第1章 智能体的历史脉络与范式演进
本章来源:综合自 Hello-Agents/chapter2(智能体发展史全景视角)、ce101(上下文工程的历史演进视角)
核心问题 —— 本章要解答什么
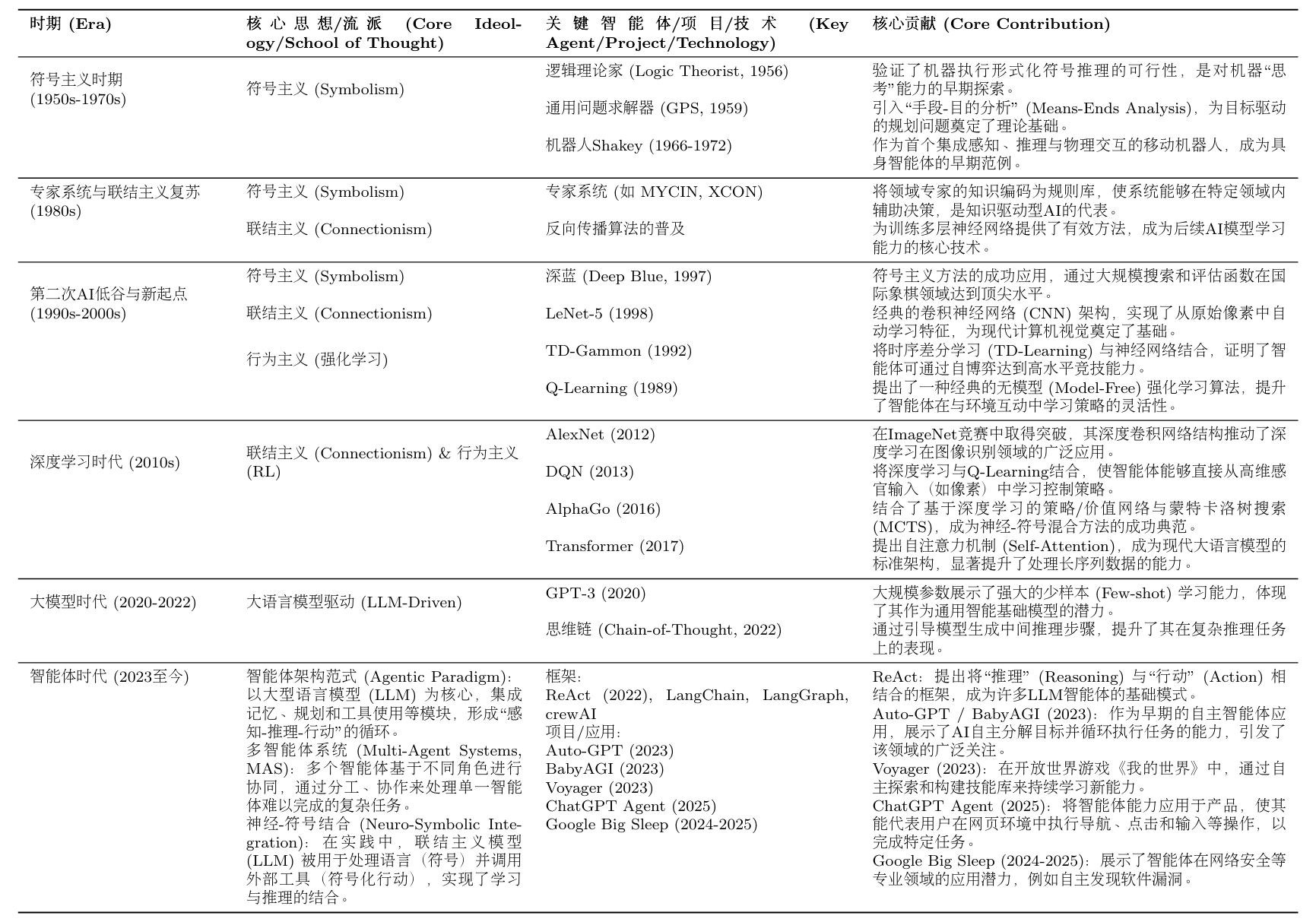
现代AI智能体的架构并非凭空出现,而是人工智能领域六十余年思想演进的结晶。理解"为什么当代智能体是这样设计的",需要回答以下关键问题:
- 符号主义为什么最终无法通往通用智能?它给现代智能体留下了哪些遗产?
- "分布式智能"的思想是如何从哲学构想演变为工程实践的?
- 学习范式(联结主义、强化学习、大规模预训练)如何依次解决了前代范式的核心瓶颈?
- LLM驱动的智能体在架构层面融合了哪些历史范式的要素?
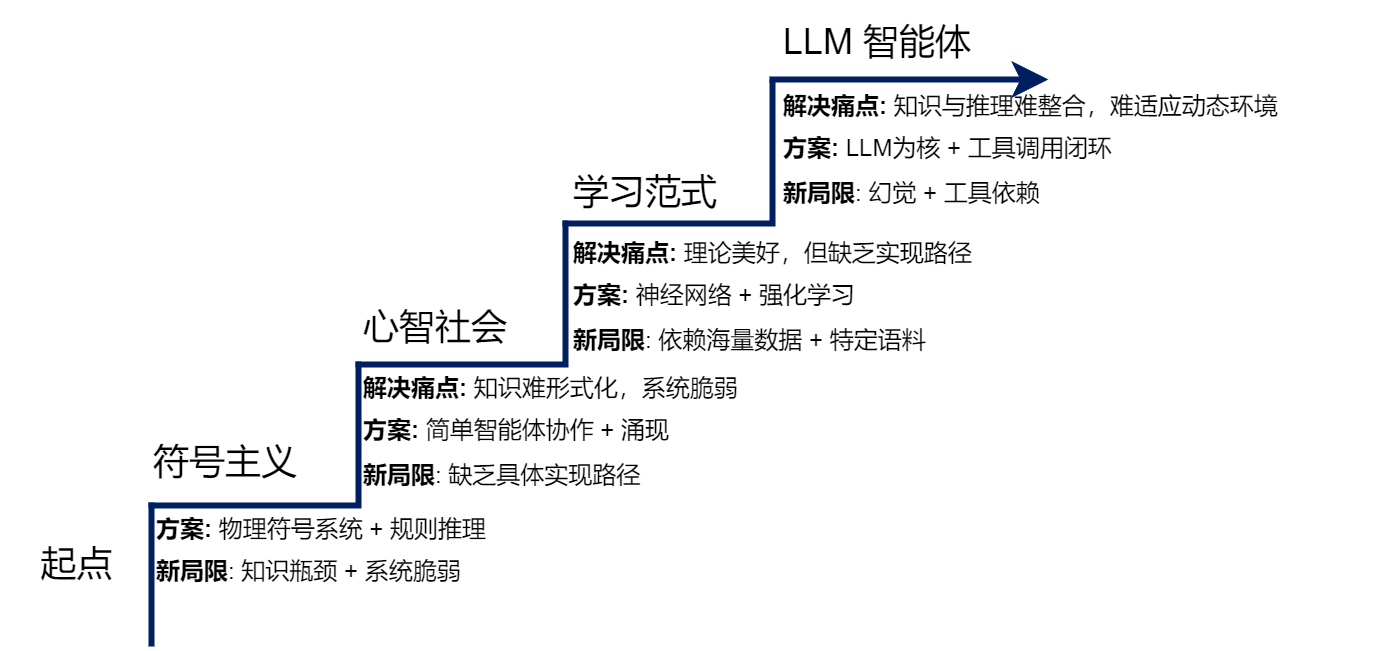
如图1.1所示,每一个新范式的出现,都是为了解决上一代范式的核心痛点或根本局限。新的解决方案在带来能力飞跃的同时,也引入了新的局限,而这又为下一代范式的诞生埋下了伏笔。理解这一"问题驱动"的迭代历程,是把握现代智能体技术选型背后深层原因的关键。
设计空间 —— 可选方案与取舍
智能体的设计空间可以从三个正交维度来审视:
| 维度 | 取值范围 | 典型代表 |
|---|---|---|
| 知识获取方式 | 手工编码 ↔ 从数据学习 | 专家系统 ↔ 深度学习模型 |
| 控制架构 | 集中式单体 ↔ 分布式协作 | SHRDLU ↔ 多智能体系统 |
| 推理机制 | 显式符号推理 ↔ 隐式神经推理 | 产生式规则 ↔ Transformer注意力 |
这三个维度并非互斥选择,而是可以混合组合的设计参数。现代LLM驱动的智能体之所以强大,恰恰在于它在这三个维度上实现了前所未有的综合:通过预训练从数据中学习(联结主义),以自然语言进行显式推理(神经-符号结合),并可通过多智能体架构实现分布式协作。
架构解析 —— 从符号主义到LLM Agent的范式演进
1.3.1 符号主义:知识+推理的经典框架
符号主义(Symbolicism)是人工智能的第一个重要范式,其理论基础是1976年由Allen Newell和Herbert A. Simon提出的物理符号系统假说(PSSH)。该假说包含两个核心论断:
- 充分性论断:任何一个物理符号系统,都具备产生通用智能行为的充分手段。
- 必要性论断:任何一个能够展现通用智能行为的系统,其本质必然是一个物理符号系统。
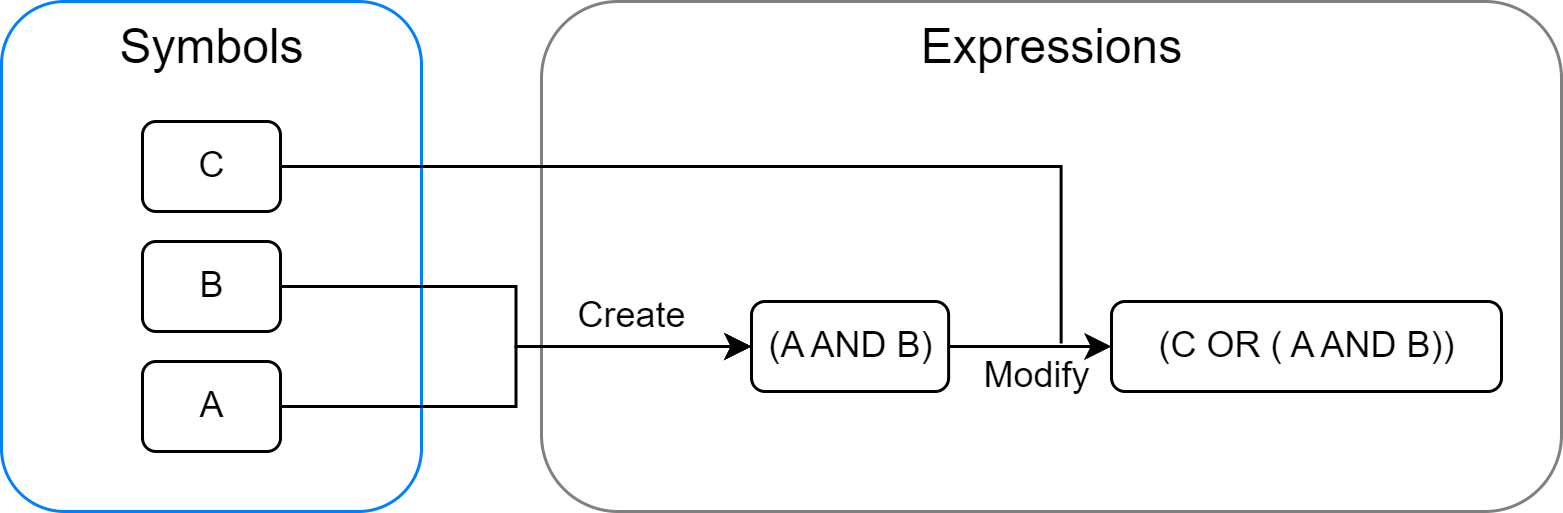
PSSH将对人类心智的哲学追问,转化为了可以在计算机上进行工程化实现的具体问题。整个符号主义时代的研究——从专家系统到自动规划——几乎都在这一假说的指引下展开。
专家系统:符号主义的工程巅峰
专家系统是符号主义时代最成功的应用成果。其架构体现了知识与推理分离的核心设计思想:
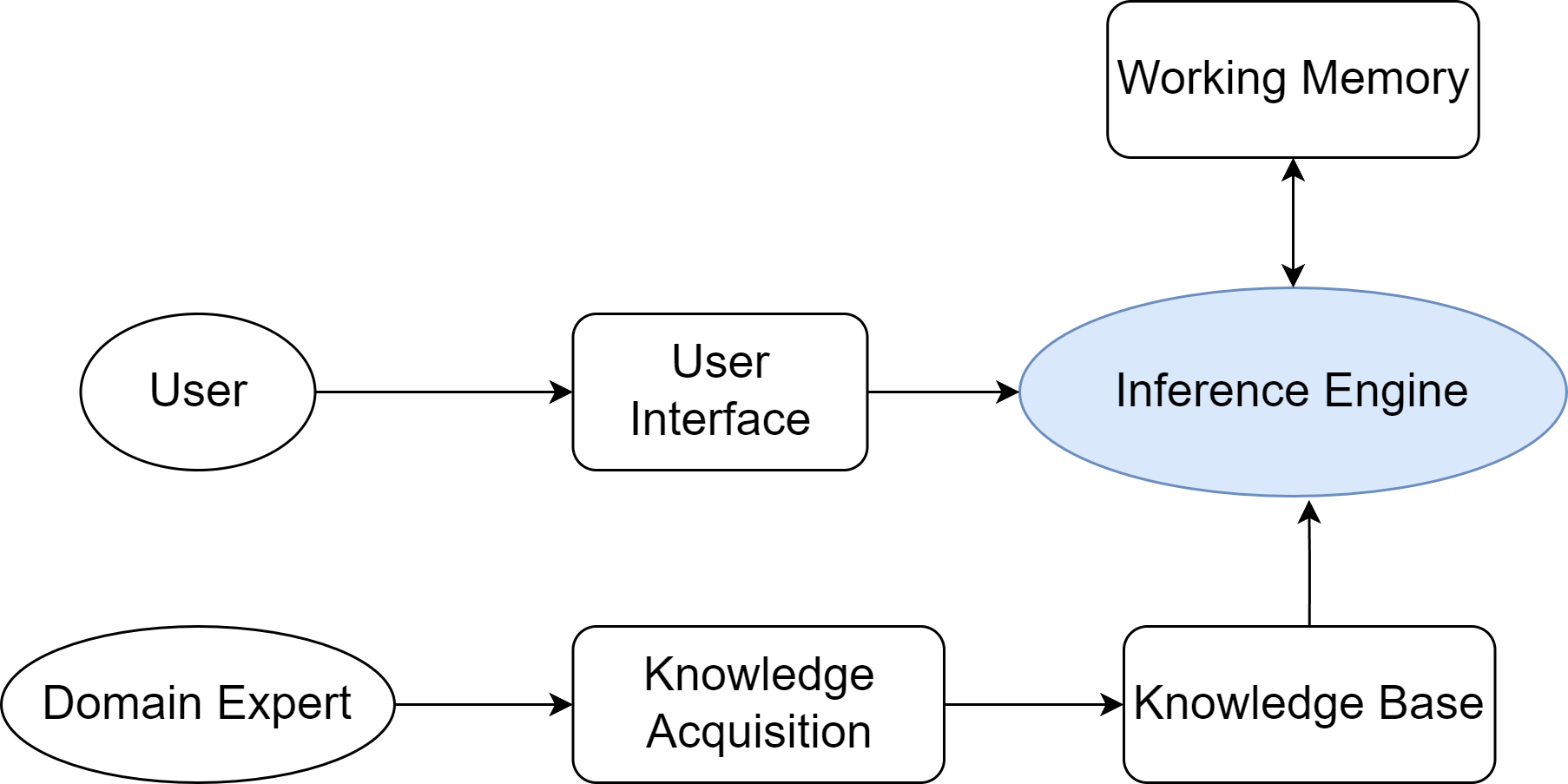
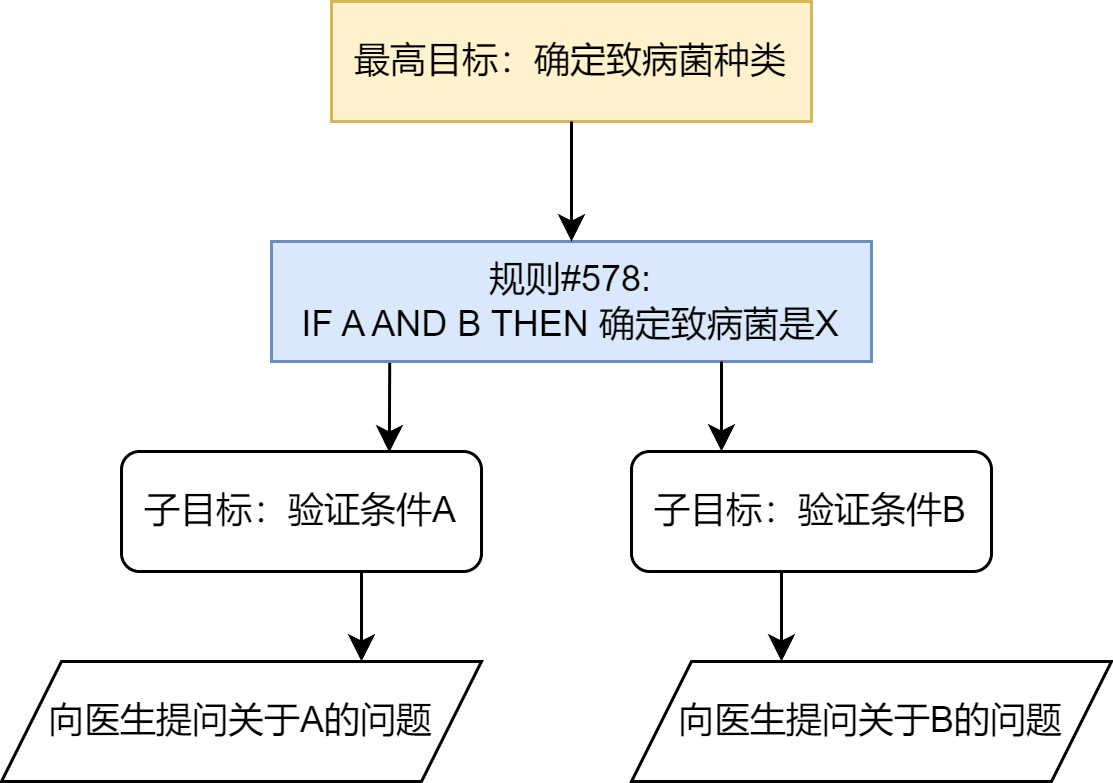
以MYCIN系统为例,这个由斯坦福大学于20世纪70年代开发的医疗诊断专家系统,包含约600条"IF-THEN"规则,采用反向链推理机制,并创新性地引入了置信因子(CF)来处理不确定性推理。MYCIN在血液感染诊断方面的表现达到了人类专家水平,充分证明了PSSH的有效性。
SHRDLU:综合性智能的早期尝试
SHRDLU项目由Terry Winograd于1968-1970年开发,首次将多个独立的AI模块(语言解析、规划、记忆)集成在一个统一系统中。它能在"积木世界"中通过自然语言与人类流畅交互,实现了"感知-思考-行动"的闭环设计。
SHRDLU的历史意义在于三个方面:它是综合性智能的早期典范;它普及了微观世界研究方法;它揭示了"符号处理"与"真正理解"之间的深层鸿沟。
符号主义的根本性困境
从20世纪80年代起,符号主义遇到了其方法论固有的根本性难题:
- 知识获取瓶颈:专家知识需要通过繁琐的访谈、提炼和编码过程来构建,且人类专家的许多知识是内隐的、直觉性的,难以被表达为"IF-THEN"规则。
- 常识问题:人类行为依赖的庞大常识背景(如"水是湿的"、"绳子可以拉不能推"),无法被穷尽式编码。Cyc项目历经数十年努力,成果仍然非常有限。
- 框架问题:在动态世界中,智能体执行一个动作后,如何高效判断哪些事物未发生改变是一个逻辑难题。
- 系统脆弱性:符号系统完全依赖预设规则,一旦遇到规则之外的任何微小变化,系统便可能完全失灵。
这些困境的本质可以归结为一点:试图用穷举式的符号编码来覆盖开放世界的无穷复杂性,是一种注定不可扩展的方法。 这一认识直接催生了后续范式的革新。
1.3.2 心智社会:从集中到分布的思想革命
面对符号主义的困境,Marvin Minsky在《心智社会》(The Society of Mind, 1986)中提出了一个颠覆性的问题:"What magical trick makes us intelligent? The trick is that there is no trick."
Minsky反思了单一整体智能模型的核心弊端——试图用一种统一的表示和推理机制来解决所有问题——并提出了一个全新的框架:
- 智能不是一个金字塔式的层级结构,而是一个扁平化的、充满交互与协作的"社会"。
- 每个"智能体"(agent)是一个极其简单的、专门化的心智过程,它自身是"无心"的。
- 这些简单智能体被组织成功能更强大的机构(Agency)。
- 复杂的智能行为从大量简单智能体之间的局部交互中涌现(Emergence)。
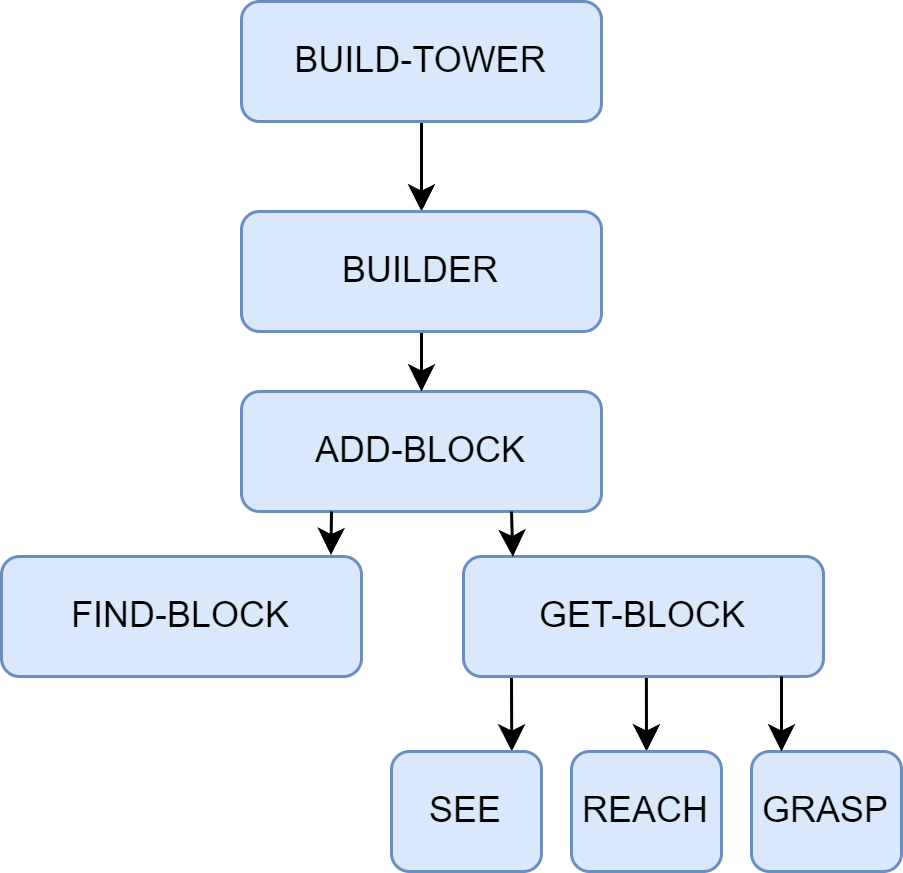
以"搭建积木塔"为例(图1.6):BUILD-TOWER机构激活BUILDER,BUILDER激活ADD-BLOCK,ADD-BLOCK协调FIND-BLOCK、GET-BLOCK和PUT-ON-TOP,每个子机构又由更底层的智能体构成。没有任何一个智能体拥有整个任务的全局规划,但智能行为自然涌现。
对多智能体系统的理论启发
心智社会理论为分布式人工智能(DAI)和多智能体系统(MAS)提供了重要的概念基础,其影响体现在:
- 去中心化控制:如何设计没有中心节点的协调机制和任务分配策略。
- 涌现式计算:蚁群算法、粒子群优化等基于涌现思想的算法。
- 智能体的社会性:通信语言(ACL)、交互协议(契约网)、协商策略、信任模型。
从现代视角审视,心智社会理论预言了当今多智能体系统的核心设计原则。MetaGPT [Hong et al., 2023]、CrewAI等现代多智能体框架中,每个Agent拥有专门角色,通过消息传递协作,最终涌现出超越单体智能的系统行为——这与Minsky六十年前的构想异曲同工。
1.3.3 学习范式的三次飞跃
如果智能无法被完全设计,那么它是否可以被学习出来?这一设问开启了人工智能的"学习"时代。
第一次飞跃:联结主义——从规则到感知
联结主义(Connectionism)在20世纪80年代重新兴起,作为对符号主义局限性的直接回应。其核心转变体现在三个层面:
- 知识表示:从显式的符号规则 → 分布式的连接权重。
- 处理单元:从统一的逻辑推理机 → 大量简单的人工神经元。
- 能力获取:从手工编码 → 通过学习自动调整权重。
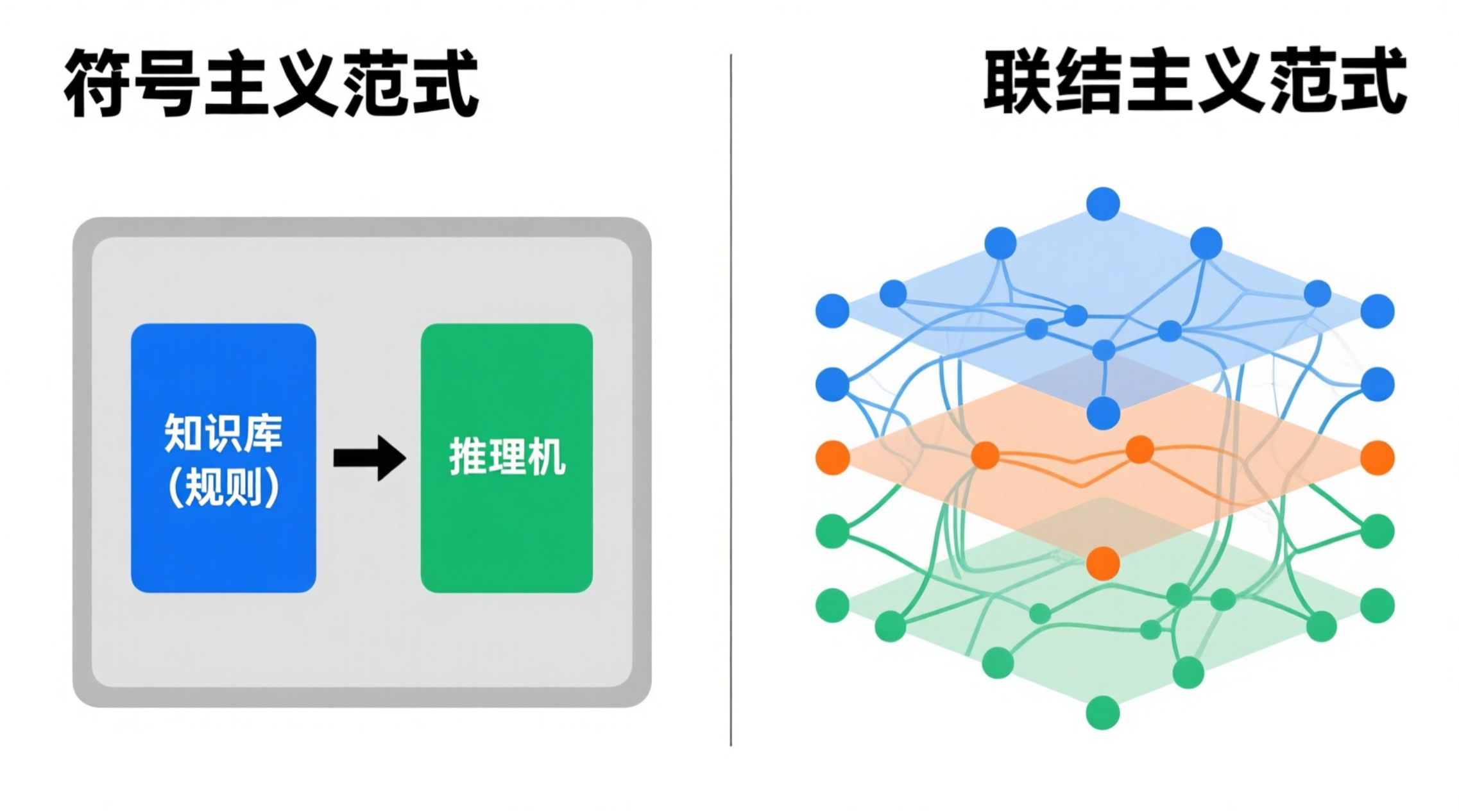
联结主义赋予了智能体强大的感知和模式识别能力,使其能够直接从原始数据中理解世界。但它主要解决了"这张图片里有什么?"这类感知问题,而非"在这种情况下,我应该做什么?"这类决策问题。
第二次飞跃:强化学习——从感知到决策
强化学习(RL)专注于解决序贯决策问题。它并非从标注数据中学习,而是通过智能体与环境的直接交互,在"试错"中学习最优策略。
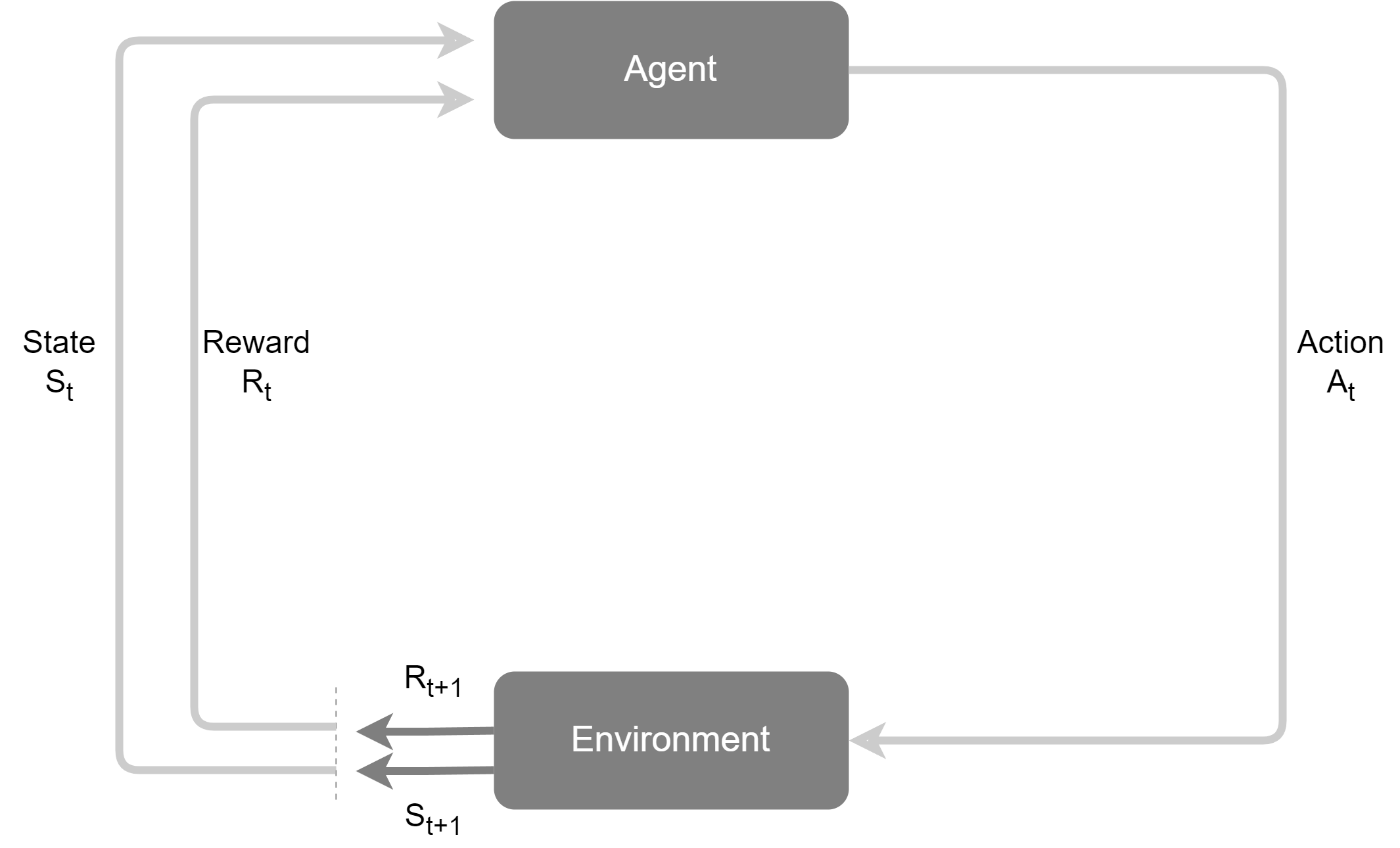
强化学习的框架包含五个核心要素:智能体(Agent)、环境(Environment)、状态(State)、行动(Action)和奖励(Reward)。以AlphaGo为例,智能体通过数百万次自我对弈,不断调整内部策略,学会了在各种棋局下选择最可能导向胜利的行动。
强化学习的关键价值在于:智能体的学习目标不是最大化某一步的即时奖励,而是最大化从当前到未来的累积奖励。这意味着智能体需要具备"远见"——有时为了获得更大的长期收益,需要牺牲当前的即时奖励。
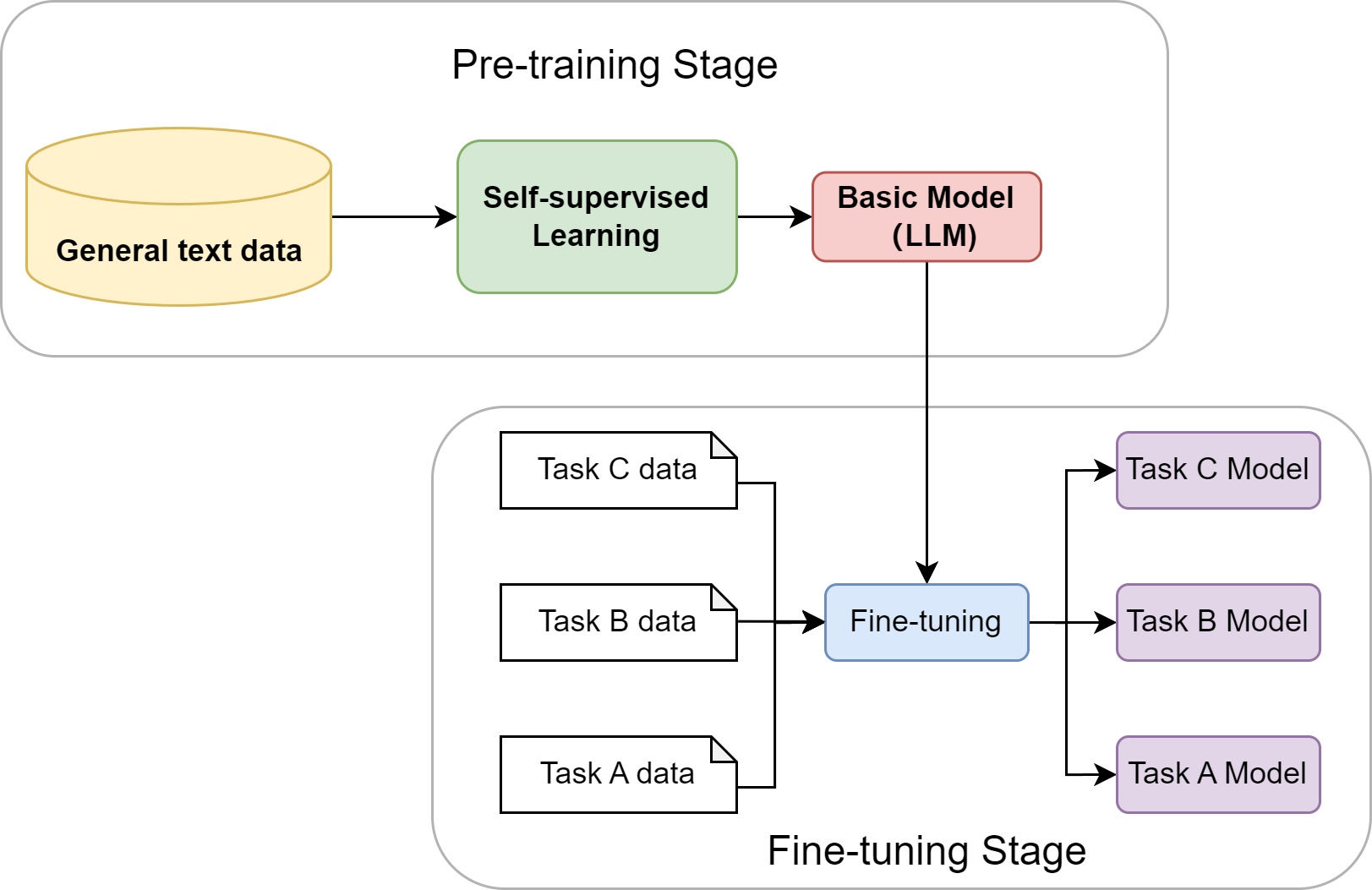
第三次飞跃:大规模预训练——从任务特定到通用能力
预训练范式彻底改变了AI系统获取知识的方式:
- 预训练阶段:在互联网级别的海量文本上,通过自监督学习训练超大规模模型。目标是学习语言本身的规律、语法结构、事实知识以及上下文逻辑。
- 微调阶段:使用少量特定任务的标注数据对模型进行适配。
当模型规模跨越某个阈值后,它们开始展现出未被直接训练的涌现能力:上下文学习(In-context Learning)、思维链推理(Chain-of-Thought)[Wei et al., 2022] 等。研究表明,缩放法则(Scaling Laws)可以预测模型性能随参数量的幂律增长 [Kaplan et al., 2020],而Chinchilla定律进一步指出最优模型应比此前认为的更小、但用更多数据训练 [Hoffmann et al., 2022]。这标志着LLM不再仅仅是一个语言模型,它已经演变成了兼具海量知识库和通用推理引擎双重角色的组件。
1.3.4 LLM驱动的智能体:历史的综合
多项综述工作系统性地梳理了LLM驱动智能体的架构与能力 [Wang et al., 2024; Xi et al., 2023]。LLM驱动的智能体是上述所有历史范式的综合产物。它通过一个由多个模块协同工作的闭环流程来完成任务:
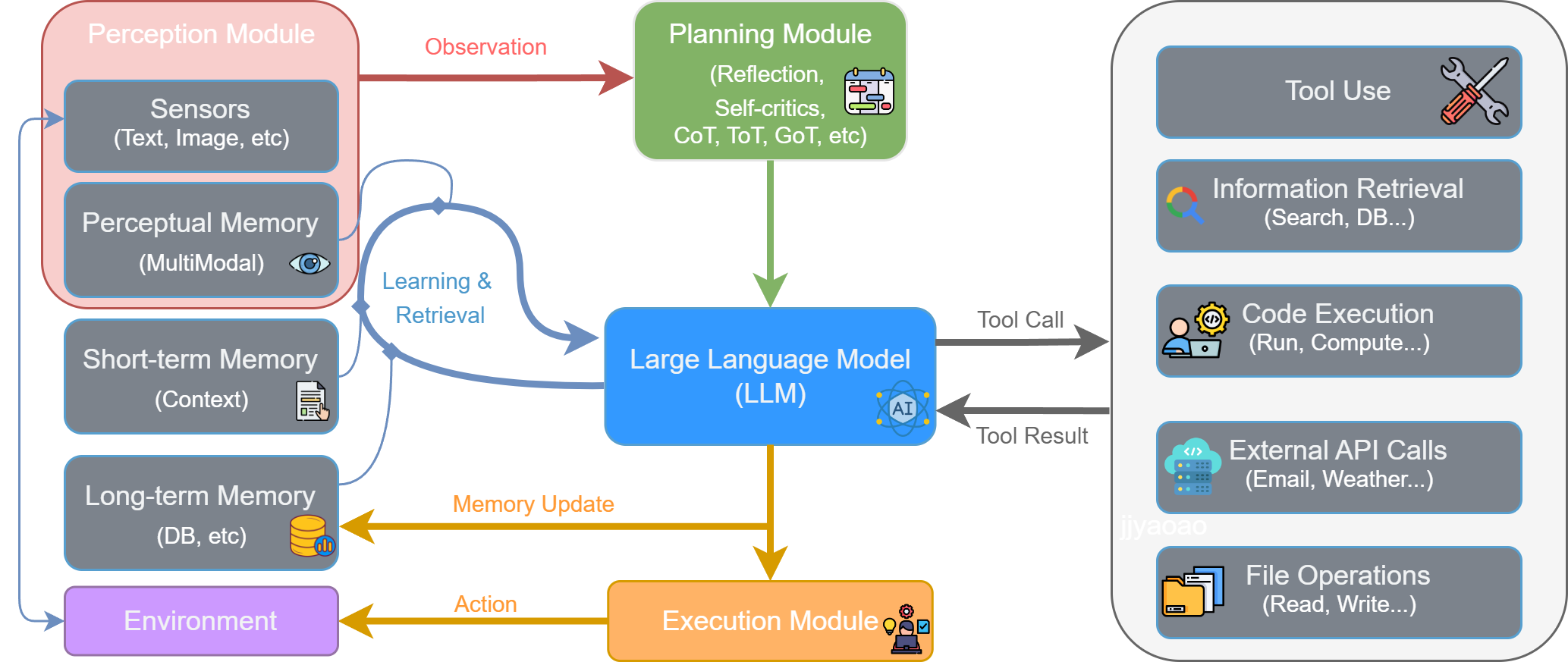
- 感知(Perception):感知模块从外部环境接收原始输入,形成观察(Observation)。
- 思考(Thought):规划模块进行高级策略制定,LLM作为中枢进行深度推理,与记忆模块交互整合历史信息。
- 行动(Action):执行模块从工具箱中选择并调用合适的工具与环境交互。
- 观察与循环:工具结果和新的环境状态构成新的观察,启动下一轮循环。
从架构层面看,这个设计综合了多种历史遗产:
| 历史范式 | 在现代智能体中的体现 |
|---|---|
| 符号主义的知识推理 | LLM以自然语言进行链式推理、规划和工具选择 |
| 心智社会的分布式协作 | 多智能体系统中的角色分工与消息传递 |
| 联结主义的感知能力 | 多模态LLM对文本、图像、音频的理解 |
| 强化学习的决策优化 | RLHF训练使LLM与人类意图对齐 [Ouyang et al., 2022] |
| 预训练的通用知识 | 万亿级语料预训练提供的世界知识 [Brown et al., 2020] |
关键实现决策 —— 工程实践中的核心选择点
在构建基于历史范式理解的智能体时,工程师面临以下关键决策:
决策1:规则系统 vs. LLM推理
尽管LLM驱动的智能体是当前的主流范式,但在某些垂直领域(如工业控制、医疗合规检查),基于规则的专家系统因其可解释性和确定性仍然是更优选择。设计决策应基于任务特性:规则明确且变化缓慢的领域优先考虑规则系统;规则模糊、需要泛化能力的领域选择LLM。
决策2:单体智能体 vs. 多智能体系统
心智社会的遗产提醒我们:去中心化并非总是更优。单体智能体架构更简单、延迟更低、调试更容易;多智能体系统在需要并行探索、角色专业化、上下文隔离的场景下才展现优势。过早引入多智能体会增加不必要的通信开销和协调复杂性。
决策3:端到端学习 vs. 模块化组合
纯端到端学习(如直接让RL训练一个从感知到行动的策略网络)与模块化组合(如将LLM、RAG、工具调用显式拆分)各有优劣。当前主流实践倾向于模块化组合:LLM作为推理核心,其他能力通过工具和记忆模块外挂。这种架构的优势在于每个模块可独立升级、测试和替换。
前沿动态 —— 学术界/工业界最新进展
神经-符号融合
当前一个重要趋势是神经网络与符号推理的再次融合。LLM通过自然语言实现了"神经-符号"桥梁:它以神经网络为底层实现,却能在输出层面进行类似符号操作的逻辑推理、代码生成和结构化规划。这种融合并非简单的混合,而是一种范式跃迁——符号操作不再需要手工编码,而是从大规模数据中涌现。
Agentic RL的兴起
强化学习正在从训练游戏AI和机器人控制的传统领域,向训练LLM智能体的方向演进。通过将Agent在真实环境中的交互轨迹作为训练信号,研究者正在探索如何让LLM智能体像AlphaGo一样,通过"自我对弈"不断提升其规划和工具使用能力。
技术栈的快速成熟

如图1.12所示,AI Agent领域的技术栈正在快速成熟,从底层模型到上层应用的各个环节都在经历标准化。这种生态的成熟为智能体开发降低了门槛,也为跨系统互操作创造了条件。
本章小结
本章回顾了智能体发展的历史脉络,揭示了从符号主义到LLM Agent的范式演进逻辑:
- 符号主义奠定了"知识+推理"的架构模板,但在知识获取和系统脆弱性上遇到了根本性瓶颈。
- 心智社会理论将视角从单体智能转向分布式协作,预言了多智能体系统的核心设计原则。
- 联结主义赋予智能体感知世界的能力,强化学习赋予其决策能力,大规模预训练赋予其通用知识和涌现推理能力。
- LLM驱动的智能体是上述所有范式的综合,在一个统一架构中实现了知识推理、感知理解、决策规划和工具使用的融合。
理解这一演进历程,不仅帮助我们理解现代智能体"从何而来",更重要的是理解其设计选择背后的深层逻辑。每一种历史范式的优势和局限,都在现代智能体的架构中留下了印记——符号主义的可解释性需求催生了思维链推理,心智社会的协作思想演化为多智能体框架,学习范式的进步则提供了从感知到决策的全栈能力。
⚠️ 已知局限:历史范式的综合并不意味着所有问题都已解决。LLM驱动的智能体在需要严格形式化验证的场景(如数学证明、安全关键系统)中仍然不可靠——其"推理"本质上是概率预测而非逻辑演算。此外,当任务需要超出训练分布的全新知识组合时,涌现能力可能完全失效,智能体会产生看似合理但实际错误的输出(幻觉问题)。
下一章将聚焦于这一架构中最核心的组件——大语言模型本身,深入探讨其能力边界和作为智能体认知核心的架构角色。