第16章 上下文的解剖学:组件与信号
本章来源:综合自 Hello-Agents 第九章(上下文工程的有效解剖学与信号密度分析)、ce101(上下文工程技术栈全景与问题分类)
核心问题 —— 本章要解答什么
"上下文"是大语言模型在推理时唯一可见的信息。训练阶段获得的能力是固定的、不可改变的;上下文则是运行时唯一的可调变量。这意味着:如果上下文构造不当,即使模型能力再强,也无法产出期望的结果。
本章的核心问题是:上下文究竟由哪些组件构成?每种组件的信号密度和注意力消耗特征如何?如何在有限的上下文窗口内,用尽可能少但信号密度高的tokens,最大化获得期望结果的概率?
Andrej Karpathy对上下文工程的定义是:"在上下文窗口中填入恰到好处的信息以支撑下一步行动的精细艺术与科学。"本章将这一抽象定义具象化为可操作的组件清单和工程原则。
设计空间 —— 可选方案与取舍
上下文工程 vs 提示工程
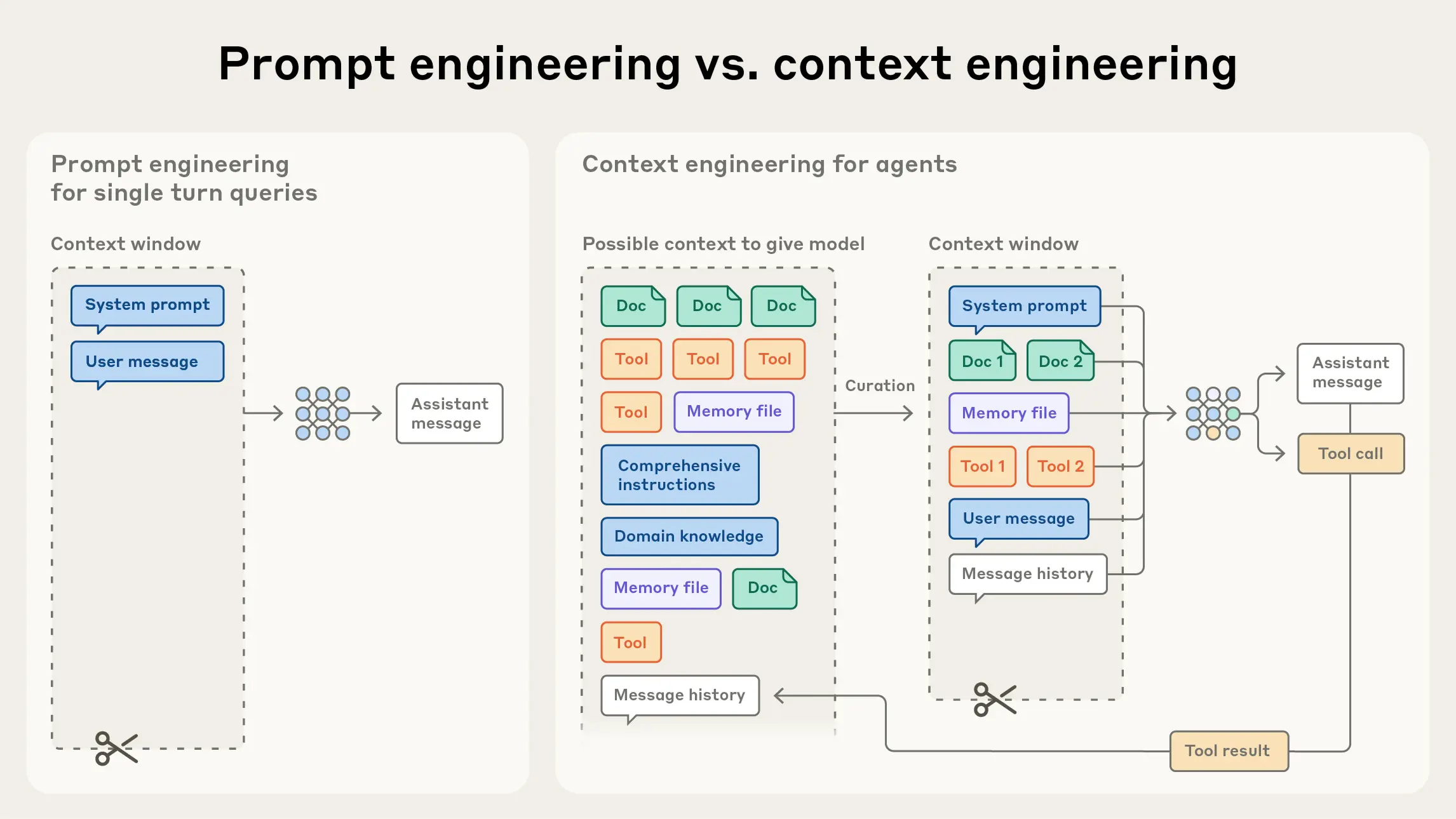
提示工程关注的是"如何编写有效的指令"——系统提示的措辞、结构化策略、少样本示例的选择。它本质上是一种静态、单轮、指令导向的方法论。
上下文工程则是提示工程的自然演进。它关注的是在推理阶段,如何策划与维护"最优的信息集合(tokens)"。这个信息集合不仅包含提示本身,还包含工具定义、外部检索数据、消息历史、记忆状态等一切进入上下文窗口的内容。
两者的关键差异:
| 维度 | 提示工程 | 上下文工程 |
|---|---|---|
| 关注范围 | 系统提示的编写 | 整个上下文状态的管理 |
| 时间尺度 | 单轮交互 | 跨多轮、长时程 |
| 信息来源 | 人工编写 | 多源动态获取 |
| 典型方法 | 零样本/少样本/思维链 | RAG + 工具 + 记忆 + 压缩 |
| 适用场景 | 封闭任务、结构化回答 | Agent、多步推理、复杂任务 |
上下文窗口的本质约束
当前SOTA模型的上下文窗口在1M tokens以内。这个窗口就像CPU的内存——理论上越大越好,但实际使用中存在边际收益递减。上下文窗口带来的四种典型场景:
- 上下文太长,超过窗口限制:需要压缩或裁剪
- 上下文太短,不足以支撑推理:需要增强(RAG、工具调用)
- 上下文在窗口内但过长:效果可能反而下降
- 上下文适中:理想状态
核心认知是:更大的上下文不一定是更好的选择。上下文必须被视作一种有限资源,且具有边际收益递减。
架构解析 —— 深入分析上下文的构成
16.1 上下文的组件清单
一个完整的智能体上下文由以下组件构成:
16.1.1 系统提示(System Prompt)
系统提示定义了模型的角色、行为准则和输出格式。它是上下文中信号密度最高的组件——每一个token都直接影响模型的行为模式。
优秀系统提示的设计原则:
- 语言清晰、直白,信息层级把握在"刚刚好"的高度
- 分区组织,用XML/Markdown分隔不同类型的信息
- 追求能完整勾勒期望行为的"最小必要信息集"("最小"并不等于"最短")
常见的两极误区:
- 过度硬编码:在提示中写入复杂、脆弱的if-else逻辑,长期维护成本高、易碎
- 过于空泛:只给出宏观目标与泛化指引,缺少对期望输出的具体信号
建议先用最好的模型在最小提示上试跑,再依据失败模式增补清晰的指令与示例。
16.1.2 工具定义(Tools)
工具定义了智能体与信息/行动空间的契约。工具设计的核心原则是促进效率:既要返回token友好的信息,又要鼓励高效的智能体行为。
工具应当:
- 职责单一、相互低重叠,接口语义清晰
- 对错误鲁棒
- 入参描述明确、无歧义
常见失败模式是"臃肿工具集":功能边界模糊,导致"选哪个工具"这一决策本身就含混不清。**如果人类工程师都说不准用哪个工具,别指望智能体做得更好。**精心甄别一个"最小可行工具集(MVTS)"往往能显著提升长期交互中的稳定性。
DeepSeek-v3的实践验证了这一原则:当可用工具数量超过30个时,工具描述开始互相重叠导致混淆;超过100个时,模型几乎必然无法通过测试。利用RAG技术将工具数量筛选到30个以内,可以显著缩短提示长度并将工具选择准确率提升多达3倍。
16.1.3 示例(Few-shot Examples)
始终推荐提供示例,但要精挑细选一组多样且典型的示例,直接画像"期望行为"。不建议把"所有边界条件"的罗列一股脑塞进提示——对LLM而言,好的示例胜过千言万语。
在Agent场景中,少样本示例需要谨慎使用。Manus团队发现:如果上下文中充满了相似的"动作-观察"对,模型会倾向于模仿这种模式,即便该行为已不再是最优选择。解决方法是引入多样性——使用不同的序列化模板、替换措辞、在顺序或格式上加入细微扰动。
16.1.4 消息历史(Message History)
多轮对话的历史记录构成了上下文中增长最快的部分。随着对话轮次增加,消息历史会逐渐占据大量的token预算。
消息历史的信号密度通常不均匀:最近的几轮对话包含最相关的上下文,而早期的对话可能已经过时或冗余。这一特性为后续的压缩策略提供了依据。
16.1.5 检索上下文(Retrieved Context)
通过RAG或工具调用注入的外部信息。这部分内容的质量直接影响模型的回答准确性——高相关性的检索结果是增益,低相关性的检索结果则是噪声。
16.1.6 运行时状态(Runtime State)
包括任务进度、待办事项、目标清单等动态信息。Claude Code和Manus都使用TODO列表来锚定模型的注意力,确保在长对话中不偏离任务目标。
16.2 信号密度与注意力预算
16.2.1 注意力预算的概念
LLM的注意力机制让每个token能够与上下文中的所有token建立关联,理论上形成n^2级别的两两关系。随着上下文长度增长,模型对这些关系的建模能力会被"拉薄",自然产生"上下文规模"与"注意力集中度"的张力。
这意味着每新增一个token,都会消耗注意力预算的一部分。
注意力预算可以用注意力得分分布来量化理解。在标准 Transformer 中,给定查询 token
随着
上下文工程的核心目标就是:在有限的注意力预算内,让每个token都贡献最大的信息价值。
16.2.2 上下文腐蚀(Context Rot)
Chroma的技术报告揭示了一个关键现象:上下文腐蚀——随着上下文窗口中的tokens增加,模型从上下文中准确回忆信息的能力反而下降。
即便是简单的文本重复任务,随着输入长度增加,模型的输出质量也呈现下降趋势。更重要的是,当语料库中增加相似文本时,效果会进一步恶化——相似但非目标的内容会分散模型的注意力。
这一发现有深远的工程意义:在实际应用中不应盲目追求更多的上下文,而是要追求最好、最合适的上下文。 最初的上下文带来的增量收益最好,随后收益递减甚至可能转负。
Chroma 的实验数据提供了具体的衰减曲线:在 128K 上下文窗口中,当填充率从 10% 增加到 50% 时,信息召回准确率从 ~95% 下降到 ~80%;从 50% 增加到 90% 时进一步下降到 ~60%。更关键的是,增加相似但非目标的内容(如同一主题的不同文档)比增加无关内容造成的性能下降更严重——前者导致约 15% 的额外准确率损失,因为相似内容直接竞争模型的注意力资源。
16.2.3 信号密度的量化思维
定义(信号密度):给定上下文
其中
虽然信号密度难以精确量化,但可以从以下维度评估每个上下文组件的价值:
| 组件类型 | 典型信号密度 | 注意力消耗特征 | 管理策略 |
|---|---|---|---|
| 系统提示 | 极高 | 恒定(每次推理都需要) | 精炼但不简化 |
| 工具定义 | 高 | 随工具数增长 | 最小可行工具集 |
| 少样本示例 | 高(但有饱和) | 随示例数增长 | 3-5个多样性示例 |
| 最近对话 | 高 | 随轮次增长 | 保留最近N轮 |
| 历史对话 | 递减 | 持续占据空间 | 压缩或摘要 |
| 检索结果 | 取决于检索质量 | 随结果数增长 | 重排序+截断 |
| 工具输出 | 极不均匀 | 可能非常大 | 及时清理 |
16.3 上下文工程的技术栈
上下文涉及的技术手段可以划分为三个类别:
16.3.1 上下文增强(Context Augmentation)
主要目的是补充信息,使模型获得完成任务所需的知识和指令:
- 提示词技术(Prompting):系统提示的设计和优化
- RAG:从外部知识库检索相关信息注入上下文
- 工具集成与函数调用(MCP):通过外部工具获取实时数据或执行操作
16.3.2 上下文优化(Context Optimization)
主要目的是清洗和优化上下文,提升信号密度:
- 上下文隔离:将复杂任务分配给不同的智能体,每个智能体拥有独立的上下文窗口
- 上下文修剪:移除无关或冗余的信息
- 上下文压缩:对历史内容进行摘要,保留关键信息
16.3.3 上下文持久化(Context Persistence)
主要目的是保留信息,实现跨会话的知识延续:
- 会话记忆:保存对话中用户提到的关键信息
- 任务状态保存:Agent正在处理的流程可以断点恢复
- 用户偏好记录:个性化设置的长期存储
关键实现决策 —— 工程实践中的关键选择点
16.4 结构化上下文模板
Hello-Agents的ContextBuilder将上下文组织为六个标准分区:
[Role & Policies] - 角色定位和行为准则
[Task] - 当前需要完成的具体任务
[State] - Agent的当前状态和上下文信息
[Evidence] - 从外部知识库检索的证据信息
[Context] - 历史对话和相关记忆
[Output] - 期望的输出格式和要求这种分区设计的优势:
- 可读性:清晰的分区让人类和模型都更容易理解上下文结构
- 可调试性:问题定位更容易,可以快速识别哪个区域的信息有问题
- 可扩展性:添加新的信息源只需要创建新的分区
- A/B测试:可以针对特定分区进行实验和优化
16.5 注意力锚定策略
长对话中最大的挑战是模型的注意力偏移——随着上下文不断累积,模型可能忘记最初的目标和指令。
Claude Code和Manus都采用了相同的策略来应对这一问题:通过不断重写TODO列表,将任务目标"复述"到上下文的结尾处。这样做可以把全局计划强行推入模型最近的注意力范围,避免"上下文中段丢失"问题,同时减少目标偏移。
Manus的描述尤为精辟:
这不是一种"可爱"的行为,而是一种有意设计的注意力操控机制。典型任务平均需要调用大约50次工具——在如此长的执行链中,模型容易出现跑题或忘记最初目标的问题。通过不断地重写待办清单,实质上是在用自然语言主动引导模型关注核心任务目标——无需修改模型结构,就能实现注意力的偏置。
16.6 渐进式披露(Progressive Disclosure)
允许智能体自主导航与检索能实现渐进式披露:每一步交互都会产生新的上下文,反过来指导下一步决策——文件大小暗示复杂度、命名暗示用途、时间戳暗示相关性。
智能体得以按层构建理解,只在工作记忆中保留"当前必要子集",并用"记笔记"的方式做补充持久化,从而维持聚焦而非"被大而全拖垮"。
前沿动态 —— 学术界/工业界最新进展
上下文工程作为新学科
2025年,上下文工程从一系列分散的实践技巧正式凝聚为一个学科概念。Karpathy在Y Combinator Startup School的演讲中将LLM类比为新一代操作系统,上下文窗口是它的RAM,而上下文工程是调度器——负责把最重要的信息装进有限的内存中。
这一类比揭示了上下文工程的本质:它不是关于"写好提示词"的技巧,而是关于"为模型构建最优认知环境"的系统工程。训练和微调决定了模型的能力上限,上下文工程则决定了模型能发挥出多少能力。
MCP协议与工具生态
Anthropic在2024年11月推出的MCP(Model Context Protocol)正在标准化模型与外部环境的交互。MCP的出现使得工具调用从各家厂商的私有实现走向统一标准,催生了可共享的工具生态系统。但随着MCP的普及,客户端可能挂载数十甚至上百个工具,工具的治理(而非仅仅是接入)已经成为上下文工程的重要研究方向。
本章小结
本章对上下文进行了系统性的"解剖",明确了其六大组件(系统提示、工具定义、示例、消息历史、检索上下文、运行时状态)的信号密度和注意力消耗特征。核心认知是:上下文是一种有限资源,具有边际收益递减特性,更多不等于更好。
上下文工程的技术栈可以从增强、优化、持久化三个维度理解。在工程实践中,结构化模板、注意力锚定和渐进式披露是最关键的设计策略。
⚠️ 已知局限:信号密度的概念虽然直观,但在实践中难以精确量化。当前缺乏可靠的自动化工具来评估上下文中每个token的实际贡献度。此外,注意力锚定策略(如TODO列表刷新)本身也消耗上下文空间——在典型的50步工具调用任务中,TODO列表的反复更新可能占据15-20%的总token预算。当工具返回大量结构化数据(如数据库查询结果)时,目前缺乏有效的自动裁剪机制,开发者仍需手动设计每种工具输出的精简策略。
下一章将深入上下文管理的阴暗面——当上下文出错时会发生什么?污染、干扰与压缩技术如何应对这些挑战?