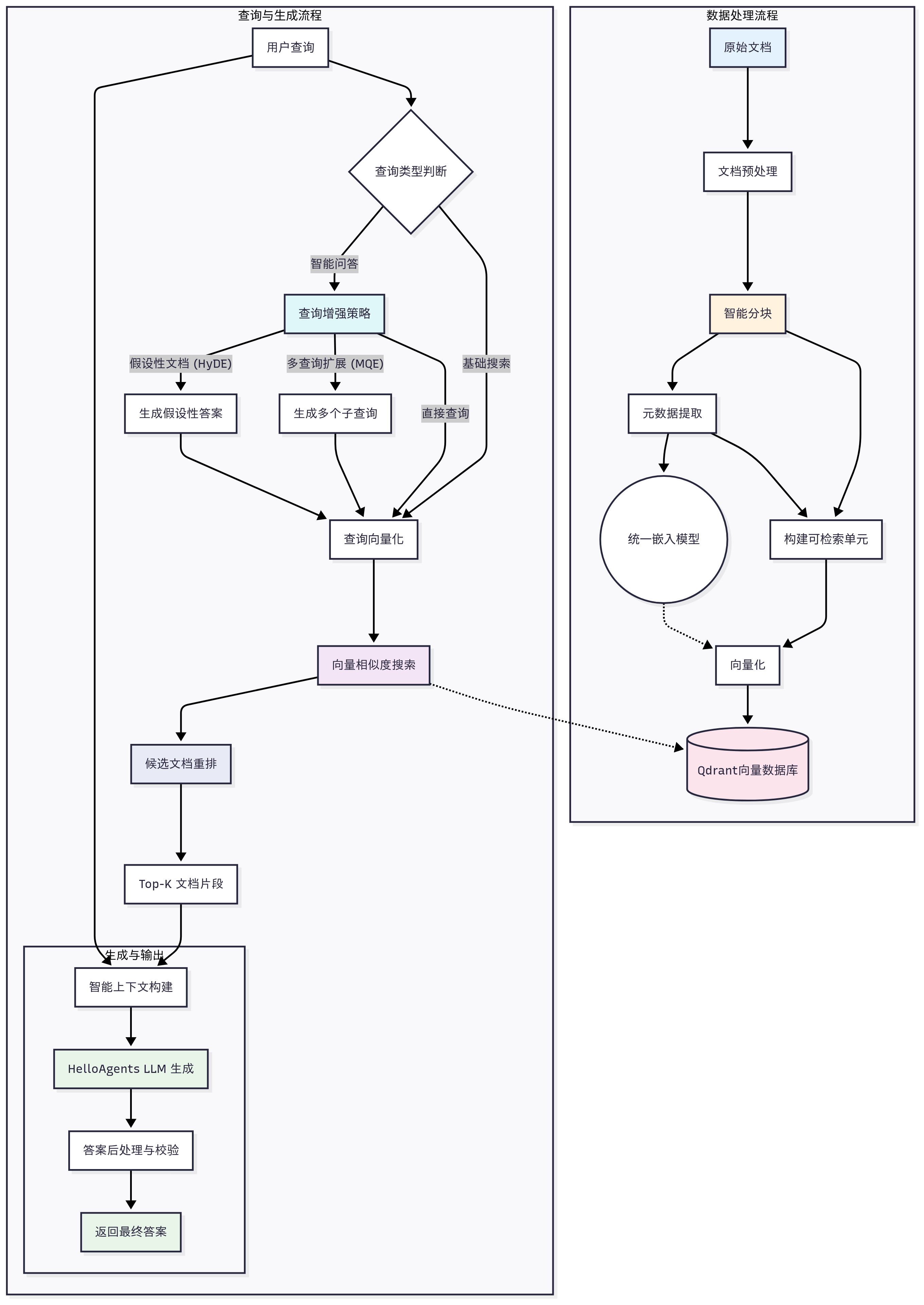
12.5 MemoryManager:统一调度架构
MemoryManager 是整个记忆系统的中枢,负责协调四种记忆类型之间的信息流。其核心架构:
用户输入/工具结果
↓
MemoryManager(统一入口)
↓ 分类路由
┌────┬────┬────┬────┐
│ WM │ EM │ SM │ PM │ ← 四种记忆类型
└──┬─┴──┬─┴──┬─┴──┬─┘
│ │ │ │
└────┴────┴────┘
↓
统一检索接口(跨类型搜索)
↓
结果融合与排序
↓
注入 LLM 上下文MemoryManager 的关键职责:
写入路由:根据信息类型和指定类别,将新记忆写入正确的记忆层。支持同一信息同时写入多个层——例如,一条重要的交互既写入情景记忆(作为事件记录),也提取知识写入语义记忆。
跨层检索:当查询不限定特定记忆类型时,MemoryManager 可以同时搜索多个记忆层并融合结果。融合策略包括简单拼接、加权排序和去重合并。
整合调度:定期或在特定事件触发时,执行工作记忆到长期记忆的整合。从工作记忆中提取满足条件(重要性阈值、出现频率)的信息,写入情景记忆或语义记忆。
健康监控:监控各存储后端的连接状态和容量使用,确保记忆系统的可靠性。
12.6 Session 生命周期管理
在 ADK 模型中,Session 是记忆管理的核心单元。一个典型的 Session 生命周期:
- 创建:用户发起对话,SessionService 创建新 Session,初始化 State
- 消息循环:每轮交互中,Runner 从 Session 获取上下文,Agent 处理并生成响应,新的 Event 被追加到 Session
- State 更新:Agent 在处理过程中可以通过工具回调或 output_key 机制更新 State
- 记忆迁移:在会话过程中或结束时,重要信息从 Session(短期)迁移到 Memory(长期)
- 终止:会话结束,Session 数据根据配置保留或删除
这个生命周期体现了认知科学中从工作记忆到长期记忆的信息流转模型。
关键实现决策 -- 工程实践中的关键选择点
12.7 嵌入(Embedding)服务的选择
嵌入服务是记忆系统的"编码器"——它决定了信息如何被表示和检索。选择维度:
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 云端 API(如 DashScope) | 高质量嵌入、无需本地 GPU | 网络依赖、API 成本 | 生产环境 |
| 本地模型(如 MiniLM) | 离线可用、无 API 成本 | 质量可能略低、需要 GPU/CPU 资源 | 隐私敏感场景 |
| TF-IDF | 极轻量、无模型依赖 | 仅表面词汇匹配 | 资源极度受限的兜底方案 |
实践建议是云端 API 为主、本地模型为备。生产环境使用高质量的云端嵌入确保检索准确度,同时配置本地模型作为 API 不可用时的降级方案。
12.8 向量维度与距离度量
向量维度影响表达能力和存储/计算成本:
- 384 维(MiniLM-L6):轻量,适合资源受限场景
- 768 维(BERT-base):中等,平衡质量和成本
- 1024+ 维(大型嵌入模型):高质量,适合对检索精度要求高的场景
距离度量的选择:
- 余弦距离(Cosine):最常用,对向量长度不敏感,适合文本语义相似度
- 欧氏距离(Euclidean):对绝对位置敏感,适合需要考虑"距离远近"的场景
- 点积(Dot Product):在归一化向量上等价于余弦距离,计算最快
默认推荐余弦距离 + 与嵌入模型匹配的维度。
12.9 记忆系统的一致性保证
双存储架构(结构化 + 向量)引入了一致性挑战——如果向量存储写入成功但结构化存储失败,系统处于不一致状态。应对策略:
- 事务性写入:尽可能在一个事务中完成两个存储的写入。SQLite 支持事务,但向量数据库可能不支持。
- 补偿操作:如果后续写入失败,回滚前面的写入。实现复杂但确保强一致性。
- 最终一致性:接受短暂的不一致,通过后台同步任务修复。实现简单,适合对一致性要求不严格的场景。
对于大多数智能体应用,最终一致性是合理的默认选择——记忆系统偶尔的不一致不会导致严重后果。
12.10 性能优化
记忆系统的性能直接影响智能体的响应速度:
- 工作记忆:纯内存操作,性能不是瓶颈
- 情景/语义记忆检索:向量搜索的延迟取决于数据规模和索引配置。Qdrant 支持 HNSW 索引,在百万级数据量上可实现毫秒级搜索
- 知识图谱查询:Neo4j 的查询性能取决于图的规模和查询的跳数。深度遍历(3 跳以上)可能带来显著延迟
- 批量嵌入:将多条记忆的嵌入请求合并为一次批量调用,减少 API 调用次数
前沿动态 -- 学术界/工业界最新进展
12.11 动态记忆架构
传统的四层记忆架构是静态的——类型和边界在设计时确定。MemGPT [Packer et al., 2023] 通过虚拟内存管理机制(类似操作系统的分页),让LLM智能体能够管理远超上下文窗口限制的记忆,在多会话对话中实现了显著的一致性提升。前沿研究探索动态记忆架构,其中记忆类型的数量和性质可以根据任务需要自动调整。例如,对于需要大量时间推理的任务,系统可能自动创建一个专门的"时间线记忆"层。
12.12 记忆的联邦学习
在多用户场景中,不同用户的记忆可以在保护隐私的前提下共同改进检索质量。例如,多个用户对同一领域的提问可以用于优化该领域的嵌入表示,而无需共享具体的交互内容。
本章小结
本章详细设计了四种记忆类型的架构。工作记忆以纯内存实现为核心,通过 TTL 管理和溢出策略在有限空间中保持最相关信息。情景记忆采用 SQLite + Qdrant 双存储,结合时间加权的语义检索,为智能体提供"自传式"的交互历史。语义记忆采用 Qdrant + Neo4j 双存储,兼具语义搜索和关系推理能力,构建智能体的知识网络。感知记忆扩展多模态处理能力,通过共享向量空间实现跨模态检索。
MemoryManager 作为统一调度层,协调四种记忆类型之间的写入路由、跨层检索和整合迁移。Session 生命周期管理确保了短期记忆到长期记忆的有序流转。
⚠️ 已知局限:双存储架构(向量+结构化/图)在记忆规模超过百万级时面临显著的检索延迟和一致性挑战。向量检索的召回率在记忆条目增多时逐步下降——当记忆库超过10万条时,Top-10召回率通常从95%降至80%以下。此外,知识图谱的实体对齐问题(同一个人在不同对话中被识别为不同实体)在长时间运行的智能体中会导致语义记忆的碎片化和矛盾。
工程实践中的关键决策包括:嵌入服务的选择(云端 API 为主、本地为备)、向量维度与距离度量的配置(余弦距离为默认)、双存储架构的一致性策略(最终一致性为合理默认)、以及各层记忆的性能优化策略。下一章将进一步讨论存储后端的技术细节和 RAG 系统的工程实践。