第4章 ReAct——推理与行动的统一
本章来源:综合自 Hello-Agents/chapter4(ReAct范式构建)、ce101(上下文驱动的推理机制)
核心问题 —— 本章要解答什么
当智能体需要与外部世界交互来完成任务时,它面临一个根本性的选择:是先想清楚再行动,还是边想边做?ReAct(Reason + Act)选择了后者——将推理与行动紧密交织在同一个循环中,形成"思考-行动-观察"的动态反馈回路。本章聚焦以下关键问题:
- 纯推理(Chain of Thought)和纯行动(Direct Action)各自的缺陷是什么?ReAct如何通过两者的融合来弥补?
- Thought-Action-Observation循环的形式化定义是什么?它的信息流如何运作?
- 在工程实现中,提示词模板设计、输出解析器、工具执行器和安全边界分别扮演什么角色?
- ReAct范式的能力边界在哪里?它在什么场景下会失效?
设计空间 —— 可选方案与取舍
| 维度 | 取值范围 | 设计考量 |
|---|---|---|
| 推理-行动耦合度 | 完全融合(ReAct) ↔ 完全解耦(Plan-and-Solve) | 融合提供实时纠错能力但缺乏全局规划;解耦提供全局视野但对执行中的意外适应性弱 |
| 工具调用格式 | 自然语言解析 ↔ 结构化JSON | 自然语言灵活但解析不稳定;JSON精确但要求模型严格遵循格式 |
| 循环终止条件 | 最大步数限制 ↔ 模型自主判断 ↔ 外部验证 | 最大步数是安全兜底;自主判断依赖模型能力;外部验证最可靠但增加复杂度 |
| 历史管理 | 全量追加 ↔ 滑动窗口 ↔ 摘要压缩 | 全量追加最忠实但消耗上下文;滑动窗口丢失远期信息;摘要压缩有信息损失风险 |
架构解析 —— ReAct的核心机制
4.3.1 从"纯思考"到"思行合一"
在ReAct诞生之前,处理复杂任务的方法分为两个阵营:
"纯思考"型(Chain of Thought):引导模型生成中间推理步骤,显著提升了复杂推理任务的准确率。但CoT无法与外部世界交互——它只能在模型已有的知识范围内推理。面对需要实时信息、精确计算或API调用的任务,CoT会因缺乏事实依据而产生幻觉。
"纯行动"型(Direct Action):模型直接输出要执行的动作,不展示推理过程。这种方式虽然可以与工具交互,但缺乏规划和纠错能力——模型不知道为什么要调用某个工具,也无法根据结果调整策略。
ReAct [Yao et al., 2023] 的核心洞察是:思考与行动是相辅相成的。 思考指导行动的方向性和目的性,行动的结果(观察)又为下一轮思考提供事实依据。这种交织形成了一个自我纠正的反馈回路。在HotpotQA多跳问答基准上,ReAct相比纯CoT方法将成功率从33.4%提升至35.1%,同时大幅减少了幻觉性错误(幻觉率从14.7%降至6.2%)。
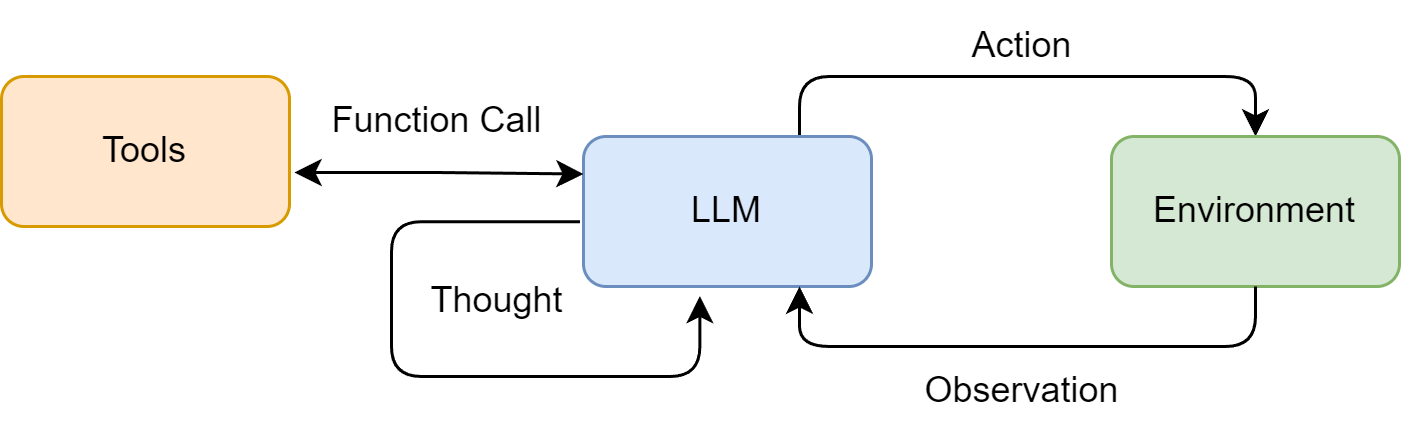
4.3.2 形式化定义与信息流
ReAct范式的核心是一个三元组循环:Thought → Action → Observation。
在每个时间步
然后环境中的工具
新的 Finish[answer]。
这个形式化揭示了ReAct的三个关键特性:
- 上下文累积性:历史轨迹不断增长,为模型提供越来越丰富的决策依据。这也意味着长时任务会面临上下文窗口的压力。
- 单步决策性:每次只决定下一步做什么,没有全局规划。这赋予了灵活性但可能导致局部最优。
- 工具中介性:智能体通过工具间接作用于世界,工具的设计和描述直接影响智能体的能力边界。
4.3.3 工程实现的四大支柱
将ReAct从理论转化为可运行的系统,需要四个关键的工程组件:
支柱一:提示词模板
提示词模板是ReAct机制的基石,它通过结构化的指令将LLM约束为一个循环决策系统。一个完善的模板需要包含:角色定义("你是一个有能力调用外部工具的智能助手")、工具清单及其描述(动态注入)、格式规约(强制Thought/Action的结构化输出)、以及动态上下文(问题和不断累积的交互历史)。
工具描述是整个机制中最关键的部分——LLM完全依赖描述文本来判断何时使用哪个工具。一个含糊的描述可能导致模型在错误的场景下调用工具,或完全忽略可用的工具。
支柱二:输出解析器
LLM返回的是纯文本,需要通过解析器从中精确提取Thought和Action。这通常通过正则表达式实现:先分离Thought和Action两个部分,再从Action字符串中提取工具名称和输入参数(如从 Search[华为最新手机] 中解析出工具名 Search 和输入 华为最新手机)。
解析器的鲁棒性直接决定了系统的可靠性。在实践中,LLM可能生成不完全符合格式的输出——多余的空格、缺失的方括号、使用了模板中未定义的动作名等。一个生产级的解析器需要处理这些边缘情况。
支柱三:工具执行器
工具执行器(ToolExecutor)负责管理和调度外部工具。它维护一个工具注册表,每个工具包含名称、描述和执行函数三个要素。当解析器提取出工具名和输入后,执行器查找并调用对应的函数,将返回值作为Observation反馈给模型。
工具执行器的设计应该是容错的:工具调用可能超时、返回异常或产生意外结果。一个健壮的执行器应该捕获这些异常并将错误信息转化为模型可理解的Observation,而非让整个循环崩溃。
支柱四:安全边界
max_steps 参数是ReAct循环中不可或缺的安全阀。它防止智能体在遇到无法解决的问题时陷入无限循环——不断重复相同的搜索、在错误的推理路径上越陷越深。典型值为5-10步,可根据任务复杂度调整。
4.3.4 一次完整的ReAct执行轨迹
以"华为最新的手机是哪一款?它的主要卖点是什么?"为例,一次典型的执行轨迹如下:
第1步:
- Thought:这个问题需要最新的产品信息,超出了我的知识范围,需要使用搜索工具。
- Action:
Search[华为最新手机型号及主要卖点] - Observation:(返回搜索结果摘要,包含Mate 70、Pura 80 Pro+等信息)
第2步:
- Thought:根据搜索结果,华为最新旗舰包括Mate 70和Pura 80 Pro+。我可以从结果中提取它们的主要卖点来给出答案。
- Action:
Finish[华为最新手机包括HUAWEI Pura 80 Pro+和HUAWEI Mate 70。Mate 70主打顶级拍照配置和全焦段覆盖;Pura 80 Pro+强调先锋影像技术。]
这个轨迹展示了ReAct的核心价值:模型先认识到自身知识不足(Thought),然后主动获取外部信息(Action),最后基于事实依据做出总结(Finish)。
关键实现决策 —— ReAct的工程化选择
决策一:提示词格式的选择——自然语言 vs 结构化
ReAct的经典实现使用自然语言格式(ToolName[input]),这种方式对LLM友好但解析脆弱。替代方案是要求LLM输出JSON格式的工具调用:
{"tool": "Search", "input": "华为最新手机"}JSON格式解析更稳定,但对模型的格式遵循能力要求更高。现代LLM(如GPT-4、Claude 3.5)已经能稳定输出JSON,因此在生产系统中推荐使用结构化格式。许多框架(如OpenAI的Function Calling)直接在API层面支持结构化工具调用,绕过了文本解析的问题。
决策二:历史管理策略
随着循环步数增加,历史轨迹会消耗越来越多的上下文窗口。三种策略各有取舍:
- 全量追加:最忠实地保留所有信息,适用于步数少(<5步)的任务。
- 滑动窗口:只保留最近N步的历史,丢弃较早的步骤。适用于较长的任务链,但可能丢失关键的早期观察。
- 摘要压缩:定期将历史压缩为摘要。保留了关键信息但引入了信息损失风险。
决策三:错误恢复机制
当工具调用失败或模型输出无法解析时,系统应如何恢复?常见策略包括:将错误信息作为Observation返回给模型,让它自主调整(最常用);重试同一步骤但修改提示(如追加"请严格遵循格式");跳过当前步骤并在下一轮明确告知模型上一步失败的原因。
前沿动态 —— ReAct的演进
趋势一:从文本ReAct到原生工具调用
现代LLM API(OpenAI Function Calling、Anthropic Tool Use等)已经将工具调用内置到模型的推理过程中,不再需要通过提示词格式约束来实现。这本质上是ReAct范式在API层面的原生化——模型的Thought是内部推理过程(可能不对外暴露),Action是结构化的工具调用请求,Observation是工具返回的结果。
趋势二:多工具协同与工具发现
早期ReAct通常只配备少量预定义工具。前沿方向是让智能体具备工具发现能力——根据任务需求动态搜索和加载合适的工具(如通过MCP协议连接外部工具服务)。这将ReAct从"固定工具集"扩展到"开放工具生态"。
趋势三:与其他范式的融合
ReAct正在与Plan-and-Solve、Reflection等范式融合。例如,先用Plan-and-Solve做全局规划,再用ReAct执行每个计划步骤;或在ReAct循环的关键节点加入Reflection进行自我审查。这种混合架构结合了不同范式的优势。
本章小结
ReAct范式通过将推理和行动融合在同一个循环中,为智能体提供了与外部世界交互的基本能力框架:
- 核心机制:Thought-Action-Observation三元组循环,推理指导行动、行动反馈推理,形成自我纠正的闭环。
- 工程实现:提示词模板、输出解析器、工具执行器和安全边界四大支柱共同支撑系统的可靠运行。
- 能力边界:ReAct高度依赖LLM的推理和格式遵循能力;串行循环带来效率问题;缺乏全局规划可能导致局部最优;提示词的脆弱性增加了系统的不确定性。
⚠️ 已知局限:ReAct在需要超过7-8步推理的长链条任务中表现显著下降,因为错误会在循环中累积传播。此外,当可用工具的描述不够精确或工具间功能存在重叠时,模型容易反复在错误的工具之间摇摆,消耗步数却无法推进任务。在FEVER事实核查基准上,ReAct对于需要复杂跨文档推理的样本仍有约40%的失败率。
ReAct的"边走边看"模式赋予了灵活性,但也牺牲了前瞻性。当任务的结构性更强、需要全局视野时,我们需要一种不同的策略——先规划,后执行。这正是下一章Plan-and-Solve要解决的问题。