第14章 RAG核心技术:分块、嵌入与索引
本章来源:综合自 Practical-Guide-to-Context-Engineering(RAG管道工程细节)、Hello-Agents 第八章(记忆与检索的系统架构)、agentic-design-patterns 第14章(RAG模式全景)
核心问题 —— 本章要解答什么
大语言模型的知识边界由训练数据决定,这意味着它无法获取训练截止日期之后的信息、企业内部数据或高度专业化的领域知识。检索增强生成(Retrieval-Augmented Generation, RAG)[Lewis et al., 2020] 正是为突破这一局限而设计的:在模型生成响应之前,先从外部知识库中检索相关信息,将其注入上下文,使模型的输出既有流畅性,又有事实根基。
RAG管道由三个核心环节构成:分块(Chunking)、嵌入(Embedding)、索引与检索(Indexing & Retrieval)。本章的核心问题是:在这三个环节中,各自存在哪些设计选择?不同选择带来怎样的精度—效率权衡?如何为具体场景做出合理决策?
设计空间 —— 可选方案与取舍
分块策略的设计空间
分块是RAG管道的第一步,其目标是将大型文档分解为更小的、语义自洽的片段。分块质量直接决定了后续检索的精度上限——分块过大,语义模糊,检索精度下降;分块过小,丧失上下文,模型推理质量受限。
核心取舍在于:分块要足够长,能让大模型在推理时有足够的上下文;同时分块又要足够具体,以便生成的向量能更准确地表达语义,从而使搜索更高效。
可选的分块策略包括:
| 策略 | 原理 | 适用场景 | 局限 |
|---|---|---|---|
| 固定长度分块 | 按字符数/token数切分 | 结构均匀的文本 | 可能在语义中间截断 |
| 基于分隔符分块 | 按段落/章节/标题切分 | 结构化文档(Markdown、HTML) | 依赖文档格式质量 |
| 语义分块 | 用嵌入模型检测语义边界 | 非结构化长文本 | 计算成本高 |
| 递归分块 | 多级分隔符逐层切分 | 通用场景 | 需要调参 |
嵌入模型的设计空间
嵌入模型将文本块转换为高维向量,是RAG管道中"语义理解"的载体。选择嵌入模型需要在以下维度间权衡:
- 向量维度:维度过低会导致语义丢失,维度过高增加存储和计算成本
- 语言覆盖:确保模型支持目标文本的语言
- 最大token长度:不同嵌入模型能处理的最大token数差异显著(如 Qwen3-Embedding-8B 支持32k,BAAI/bge-m3 支持8k)
- 速度与精度:大参数模型精度更高但推理更慢
索引架构的设计空间
索引架构决定了"如何组织向量以实现高效检索",选择空间包括:
- 平面索引:暴力搜索,精度最高但速度最慢
- ANN索引(近似最近邻):包括IVF聚类、树结构(Annoy)、图结构(HNSW),在速度和精度间取舍
- 分层索引:先粗筛再细筛,适合大规模文档集
- 混合索引:向量索引 + 倒排索引(关键词),兼顾语义和词汇匹配
架构解析 —— 深入分析RAG核心管道
14.1 RAG管道全景
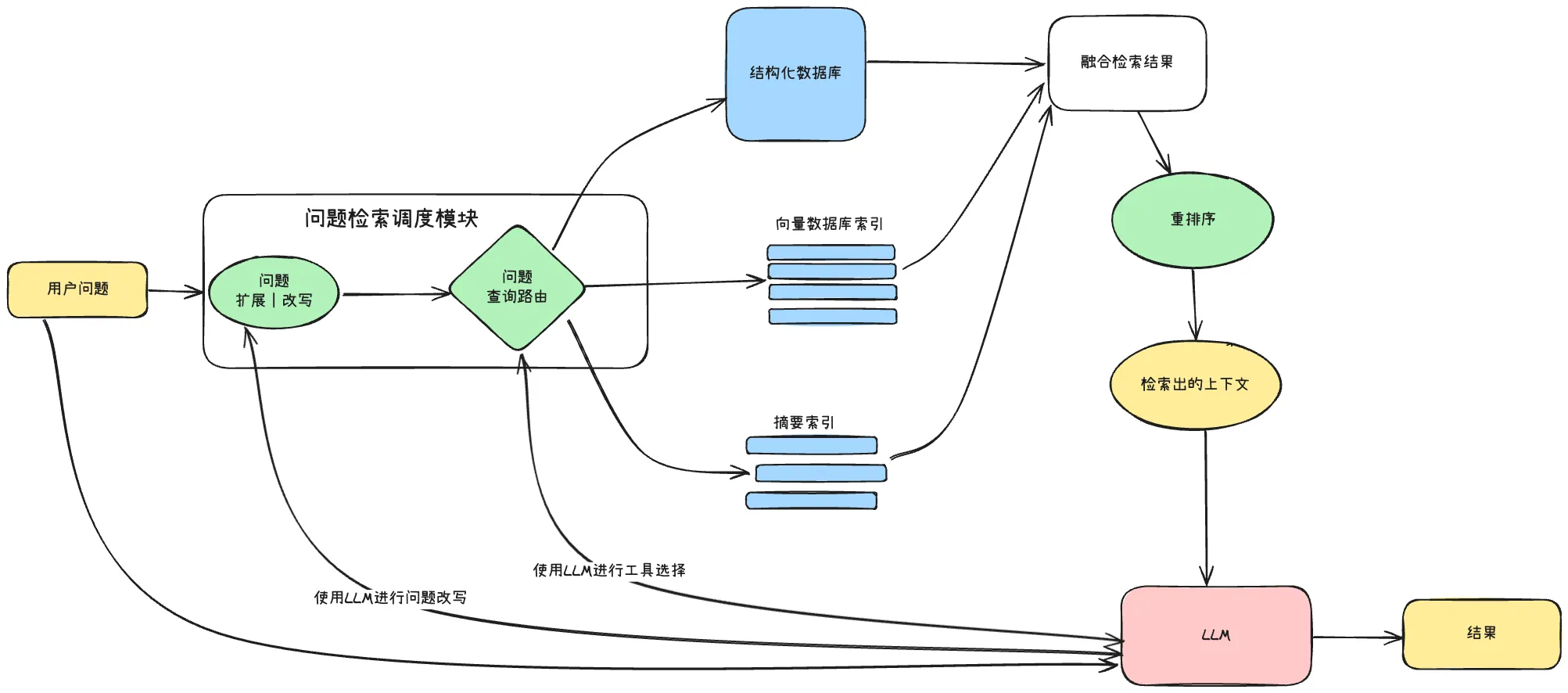
RAG的基本流程可以概括为四步:将文本分割成块,使用Transformer编码器模型将这些块嵌入到向量中,将所有向量放入索引中,最后为LLM创建一个提示,告诉模型根据检索到的上下文来回答用户的查询。
这个流程看似简单,但每一步都蕴含着丰富的工程决策。当用户发出查询时,系统不是直接将查询发送给LLM,而是先在外部知识库中执行语义搜索——这种搜索不是简单的关键字匹配,而是理解用户意图和词语背后含义的"智能搜索"。检索到的信息片段被增强到原始提示中,形成一个更丰富的查询,最终送入LLM。
RAG框架的核心优势包括:
- 突破知识时效性限制:允许LLM访问最新信息
- 减少幻觉风险:将响应建立在可验证的数据上
- 支持专业领域知识:利用内部文档或专业知识库
- 提供引用溯源:明确指出信息来源,增强可信度
14.2 分块策略深度解析
14.2.1 分块粒度的权衡
分块大小的选择需要综合考虑嵌入模型的最大token长度和下游任务的需求。过大的分块会导致向量表示过于泛化,难以精确匹配查询意图;过小的分块则可能丢失上下文,使LLM无法基于检索结果进行有效推理。
实践中的经验法则是:检索阶段使用较小的分块以提升精度,但在提供给LLM时补充周围的上下文,以确保推理质量。这一思想催生了两种重要的上下文增强技术。
14.2.2 句子扩展(Sentence Window)

句子扩展的核心思路是:检索时保持足够小的文档块,在输入给LLM之前进行上下文的扩展和增强。
具体而言,当检索到一个较小的片段时,系统会自动获取该片段的上下两个相邻片段,组合成一个完整的上下文块输入给LLM。例如,如果检索命中了"苹果可能降低心脏病的风险"这句话,系统会同时提供前后两句,使模型能够输出更完整的回答:"苹果不仅能增强免疫系统,还能降低心脏病风险。研究显示,经常吃苹果的人往往更长寿。"
14.2.3 父文档检索(Parent Document Retrieval)
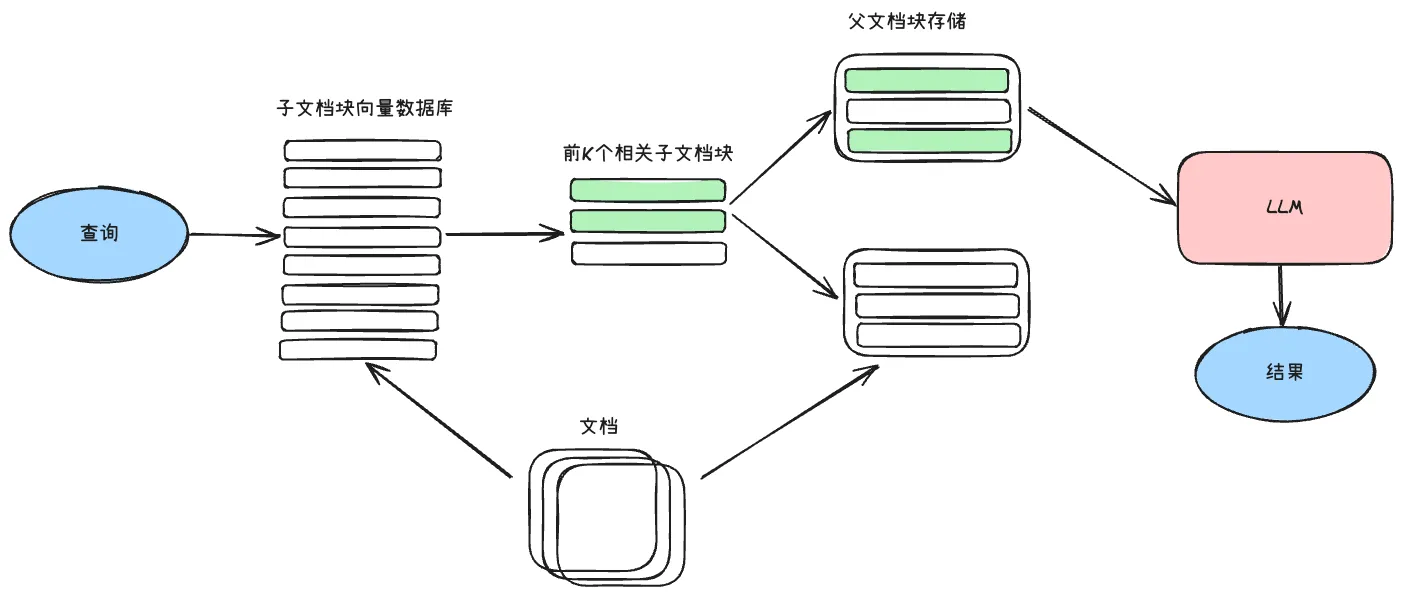
父文档检索将文档分割为分层结构:
- 子文档块:更小的片段,承担检索任务
- 父文档块:更大的片段,与子文档通过映射关系关联,决定最终输入给LLM的上下文
查询流程如下:
- 根据查询检索子文档块的向量数据库(更小的块有利于精准检索)
- 得到前k个相关的子文档块
- 由前k个子文档块查找或合并它们对应的父文档块
- 将整理出的父文档块输入给LLM,生成最终答案
这种方法与句子扩展的思路一致——小块检索、大块推理——但通过显式的父子层级关系实现了更灵活的粒度控制。
14.3 嵌入与向量化
14.3.1 从文本到向量
嵌入是将文本转换为机器可处理的数值表示的过程。一句话或一个段落被输入到嵌入模型后,模型输出一个固定维度的数字数组(如 [0.12, -0.53, 0.88, ...]),这个数组就是向量。
向量的本质是高维空间中的坐标。语义相似的文本在向量空间中会彼此靠近——"cat"和"kitten"的向量距离很近,而"cat"和"car"的向量距离很远。这种特性使得向量搜索可以基于含义而非关键字来查找相关信息。
文本相似度的衡量有多个层次:
- 词汇相似度(Lexical Similarity):关注词汇重叠
- 语义相似度(Semantic Similarity):关注含义是否相同
- 语义距离(Semantic Distance):语义相似度的反面,距离越小越相似
在RAG中,语义搜索依赖于找到与用户查询语义距离最小的文档——即使用户的措辞与源文档完全不同,也能发现相关内容。
14.3.2 嵌入模型选型要素
MTEB(Massive Text Embedding Benchmark)[Muennighoff et al., 2023] 提供了嵌入模型的标准化评测框架,覆盖8类任务和58个数据集。选择嵌入模型时需要考虑:
- 向量维度:维度决定了语义表达的精细程度。常见维度从384(轻量级)到4096(高精度)不等
- 语言支持:多语言嵌入模型(如 BGE-M3)适合需要跨语言检索的场景
- 最大输入长度:决定了单个分块能有多大
- 推理效率:大规模知识库需要考虑嵌入生成的吞吐量
14.4 索引构建与检索
14.4.1 向量存储索引
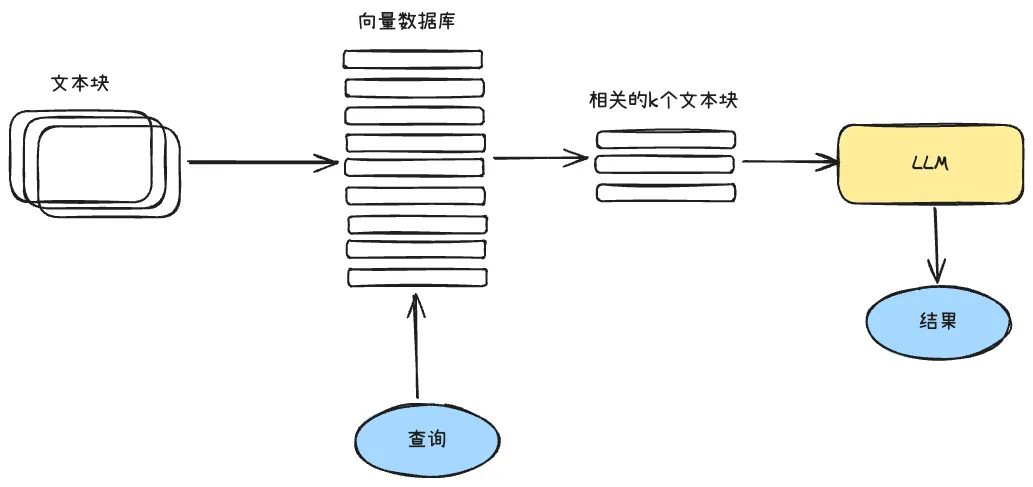
向量存储索引是RAG系统最基础的检索方式。查询时,用户的问题首先通过嵌入模型转换为向量,然后在向量数据库中查找最相似的前k个向量,最后通过向量ID映射回原始文本块。
向量数据库的实现形式多样:
- 托管服务:Pinecone、Weaviate
- 开源方案:Chroma DB、Milvus、Qdrant
- 现有数据库扩展:PostgreSQL(pgvector扩展)、Elasticsearch、Redis
- 底层检索库:FAISS(Meta AI)、ScaNN(Google Research)
ANN(近似最近邻)是向量索引的核心搜索策略,目标是在海量向量中快速找到最接近的候选,而不是逐一比对:
- IVF(聚类倒排):先把空间分块,缩小候选范围
- Annoy(树结构):用分割空间的树来加速查找
- HNSW(图结构):构建近邻图,贪心搜索路径找到候选
14.4.2 分层索引
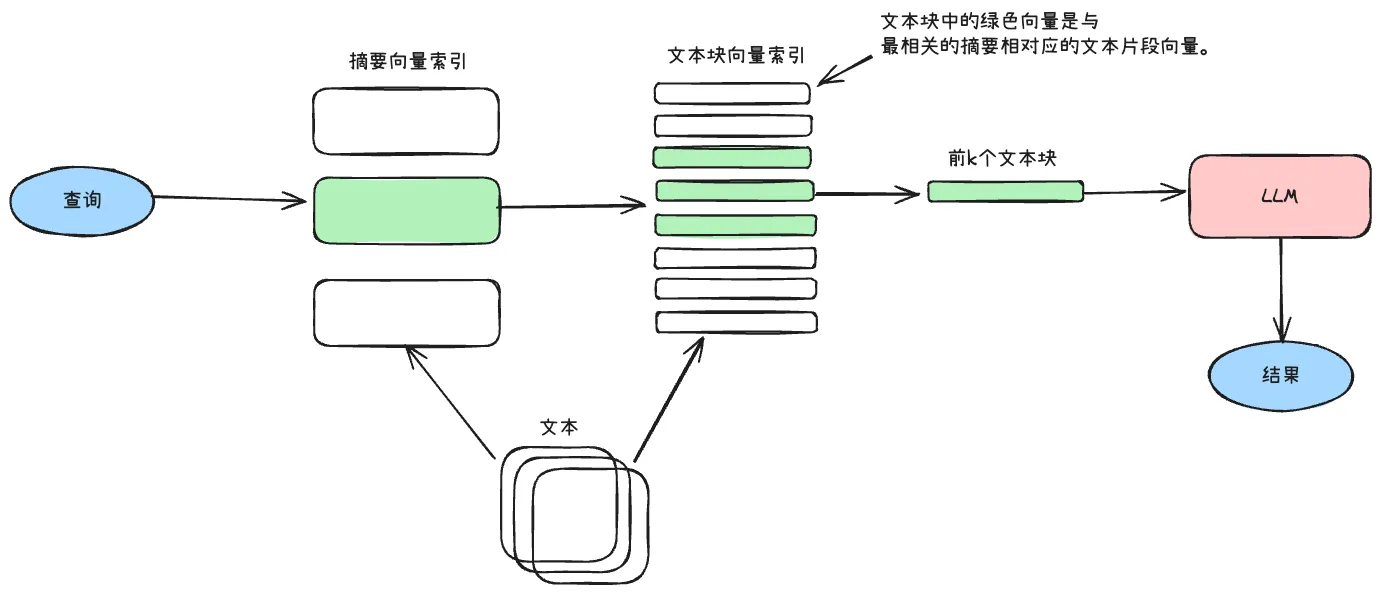
分层索引的核心思路是先大再小,先粗筛再细筛。系统创建两个索引:一个是"大文档"的摘要索引,一个是"小文档"的文本块索引。搜索时分两步:
- 先通过摘要索引过滤出相关的文档
- 只在这些相关文档内部进行片段级的检索
这种设计显著减少了搜索空间,特别适合大规模多文档知识库。
14.4.3 假设性问题与假设性文档
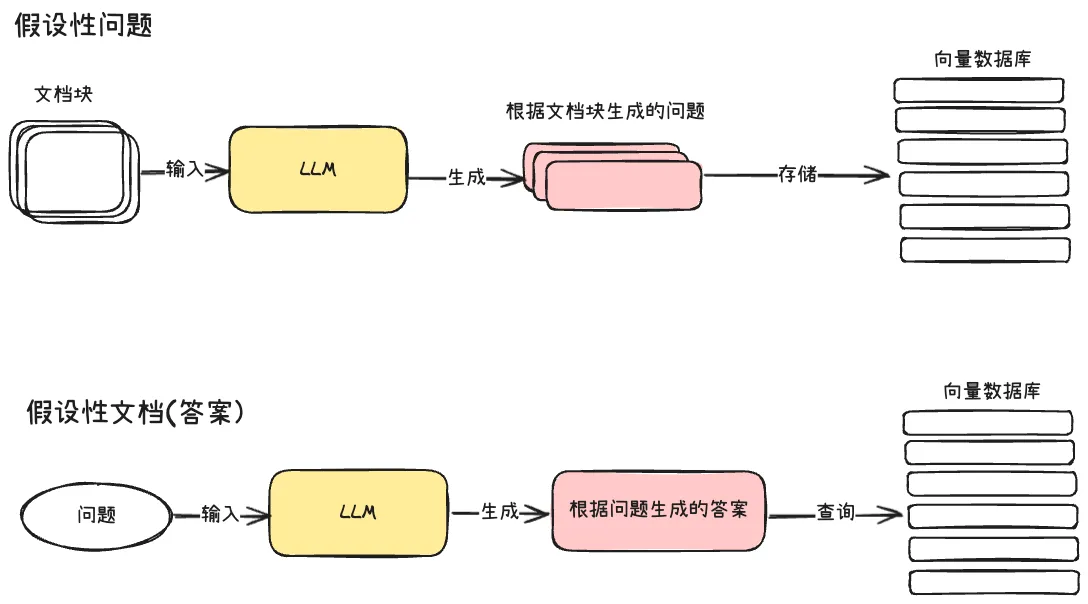
这是两种巧妙的索引增强技术:
假设性问题(Hypothetical Questions):对每个文档块,让LLM生成几个可能有人会问的问题,将这些问题向量化建立索引。检索时,用户的问题去检索"文档问题"向量库,命中后再找到对应的文档块。这种方法弥合了"用户提问方式"与"文档描述方式"之间的语义鸿沟。
假设性文档嵌入(HyDE):用户输入问题后,先用LLM生成一段假设性的答案文档,然后将这个"答案"拿去文档向量库中检索。由于LLM生成的答案在语言风格上与文档更接近,检索效果往往优于直接使用问题查询。
14.4.4 元数据增强
在存储向量的同时保存元数据,可以在两个层面提升检索效果:
- 附加语义信息:元数据作为向量查询的补充维度
- 过滤与限定:利用元数据过滤器限定检索范围(如按日期、来源、类别筛选)
关键实现决策 —— 工程实践中的关键选择点
14.5 查询优化技术
14.5.1 查询转换
![]()
查询转换通过LLM修改用户输入以提高检索质量。核心方法包括:
子查询分解:将复杂查询分解为多个简单子查询并行执行。例如"Langchain和LlamaIndex哪个在GitHub上的星标更多?"可以分解为两个独立的子查询,分别检索后合并结果。
Step-back Prompting:先让LLM生成一个更通用的查询,检索到更高层次的上下文作为语义基础,同时也执行原始查询的检索,最终合并两类上下文输入LLM推理。
查询重写(Query Re-writing):利用LLM对初始查询进行改写以提升检索效果——本质上是让LLM将用户的自然语言表达转换为更适合检索的形式。
14.5.2 查询路由
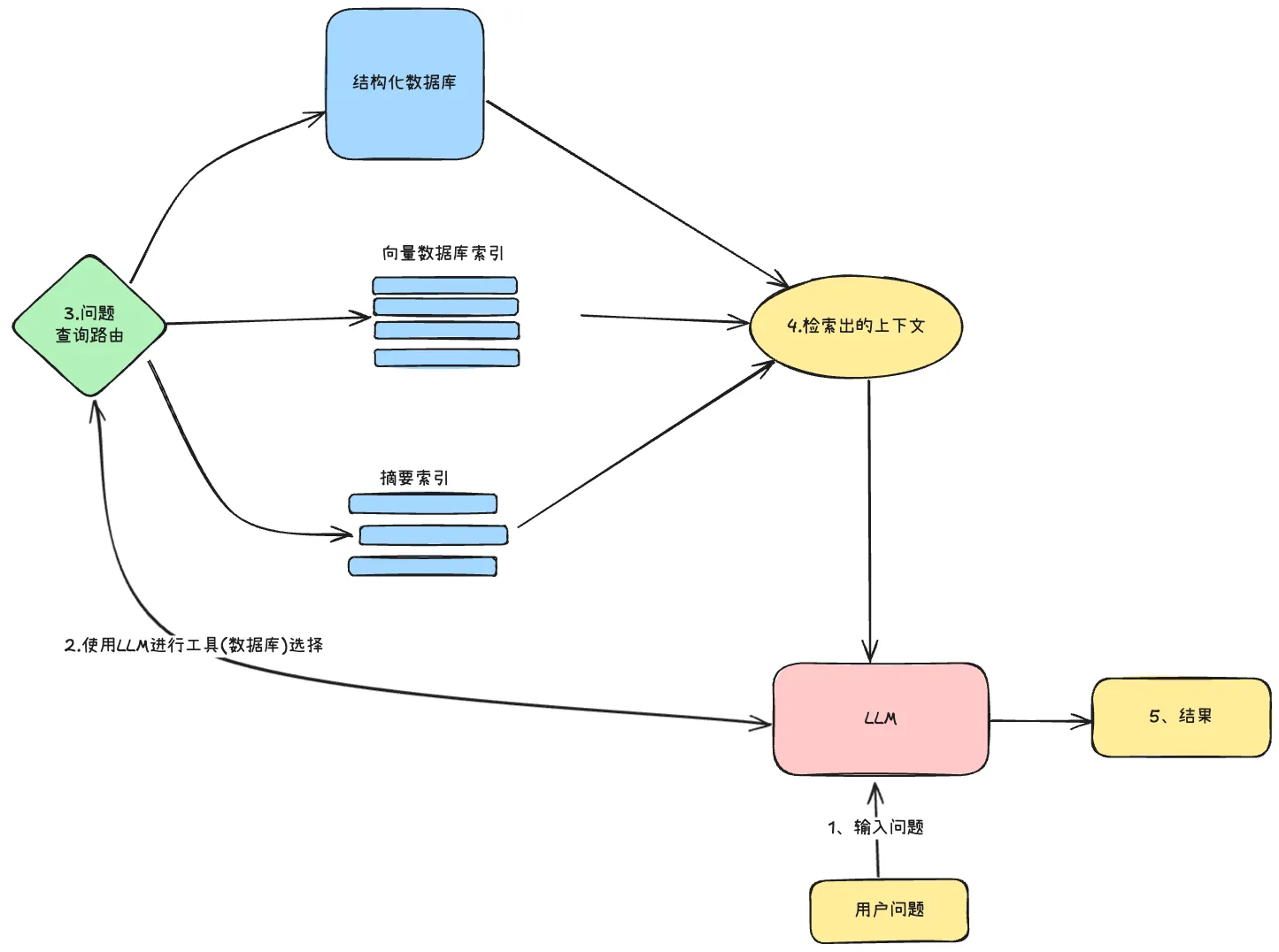
查询路由是一个由LLM驱动的决策步骤,根据用户查询决定使用哪种检索策略。可选的路由目标包括摘要索引、文档块索引、结构化数据库等。路由器还可以在不同的搜索策略(分层检索、句子扩展、父文档检索)之间选择。
查询路由最关键的设计决策是定义路由器的选择范围——也就是为路由器提供哪些搜索策略或搜索方式作为候选。
14.6 融合检索与混合搜索
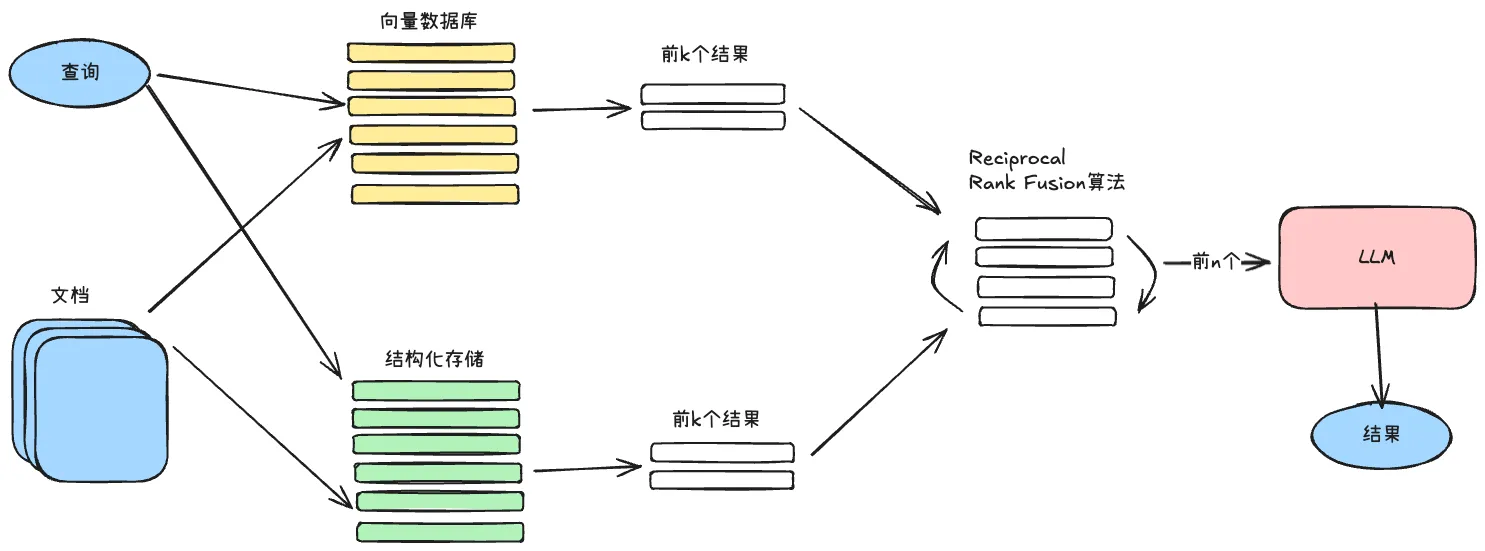
混合检索从两种不同的检索方式中汲取优点:
- 传统关键词搜索(BM25):基于词频的精确匹配,擅长处理专有名词、代码片段等
- 语义向量搜索:基于含义的模糊匹配,擅长理解同义表达和概念关联
混合检索的核心难点在于如何正确融合来自不同检索方式、相似度评分标准不同的结果。通常使用 Reciprocal Rank Fusion(RRF)算法对检索结果进行重新排序,生成统一的最终输出。
14.7 重排序与过滤
通过检索获得初步结果后,需要进一步优化。常见的策略包括:
- 相似度分数排序:取出前k个值
- 元数据过滤:根据时间、用户ID等数据进行过滤筛选
- LLM排序:将候选文本输入给LLM,让LLM判断最有效的排序
- 重排序模型(Re-ranker):使用专门的交叉编码器模型对结果进行细粒度排序
重排序模型通常采用交叉编码器架构,同时接收查询和候选文档作为输入,能够捕获更精细的语义交互信息,但计算成本也更高。实践中,常见的做法是先用双编码器(向量检索)做粗召回,再用交叉编码器做精排。
14.8 引用溯源
在LLM生成答案时标注信息来源,是增强答案可信度的关键机制。这种引用来源的方式为用户提供了一层"信息审核"机制。
实现方式包括:
- 提示词驱动:在提示词中要求LLM在答案中标注所使用来源的ID
- 后处理匹配:将LLM生成的响应与检索出的原始文本块进行匹配,自动添加引用
前沿动态 —— 学术界/工业界最新进展
静态RAG vs JIT RAG
工程实践正在从"推理前一次性检索"(静态RAG)向"及时上下文"(Just-in-time RAG)过渡。JIT RAG不再预先加载所有相关数据,而是维护轻量化引用(文件路径、存储查询、URL等),在运行时通过工具动态加载所需数据。这种模式更贴近人类的认知方式——我们不会死记硬背全部信息,而是用文件系统、书签等外部索引按需提取。
长上下文模型与RAG的关系
每次SOTA模型的上下文窗口增长,都会带来"RAG是否已死"的争论。但行业实践表明,长上下文模型并不是RAG的替代品,而是增强了RAG的效果。Databricks的研究显示,使用更长的上下文并不总能提升RAG的表现——小参数模型在上下文增长后准确率反而下降,即使是SOTA模型,效果提升也会趋于饱和。因此,最初的上下文带来的增量收益最好,在成本和效果之间的平衡点通常在中间偏左的区域。
RAG的挑战与局限
尽管功能强大,RAG模式面临几个未解决的挑战:
- 跨文档综合:当答案分散在多个文档中时,检索器可能无法收集所有必要的上下文
- 矛盾信息处理:有效综合来自潜在矛盾来源的信息仍然困难
- 知识库维护成本:需要将整个知识库预处理并存储在专门的数据库中,且需要定期更新
- 性能开销:增加延迟、运营成本和token消耗
本章小结
本章系统解析了RAG管道的三大核心环节。在分块策略上,关键取舍是检索精度与推理上下文之间的平衡,句子扩展和父文档检索提供了"小块检索、大块推理"的优雅解决方案。在嵌入选型上,向量维度、语言支持和最大输入长度是决定性因素。在索引架构上,分层索引、假设性问题/文档、混合检索等技术各自面向不同的检索场景。
查询优化(子查询分解、查询重写、查询路由)和结果优化(重排序、引用溯源)则从管道的输入端和输出端进一步提升了RAG系统的整体质量。最终,一个生产级的RAG系统需要将这些技术有机组合,并根据具体场景做出合理的工程决策。
⚠️ 已知局限:RAG管道的每个环节都可能引入误差,且误差会逐级传播。分块可能在关键语义边界处截断上下文;嵌入模型对否定句式(如"X不是Y")和复杂逻辑关系的编码质量较差;向量检索的近似最近邻算法在高维空间中存在"维度灾难",召回率随数据量增大而下降。一项大规模RAG评估 [Gao et al., 2024] 显示,即使是优化后的RAG系统,在需要多跳推理的问题上准确率仍不足50%。
下一章将探讨RAG的进阶形态——知识图谱增强的Graph RAG和混合检索策略,以及从被动检索到主动推理的Agentic RAG演进。