第10章 学习、适应与推理增强
本章来源:综合自 Agentic Design Patterns 第9章(学习与适应:SICA、AlphaEvolve、OpenEvolve)、第17章(推理技术:CoT、ToT、GoT、RLVR、ReAct)、Hello-Agents 第11章(Agentic RL:从 LLM 训练到强化学习智能体)
核心问题 -- 本章要解答什么
前面三章讨论的设计模式(流程控制、工具使用、运行时管理)都有一个共同前提:智能体的能力边界是由开发者在构建时设定的。prompt 写好了,工具注册了,流程编排了——智能体就在这个框架内工作。它可以应对预设范围内的各种情况,但无法突破自身的能力天花板。
本章讨论两个打破这一限制的方向:
学习与适应:智能体能否通过经验改进自身?不是被动地执行指令,而是从成功和失败中学习,修改自己的策略甚至代码,在迭代中变得越来越强。
推理增强:智能体能否在推理过程中投入更多计算资源来获得更好的结果?不是快速给出第一反应,而是像人类面对难题时那样——深思熟虑、分步推导、尝试多条路径、回溯修正。
这两个方向共同指向一个目标:让智能体从"执行预设程序"进化为"自主改进的智能系统"。
设计空间 -- 可选方案与取舍
10.1 学习与适应的方法论谱系
智能体的学习与适应涵盖一个广阔的方法论谱系:
| 学习方式 | 核心机制 | 典型场景 | 适用智能体类型 |
|---|---|---|---|
| 强化学习 | 试错 + 奖励信号 | 游戏、机器人控制 | 需要策略优化的智能体 |
| 监督学习 | 标注数据 + 损失函数 | 分类、预测 | 有明确标签的任务 |
| 少样本/零样本学习 | LLM 上下文学习 | 快速适应新任务 | 通用 LLM 智能体 |
| 在线学习 | 持续数据流 + 实时更新 | 实时推荐、欺诈检测 | 流数据处理智能体 |
| 基于记忆的学习 | 经验回放 + 相似匹配 | 个性化助手 | 有长期记忆的智能体 |
| 自我修改 | 修改自身代码/策略 | 编码智能体 | 具备代码执行能力的智能体 |
对于基于 LLM 的智能体系统,最具变革性的方向是自我修改和强化学习——前者让智能体直接改进自己的实现,后者通过奖励信号优化决策策略。
10.2 推理技术的设计空间
LLM 的推理能力可以通过多种技术增强,它们在计算成本和效果之间形成不同的权衡:
| 技术 | 核心思想 | 结构 | 计算开销 |
|---|---|---|---|
| Chain-of-Thought (CoT) | 逐步推导 | 线性链 | 低 |
| Tree-of-Thought (ToT) | 多路径探索 + 回溯 | 树形分支 | 中 |
| Graph-of-Debates (GoD) | 多智能体辩论 | 图网络 | 高 |
| ReAct | 推理与行动交替 | 循环 | 中 |
| RLVR | 可验证奖励训练推理链 | 训练时优化 | 训练高,推理中 |
| PALMs | 生成代码辅助推理 | 混合符号 | 低-中 |
一个关键原则贯穿所有这些技术:在推理时分配更多计算资源,可以换来更好的结果。这被称为推理扩展定律(Inference Scaling Law)。
架构解析 -- 深入分析主流架构
10.3 自我改进编码智能体(SICA)
SICA(Self-Improving Coding Agent)由 Maxime Robeyns、Laurence Aitchison 和 Martin Szummer 提出,展示了一个核心能力:智能体修改自身源代码以提升性能。
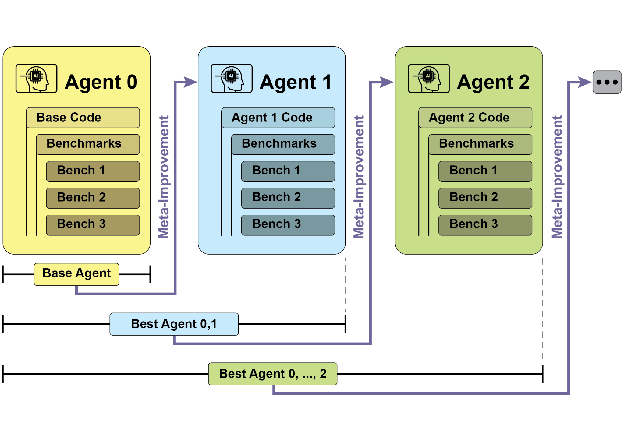
10.3.1 迭代自我改进循环
SICA 的自我改进遵循以下循环:
- 版本选择:审查历史版本档案及其基准测试表现,选择性能最高的版本作为当前基础
- 分析与修改:分析档案中的历史表现数据,识别改进机会,直接修改自身代码库
- 测试与记录:在基准测试上评估修改后的版本,将结果记入档案
- 迭代:重复上述循环
性能评分基于加权公式,综合考虑成功率、执行时间和计算成本。这确保了改进方向不仅追求正确性,还兼顾效率。
10.3.2 SICA 的演化轨迹
SICA 在实际运行中展现了从粗粒度操作向精细操作演进的自我改进能力——从基本的文件覆盖发展到基于 AST 解析的精确编辑,从全局搜索发展到混合符号定位。这一进化过程的详细分析参见第 28 章 28.3 节。
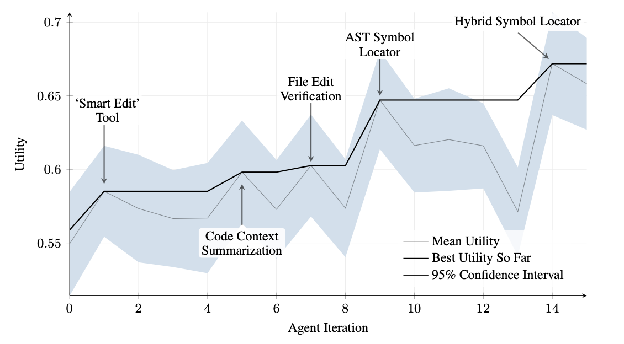
10.3.3 架构设计要点
SICA 的架构包含几个关键组件:
子智能体体系:主智能体可以调用编码智能体、问题解决智能体和推理智能体等子智能体。这种设计用于分解复杂任务和管理上下文长度。
异步监督者:一个独立运行的 LLM 并发监控 SICA 的行为,识别循环、停滞或低效模式。它接收 SICA 的调用图和事件日志,必要时可以介入终止执行。这是目标监控模式(第9章)在自我改进场景中的直接应用。
结构化上下文管理:SICA 在上下文窗口中维护结构化信息——系统提示词(目标和工具文档)、核心提示词(问题和文件内容)、助手消息(逐步推理和工具调用记录)。这种结构化组织是高效自我改进的前提。
安全隔离:SICA 运行在 Docker 容器中,与主机文件系统隔离。这对于能够执行 shell 命令并修改自身代码的智能体是必要的安全保障。
10.4 AlphaEvolve 与 OpenEvolve
10.4.1 AlphaEvolve:算法发现的进化框架
AlphaEvolve 是 Google 开发的 AI 智能体,通过 LLM 与进化算法的结合来发现和优化算法。其核心架构包含 LLM 集合(Flash 广度探索 + Pro 深度优化)、自动评估系统和进化算法框架。
AlphaEvolve 的成果涵盖基础研究(如发现新的矩阵乘法算法)和工程应用(如数据中心调度优化、GPU 内核加速),详细成果列表参见第 28 章 28.4 节。
10.4.2 OpenEvolve:开放的进化编码智能体
OpenEvolve 是一个开源实现,将进化优化思想应用于代码改进。其架构由控制器编排四个核心组件:
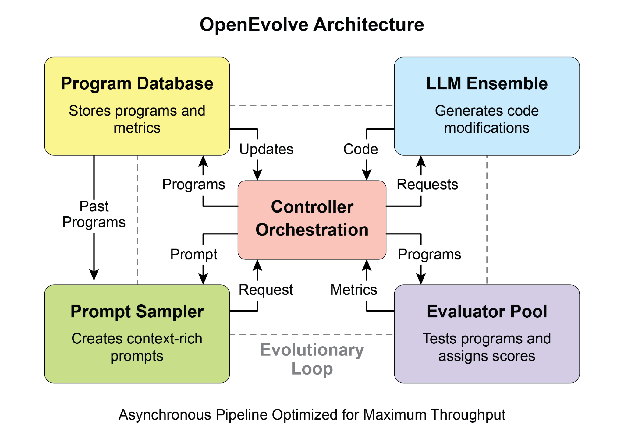
- 程序采样器:从种群中选择有潜力的程序进行变异
- 程序数据库:维护所有历史版本及其性能数据
- 评估器池:分布式评估变异后的程序
- LLM 集合:驱动代码生成和变异
OpenEvolve 相比 AlphaEvolve 的关键差异在于:能够进化完整代码文件(而非单一函数)、支持多编程语言、兼容任意 OpenAI 兼容 API、支持多目标优化。
10.5 推理技术深度解析
10.5.1 思维链(Chain-of-Thought)
CoT 是最基础也最广泛使用的推理增强技术。其核心思想是引导 LLM 在给出最终答案之前,显式生成中间推理步骤。
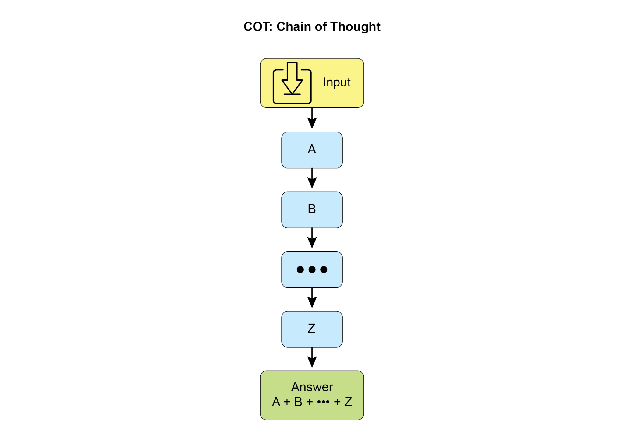
CoT 的两种实现方式:
- 少样本 CoT:在 prompt 中提供包含推理步骤的示例,模型模仿示例的推理模式
- 零样本 CoT:简单添加"Let's think step by step",激活模型内在的逐步推理能力
CoT [Wei et al., 2022] 有效的根本原因是它将困难的单步问题转化为多个简单步骤的序列。每一步的认知负荷降低,模型犯错的概率也相应降低。对于智能体系统,CoT 的另一个重要价值是可审计性——中间步骤使决策过程透明,便于调试和验证。
10.5.2 思维树(Tree-of-Thought)
ToT [Yao et al., 2023] 在 CoT 的基础上引入了分支和回溯。在24点游戏上,ToT 的成功率达到74%,而标准 CoT 仅为4%,展现了搜索机制对组合问题的巨大优势。当面对一个问题时,智能体不是沿单一路径推理,而是:
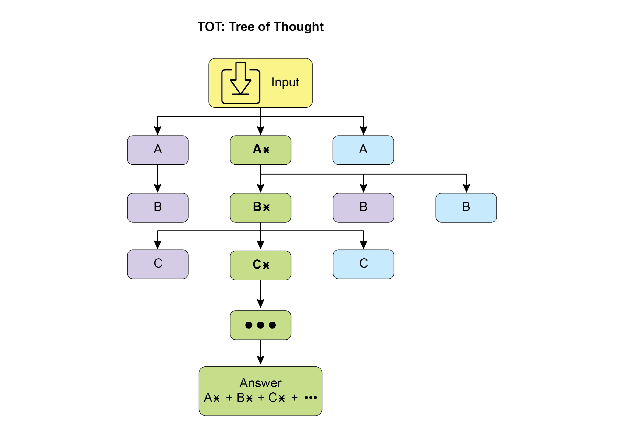
- 在每个决策点生成多个候选中间步骤
- 评估每个候选步骤的前景
- 选择最有前途的路径继续,或回溯到之前的分支点
ToT 特别适合需要战略规划和全局搜索的任务——如创意写作中的情节设计、数学证明中的策略选择。代价是计算量显著增加(每个分支点都需要多次 LLM 调用)。
10.5.3 辩论图(Graph-of-Debates)
GoD 将推理从单一智能体的独白扩展为多智能体的协作辩论。论点不是按线性链排列,而是形成图结构——节点代表论点,边代表"支持"或"反驳"关系。
结论不在序列末尾产生,而是通过识别图中最稳健和最受支持的论点簇来达成。"得到良好支持"的判定标准包括:已确立的事实、通过搜索验证的证据、以及多个模型在辩论中达成的共识。
GoD 的一个变体是微软提出的辩论链(Chain of Debates, CoD),多个不同模型像"AI 委员会"一样协作——提出想法、互相质疑、交换反驳——通过集体智慧减少偏见并提高最终答案的可靠性。
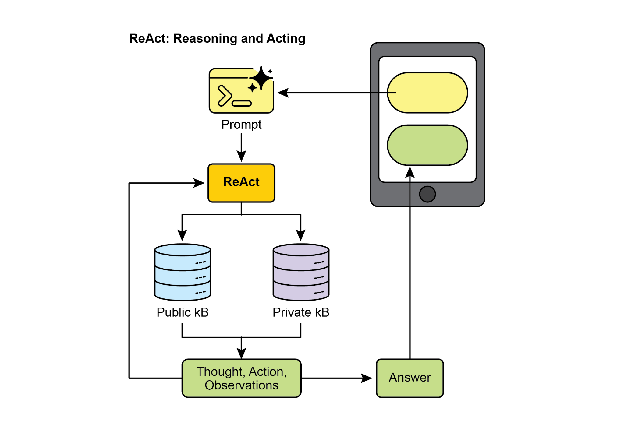
10.5.4 ReAct:推理与行动的交替
ReAct 将 CoT 推理与工具使用结合为统一范式。智能体在"思考-行动-观察"的循环中工作:
- Thought(思考):分析当前状态,规划下一步行动
- Action(行动):执行工具调用或函数调用
- Observation(观察):接收执行结果
- 基于观察结果更新思考,重复循环
ReAct 相比纯 CoT 的关键优势是动态适应性——智能体不是在开始时一次性规划所有步骤,而是根据每次行动的实际结果动态调整策略。这使得 ReAct 特别适合需要与外部环境持续交互的任务。
10.5.5 程序辅助语言模型(PALMs)
PALMs 将 LLM 的语言理解能力与确定性编程环境的精确计算能力结合。当面对需要精确计算的问题时,LLM 不是直接"算"答案,而是生成代码来计算,然后将代码执行结果转换为自然语言回答。
这种混合策略利用了各自的优势:LLM 擅长理解问题和生成解题思路,代码执行器擅长精确计算和逻辑操作。对于数学、数据分析等精确计算密集的任务,PALMs 显著提高了结果的可靠性。
10.6 Agentic RL:从训练到部署
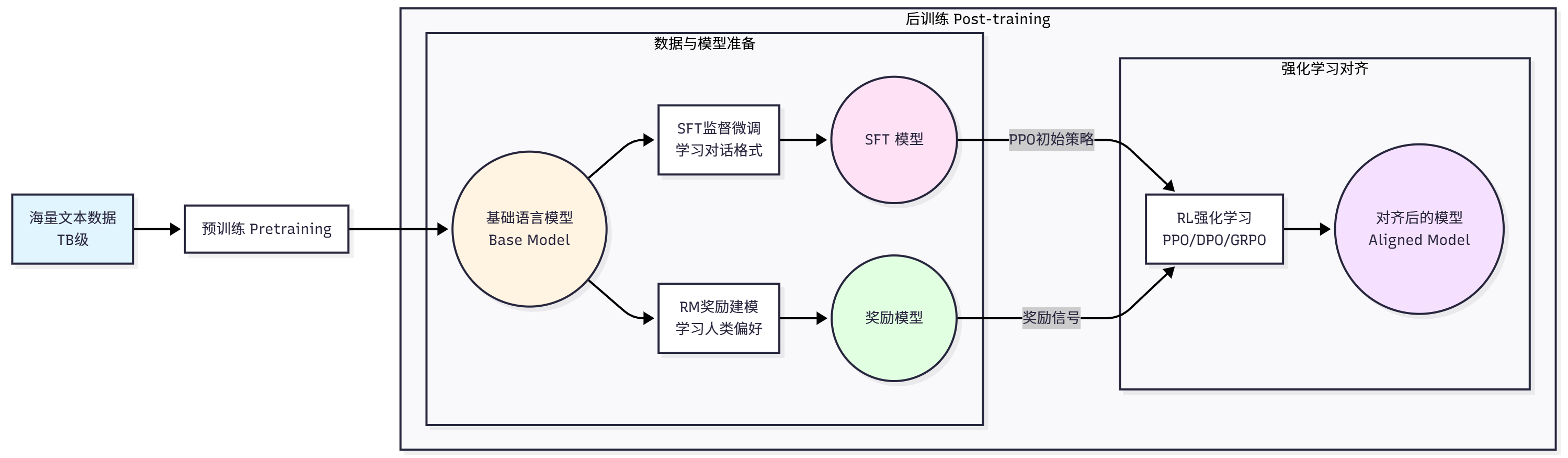
10.6.1 LLM 训练的全景
理解 Agentic RL 需要先理解 LLM 训练的完整流程:
预训练阶段:在 TB 级文本数据上进行下一个词预测,学习语言规律和世界知识。目标函数:
后训练阶段包含三步:
- 监督微调(SFT):在(prompt, completion)对上训练,让模型学会遵循指令和对话格式
- 奖励建模(RM):训练独立模型预测人类偏好,用偏好对比数据学习评估回答质量
- 强化学习微调:用 PPO 或 DPO 等算法优化模型,使其生成更高质量的回答
PPO 通过裁剪机制在"改进策略"和"保持稳定"之间取得平衡——创建一个"信任区域",防止策略更新偏离太远导致性能崩溃。
DPO 跳过了奖励模型,直接在人类偏好数据上优化语言模型策略——"增加被偏好响应的生成概率,降低不被偏好响应的概率"。相比 PPO 的两步流程(先训练奖励模型,再用奖励模型优化),DPO 更简单且更稳定。
10.6.2 PBRFT vs Agentic RL
传统的后训练(PBRFT: Preference-Based Reinforcement Fine-Tuning)与 Agentic RL 的根本区别在于决策的时间跨度和复杂度:

| 维度 | PBRFT | Agentic RL |
|---|---|---|
| 状态 | 仅用户提示,单步 | 历史观察 + 上下文,多步演化 |
| 行动 | 仅文本生成 | 文本生成 + 工具调用 + 环境操作 |
| 奖励 | 单步终端奖励 | 多步累积奖励(稀疏/密集/混合) |
| 目标 | 最大化单步回答质量 | 最大化任务完成度 |
| 思维 | "如何生成更好的回答" | "如何完成复杂任务" |
10.6.3 Agentic RL 的六大核心能力
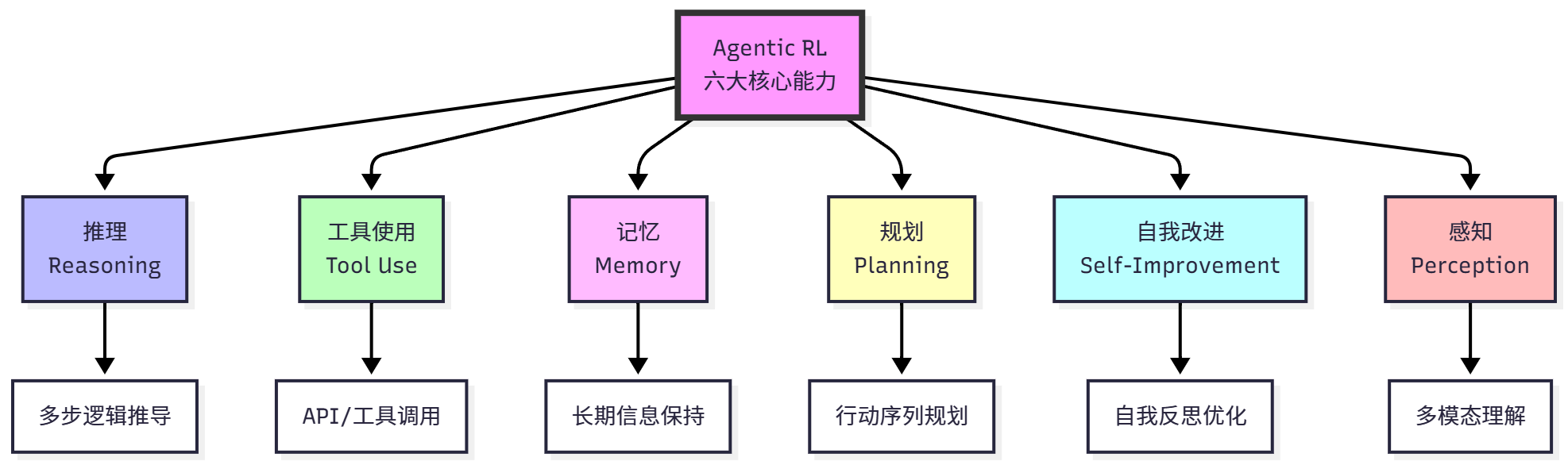
推理(Reasoning):通过强化学习让智能体学习有效的推理策略——发现训练数据中不存在的推理路径,学会何时深思熟虑、何时快速回答。
工具使用(Tool Use):行动空间扩展为文本生成和工具调用的混合。强化学习让智能体学会何时需要工具、选择哪个工具、如何组合多个工具。
记忆(Memory):学会记忆管理策略——决定哪些信息值得记住、何时更新记忆、何时删除过时信息。类似人类的工作记忆管理。
规划(Planning):通过试错发现有效的行动序列,学会权衡短期和长期收益。能够执行看似"绕路"的中间步骤以达成最终目标。
自我改进(Self-Improvement):回顾自身输出、识别错误、分析失败原因、调整策略。在无人工干预的情况下持续改进。
感知(Perception):理解多模态信息——不仅能处理文本,还能理解和操作视觉世界。
10.6.4 GRPO:实用的训练算法
GRPO(Group Relative Policy Optimization)是在实践中广泛使用的 Agentic RL 训练算法。与 PPO 需要训练独立的价值网络不同,GRPO 通过组内对比来估计奖励基线:
对于每个问题,生成多个候选回答,根据正确性获得奖励,然后在组内计算相对优势——奖励高于组平均的回答被强化,低于组平均的被抑制。这种设计避免了价值网络的训练开销,同时保持了有效的策略优化。
10.6.5 Agent 专用微调方法
通用 LLM 在智能体任务上的表现往往不及预期——它们擅长对话和文本生成,但在工具调用序列、多步推理和环境交互方面缺乏专门优化。近年来,一系列工作探索了 Agent 专用的微调策略:
Agent-FLAN [Chen et al., 2024, arXiv:2403.12881] 系统研究了如何设计 Agent 训练数据。核心发现是:训练数据的设计比数据规模更重要。Agent-FLAN 提出了三个关键原则:(1)将能力分解为独立子技能分别训练,而非端到端学习完整轨迹;(2)引入负样本(错误的工具调用、不当的推理步骤)教会模型识别和避免常见错误;(3)在通用能力和 Agent 能力之间保持平衡,避免"灾难性遗忘"。在 Llama2-7B 上的实验显示,Agent-FLAN 的微调方案将 held-out Agent 任务的成功率提升了 30% 以上。
AgentTuning [Zeng et al., 2023, arXiv:2310.12823] 采用多任务指令微调策略,在多个 Agent 任务上同时训练模型。其核心思想是:Agent 能力不是单一技能,而是工具使用、推理、规划等多种能力的组合。通过在 AgentInstruct 数据集上进行混合训练,AgentTuning 在不损失通用能力的前提下,显著提升了模型在 unseen Agent 任务上的泛化能力。
FireAct [Chen et al., 2023, arXiv:2310.05915] 探索了轨迹微调——直接在成功的 Agent 执行轨迹上微调模型。FireAct 的关键贡献是证明了:使用 GPT-4 生成的高质量 ReAct 轨迹来微调较小模型(如 Llama-2-13B),可以让小模型获得接近大模型的 Agent 能力。这为 Agent 能力的"蒸馏"提供了实用路径。
核心洞察:Agent 微调领域的一个共识正在形成——训练数据质量 > 数据规模 > 模型大小。精心设计的少量高质量轨迹数据,往往比大量低质量数据产生更好的 Agent 能力。这与通用 LLM 训练中"数据规模至上"的范式形成了有趣的对比。
10.6.6 Agentic 数据制作的三路径范式
上述工作可以抽象为三条互补的数据制作路径:
| 路径 | 目标 | 方法 | 典型规模 | 代表工作 |
|---|---|---|---|---|
| 大规模合成预训练数据 | 学"能动性"——让模型具备基本的 Agent 行为模式 | LLM 自动生成大量 Agent 交互轨迹 | 数十万条 | ToolLLM, Gorilla |
| 环境化合成微调数据 | 学"动得对"——在特定环境中准确执行 | 在沙箱环境中运行 Agent 收集成功轨迹 | 数千至数万条 | AgentTuning, Agent-FLAN |
| 人工精标长轨迹数据 | 学"动得稳"——处理复杂长链条任务 | 人工标注完整的多步操作轨迹 | 数十至数百条 | LIMI(78 条长轨迹,~6.5M tokens) |
三条路径不是替代关系,而是递进互补——先用大规模合成数据建立基础能力,再用环境化数据精细调整,最后用少量精标数据突破复杂任务瓶颈。LIMI(2025)的实验表明,仅用 78 条高密度策略示范轨迹,即可使复杂规划任务的成功率平均提升 +43%;CER(Contextual Experience Replay, 2025)在 WebArena 等环境中通过经验回放机制,成功率较 GPT-4o 基线提升约 +51%。这些结果再次印证了"少而精 > 多而泛"的数据哲学。
10.7 可验证奖励强化学习(RLVR)
标准 CoT 提示词是一种相对静态的推理方法——它生成单一的、预定的思路。RLVR 通过强化学习训练产生新一代"推理模型",这些模型的特点是:
- 在回答前投入可变量的"思考时间",根据问题难度动态调整
- 生成长达数千 token 的动态思维链,支持自我纠正和回溯
- 在有可验证正确答案的任务(数学、编程)上通过试错学习推理策略
RLVR 模型不仅产生答案,还生成展示规划、监控和评估等高级技能的"推理轨迹"。这种能力使得推理模型成为构建自主智能体的理想基座。
10.8 Agent 蒸馏与小模型部署
大模型 Agent(如基于 GPT-4 或 Claude 的系统)虽然能力强大,但其高昂的推理成本和延迟使得大规模部署面临挑战。Agent 蒸馏是将大模型的 Agent 能力迁移到小模型的关键技术路径。
蒸馏策略的谱系:
- 轨迹蒸馏:用大模型生成高质量的 Agent 执行轨迹(包括推理过程、工具调用和结果解析),然后在这些轨迹上微调小模型。FireAct 和 Agent-FLAN 都属于这一范畴
- 能力分层蒸馏:将完整的 Agent 能力分解为子技能(工具选择、参数生成、结果解析),分别蒸馏到不同的小模型或同一模型的不同 LoRA 适配器
- 在线蒸馏:在部署过程中持续收集大模型的成功轨迹,定期更新小模型——形成"大模型探索、小模型利用"的闭环
能力-成本 trade-off:实践经验表明,7B-13B 参数的微调模型在结构化 Agent 任务(固定工具集、明确目标)上可达到 GPT-4 约 70-80% 的性能,而推理成本仅为其 1/10 至 1/50。但在需要复杂推理、开放式探索或处理罕见场景的任务上,小模型的性能下降更为显著。合理的部署策略是模型级联:小模型处理常规任务,复杂任务自动路由到大模型。
10.9 Token 经济学
智能体系统的运行成本主要由 Token 消耗决定。不同架构模式的 Token 消耗差异显著,理解这些差异对于系统设计和成本控制至关重要。
不同架构的典型 Token 消耗:
| 架构模式 | 单任务典型消耗 | 主要成本来源 | 适用预算级别 |
|---|---|---|---|
| 单次 CoT 调用 | ~1K-2K tokens | 推理链长度 | 极低 |
| ReAct(3-5轮) | ~5K-10K tokens | 工具调用+观察结果 | 低 |
| Plan-and-Solve | ~8K-15K tokens | 规划+逐步执行 | 中 |
| Reflection 循环 | ~10K-20K tokens | 多轮生成+评估 | 中 |
| 多 Agent 协作 | ~20K-50K tokens | Agent 间通信+各自推理 | 高 |
| 自我进化迭代 | ~50K-200K tokens | 多轮修改+完整测试 | 极高 |
成本优化策略:
- 模型级联:简单子任务用小模型(如 GPT-4o-mini、Gemini Flash),仅将复杂推理路由到大模型,可降低 60-80% 成本
- Prompt 缓存:主流 API 提供商(Anthropic、OpenAI、Google)均支持 prompt 缓存,对于系统提示和工具定义等重复内容可节省约 90% 的输入 Token 费用
- 批处理:将多个独立的 Agent 任务合并为批处理请求,利用 API 的批处理折扣(通常为 50% off)
- 上下文修剪:定期清理工具返回的冗余信息,使用摘要替代原始输出,控制上下文增长
主流 API 定价参考(2025年初):
| 模型 | 输入价格 ($/1M tokens) | 输出价格 ($/1M tokens) | 上下文窗口 |
|---|---|---|---|
| GPT-4o | 2.50 | 10.00 | 128K |
| GPT-4o-mini | 0.15 | 0.60 | 128K |
| Claude Sonnet 4 | 3.00 | 15.00 | 200K |
| Claude Haiku 3.5 | 0.80 | 4.00 | 200K |
| Gemini 2.0 Flash | 0.10 | 0.40 | 1M |
| Gemini 2.5 Pro | 1.25-2.50 | 10.00 | 1M |
注:价格随时间变化,以官方文档为准。缓存命中价格通常为输入价格的 10%。
关键实现决策 -- 工程实践中的关键选择点
10.10 推理技术的选择
| 场景 | 推荐技术 | 理由 |
|---|---|---|
| 一般性多步推理 | CoT | 成本低、效果稳定、最广泛适用 |
| 需要搜索最优解 | ToT | 多路径探索,但计算成本较高 |
| 需要减少偏见 | GoD/CoD | 多视角辩论,但需要多次 LLM 调用 |
| 需要与外部交互 | ReAct | 推理与行动统一,动态适应 |
| 精确计算密集 | PALMs | 利用代码执行器的确定性 |
| 训练专用推理模型 | RLVR | 一次训练,持续受益 |
实践中,这些技术常常组合使用:ReAct 的每个"思考"步骤内部使用 CoT,PALMs 可以嵌入 ReAct 的"行动"步骤。
10.11 自我改进系统的安全设计
自我修改的智能体带来独特的安全挑战——它可以改变自身行为,这既是能力也是风险。关键防护措施:
- 沙箱隔离:所有代码执行在 Docker 容器中进行,与主机隔离
- 异步监督:独立的监督 LLM 持续监控行为,检测循环、停滞或异常
- 版本控制:完整的历史版本档案,随时可回滚到已知良好版本
- 性能门控:修改后必须通过基准测试,性能下降的版本不会被采纳
10.12 奖励函数设计原则
奖励函数是强化学习训练的核心决策点,直接决定智能体学到什么行为:
好的奖励函数特征:
- 成功标准清晰可量化(如数学答案的正确性)
- 提供可用的梯度信号(不全是 0/1 的稀疏奖励)
- 方差适中,训练稳定
- 支持多目标组合(如正确性 + 简洁性 + 步骤质量)
常见陷阱:
- 奖励欺骗:智能体找到"作弊"方式获取高奖励而非真正完成任务
- 只有终端奖励:中间步骤无反馈,学习效率低
- 目标冲突:多个奖励信号互相矛盾
实践中有效的策略是组合多种奖励:准确率奖励(正确答案得分)+ 长度惩罚(抑制过长的无意义输出)+ 步骤奖励(鼓励清晰的推理步骤)。
10.13 MASS:多智能体系统的自动化设计
MASS(Multi-Agent System Search)提出了一个超越手工设计的方法论:自动搜索最优的多智能体系统配置。它通过三阶段优化解决这个问题:
- 块级提示词优化:独立优化每个智能体角色的提示词
- 工作流拓扑优化:搜索最有效的智能体交互拓扑(使用影响加权采样)
- 工作流级提示词优化:在确定最优拓扑后,对整个系统的提示词进行联合优化
实验表明,MASS 优化后的系统显著优于手工设计方案。关键发现是:有效的多智能体系统设计需要同时优化个体能力(提示词)和协作结构(拓扑)。
前沿动态 -- 学术界/工业界最新进展
10.14 推理扩展定律
推理扩展定律(Inference Scaling Law)表明,模型性能随推理时计算资源的增加而可预测地提升。这一发现推动了"Deep Research"类产品的出现——用户给 AI 一个复杂查询和"时间预算"(通常几分钟),AI 自主执行多轮搜索、分析和综合,返回远超单次查询深度的结构化报告。
这代表了搜索范式的根本转变:从"即时返回链接"到"授权 AI 代理完成深度研究"。
10.15 自主算法发现
AlphaEvolve 和 OpenEvolve 展示了 AI 智能体自主发现和优化算法的可能性。这种"智能体作为研究者"的范式有潜力加速科学发现过程——不再局限于优化已知算法的超参数,而是探索全新的算法结构和解题策略。
10.16 LLM 智能体的自我改进瓶颈
SICA 的实践揭示了当前自我改进系统的核心挑战:让 LLM 在每次改进迭代中提出真正新颖、可行且有价值的修改仍然困难。模型倾向于在安全的、渐进式的改进中徘徊,较少产生突破性的创新。如何在自我改进循环中注入更多的创造性探索,是开放的研究问题。
本章小结
学习、适应与推理增强共同指向智能体能力的动态扩展。学习与适应使智能体能够从经验中改进——SICA 通过修改自身代码持续提升编程能力,AlphaEvolve 通过进化框架发现新算法。推理增强使智能体在面对复杂问题时能够调动更多计算资源——CoT 提供逐步推导,ToT 支持多路径探索,ReAct 统一了推理与行动,RLVR 训练出能动态分配思考时间的推理模型。
Agentic RL 代表了 LLM 从"对话助手"向"自主智能体"演化的训练范式转变。它不再优化单步回答质量,而是优化多步任务的完成度,通过累积奖励信号训练智能体的推理、工具使用、规划和自我改进等核心能力。
工程实践中的关键决策包括:推理技术的场景匹配(CoT 作为通用默认,ReAct 用于需要工具交互的任务)、自我改进系统的安全设计(沙箱隔离、异步监督、性能门控)、以及奖励函数的精细设计(组合多目标、避免奖励欺骗)。
⚠️ 已知局限:自我改进系统面临"自我认知盲区"问题——LLM倾向于做渐进式、安全的修改,而非突破性的创新。SICA的实践表明,经过多轮迭代后性能改进会趋于平台期,模型难以跳出局部最优。在推理增强方面,ToT和GoD的计算开销极高(单个问题可能需要数十次LLM调用),使其在延迟敏感的场景中不实用。RLVR训练的推理模型在分布外问题上可能产生过度自信的错误推理链,表面看似严谨实则结论错误。
这些技术正在将智能体从"预设能力的执行者"转变为"能力持续扩展的自主系统"。