第5章 Plan-and-Solve——计划与执行
本章来源:综合自 Hello-Agents/chapter4(Plan-and-Solve范式构建)、agentic-design-patterns/Chapter 6(Planning设计模式)
核心问题 —— 本章要解答什么
如果说ReAct是一位经验丰富的侦探,根据现场线索逐步推理;那么Plan-and-Solve更像一位建筑师,在动工之前必须先绘制完整的蓝图。Plan-and-Solve(Wang et al., 2023)将"思考"和"行动"在时间维度上明确分离——先制定完整计划,再严格执行。这种"三思而后行"的策略在结构化任务上展现出独特优势。本章聚焦以下关键问题:
- Plan-and-Solve解决了CoT和ReAct的什么痛点?
- 规划阶段(Planning)和执行阶段(Solving)各自的设计要求是什么?
- 计划的"刚性"与"柔性"如何权衡?什么时候计划应该被修改?
- 规划器(Planner)和执行器(Executor)的工程实现中有哪些关键的状态管理决策?
设计空间 —— 可选方案与取舍
| 维度 | 取值范围 | 设计考量 |
|---|---|---|
| 计划粒度 | 粗粒度(大步骤) ↔ 细粒度(原子操作) | 粗粒度给执行器更多自由但可能引入歧义;细粒度精确但规划成本高且过度约束 |
| 计划刚性 | 固定计划严格执行 ↔ 动态计划可修改 | 固定计划简单可预测但不适应意外;动态计划灵活但增加复杂度 |
| 规划-执行模型 | 同一模型 ↔ 不同模型 | 同一模型简单一致;不同模型可以用强模型规划+弱模型执行,优化成本 |
| 步骤间状态传递 | 全量传递 ↔ 增量传递 | 全量传递确保完整性但消耗Token;增量传递高效但可能丢失关键上下文 |
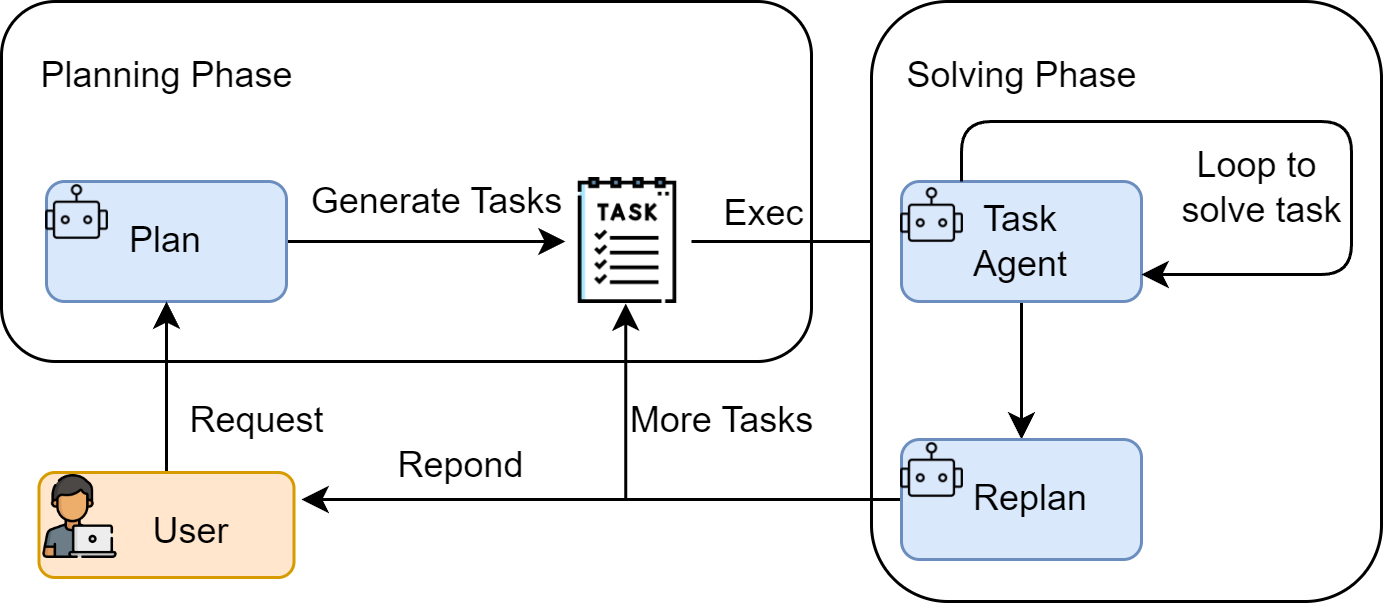
架构解析 —— Plan-and-Solve的双阶段机制
5.3.1 为什么需要先规划
ReAct的"走一步看一步"模式在面对以下场景时会暴露局限:
- 长链条任务:当任务需要十步以上的连续操作时,ReAct可能在中途偏离目标,因为每步的决策都是局部的,没有全局方向的锚定。
- 强依赖任务:当后续步骤严格依赖前序步骤的结果,且步骤顺序不可调换时,缺乏预先规划会增加出错和回溯的风险。
- 资源约束任务:在API调用次数有限、计算预算受限的场景下,盲目的试探-调整策略比不上有目的的计划执行。
Plan-and-Solve的核心动机正是为了解决CoT在多步骤复杂问题上"偏离轨道"的问题。在数学推理基准GSM8K上,Plan-and-Solve (PS+) 将GPT-3.5的零样本准确率从78.7%(标准CoT)提升至80.7% [Wang et al., 2023]。通过将问题分解前置,智能体在执行阶段始终有一个全局蓝图作为参照,保持更高的目标一致性。
5.3.2 形式化定义
Plan-and-Solve将任务处理分为两个明确的阶段:
规划阶段:规划模型
执行阶段:执行模型
最终答案为
这个形式化与ReAct的关键区别在于:ReAct中每步的决策同时包含"想什么"和"做什么",且行动空间随观察动态变化;Plan-and-Solve中"想什么"被集中到规划阶段一次性完成,执行阶段只需"做什么"和"传递结果"。
5.3.3 与经典 AI 规划的衔接
Plan-and-Solve 的"先规划后执行"思想并非 LLM 时代的发明。经典 AI 规划领域已有数十年的研究积累,理解这些传统方法有助于明确 LLM 规划的定位和局限。
PDDL(Planning Domain Definition Language) 是经典规划的标准描述语言。它将规划问题形式化为四元组
HTN(Hierarchical Task Network) 与 Plan-and-Solve 的任务分解高度对应。HTN 将高层任务递归分解为原子操作,分解规则(method)定义了每种任务类型的分解方式。Plan-and-Solve 的规划阶段本质上就是一种非形式化的 HTN 分解——LLM 根据语义理解将任务分解为子步骤。
LLM+P [Liu et al., 2023, arXiv:2304.11477] 提供了一种将两个世界桥接的优雅方案:LLM 负责将自然语言问题翻译为 PDDL 描述,经典规划器负责在形式化空间中求解最优计划,LLM 再将形式化计划翻译回自然语言。这种混合方案结合了 LLM 的语义理解能力和经典规划器的最优性保证。
LLM 规划 vs 经典规划的对比:
| 维度 | 经典规划(PDDL) | LLM 规划(Plan-and-Solve) |
|---|---|---|
| 输入格式 | 形式化状态/动作描述 | 自然语言 |
| 最优性保证 | 可证明最优(在形式化模型内) | 无保证 |
| 领域适应 | 需要人工建模每个领域 | 零样本泛化到新领域 |
| 不确定性处理 | 需要扩展(如 POMDP) | 天然处理模糊输入 |
| 可扩展性 | 状态空间爆炸问题 | 受上下文窗口限制 |
| 可解释性 | 完全可解释(形式化证明) | 部分可解释(推理链) |
对于需要最优性保证的关键任务(如物流调度、资源分配),经典规划器仍是更可靠的选择;对于需要处理模糊输入和跨领域泛化的场景,LLM 规划更具优势。
5.3.4 规划阶段:从问题到蓝图
规划阶段的核心任务是将一个复杂问题分解为一系列逻辑连贯、可独立执行的子步骤。这一阶段的提示词设计需要满足三个要求:
- 角色设定:明确模型是"规划专家"而非"执行者",避免模型在规划阶段就开始求解。
- 结构化输出:要求模型以可程序化解析的格式(如Python列表、JSON数组)输出计划,而非自由文本。这极大简化了后续的代码解析。
- 质量约束:要求步骤之间逻辑连贯、顺序正确、每步都是独立可执行的子任务。
一个典型的规划提示词模板:
你是一个顶级的AI规划专家。你的任务是将用户提出的复杂问题分解成
一个由多个简单步骤组成的行动计划。请确保每个步骤都是独立的、
可执行的子任务,并严格按照逻辑顺序排列。
输出必须是一个Python列表格式。使用Python列表格式而非自然语言的选择是深思熟虑的——ast.literal_eval 可以安全地将字符串转换为列表对象,比解析自然语言更稳定、更可靠。
5.3.5 执行阶段:从蓝图到结果
执行阶段的设计核心是状态管理——每步的执行结果必须可靠地传递给后续步骤。执行器的提示词需要同时包含四个信息层次:
- 原始问题:确保模型始终了解最终目标,不会在执行子步骤时迷失方向。
- 完整计划:让模型了解当前步骤在整体任务中的位置和角色。
- 历史步骤与结果:提供已完成工作的完整记录,作为当前步骤的输入上下文。
- 当前步骤:明确指示当前需要解决的具体子任务。
状态管理通过一个不断增长的历史字符串实现:每完成一步,将"步骤描述 + 执行结果"追加到历史中。这确保了信息在任务链条中的顺畅流动——例如,步骤3可以引用步骤1和步骤2的结果来进行计算。
5.3.6 组装:规划器-执行器协同
PlanAndSolveAgent 作为协调者,将规划器和执行器组合为一个完整的工作流:
- 接收用户问题
- 调用
Planner.plan()生成结构化计划 - 验证计划是否有效(非空、格式正确)
- 调用
Executor.execute()按计划逐步执行 - 返回最终结果
这种"组合优于继承"的设计使得各组件可以独立测试和替换——可以用不同的模型分别担任规划器和执行器,也可以在规划器中加入领域特定的约束。
关键实现决策 —— Plan-and-Solve的工程化选择
决策一:计划的刚性与柔性
固定计划(经典Plan-and-Solve):一旦生成就严格执行,不允许中途修改。优点是简单可预测,缺点是无法适应执行中的意外情况。
动态计划(Adaptive Planning):允许在执行过程中根据中间结果修改剩余步骤。例如,当某步的结果与预期不符时,触发重新规划。Google DeepResearch就采用了这种迭代规划方法——创建初始研究计划后,根据持续的信息收集来适应和演化计划。
选择哪种取决于任务特性:结构高度确定的任务(如数学计算)适合固定计划;探索性任务(如研究报告撰写)需要动态计划。
决策二:规划粒度的选择
- 粗粒度:如"收集数据 → 分析数据 → 撰写报告"。每步给执行器很大的自由度,但可能导致执行结果的不可控。
- 细粒度:如"查询2024年Q1销售额 → 查询2024年Q2销售额 → 计算环比增长率 → ..."。每步精确可控,但规划成本高,且过度限制了执行器的灵活性。
实践中的经验法则是:计划的粒度应该匹配执行器的能力。如果执行器是一个能力强的LLM,粗粒度计划更高效;如果执行器是一个简单的脚本执行环境,细粒度计划更可靠。
决策三:规划-执行模型的分配
在资源充裕时,规划和执行可以使用同一个强大的模型。但在成本敏感的场景中,一种有效的策略是异构分配:用能力最强的模型做规划(规划只需一次调用),用成本较低的模型做执行(执行需要多次调用)。规划的质量通常对最终结果的影响远大于单步执行的质量。
前沿动态 —— 规划能力的演进
趋势一:从单次规划到迭代规划
经典Plan-and-Solve假设规划是一次性的。但前沿实践表明,迭代规划在复杂任务上效果更好。Google DeepResearch和OpenAI Deep Research的工作流都采用了"规划 → 执行部分步骤 → 根据结果修订计划 → 继续执行"的循环模式,将规划从静态蓝图升级为动态导航。
趋势二:规划的可验证性
如何验证一个计划的质量?新兴方向包括:使用独立的评估模型对计划进行打分;通过模拟执行来预测计划的成功概率;引入约束求解器来验证计划的逻辑一致性。这些方法将规划从"LLM拍脑袋"提升为"有质量保障的工程过程"。
趋势三:规划与工具的深度集成
早期Plan-and-Solve的规划阶段不涉及工具调用。前沿方向是让规划器在生成计划时就考虑可用工具的能力和约束——生成的不是抽象的任务步骤,而是具体的"用工具X对输入Y执行操作Z"的指令序列。这种工具感知的规划使得执行阶段更加精确和高效。
本章小结
Plan-and-Solve通过将规划和执行在时间维度上解耦,为智能体提供了处理结构化复杂任务的能力框架:
- 核心机制:规划阶段将问题分解为步骤序列,执行阶段按序求解并传递状态。两个阶段的分离使得全局规划成为可能。
- 工程实现:规划器通过结构化输出格式确保计划可程序化解析;执行器通过历史状态管理确保信息在任务链中的顺畅流动;协调者通过组合模式将两者整合。
- 与ReAct的互补:ReAct擅长需要实时适应的探索性任务,Plan-and-Solve擅长结构明确的计划性任务。两者不是替代关系,而是可以组合使用的互补工具。
⚠️ 已知局限:Plan-and-Solve假设任务可以在规划阶段被完整分解,但对于高度不确定性的任务(如需要根据中间探索结果动态调整方向的研究任务),预先生成的计划往往在前几步执行后就变得不再适用。此外,LLM生成的计划缺乏形式化最优性保证——在需要最优解的场景(如资源调度、路径规划)中,经典规划器仍然更可靠。
无论是ReAct的动态决策还是Plan-and-Solve的计划执行,智能体的输出都是"一次性"的——完成就结束。但如果输出有缺陷怎么办?下一章将介绍Reflection范式,它为智能体引入自我审查和迭代优化的能力,将"单次生成"转变为"持续改进"。