第17章 上下文管理:污染、干扰与压缩
本章来源:综合自 Practical Guide to Context Engineering(上下文污染/干扰/压缩的工程实践)、Hello-Agents 第九章(上下文工程理论框架)
核心论点:更长的上下文窗口不会自动带来更好的结果。上下文是一种有限资源,具有边际收益递减的特性。当上下文失控——被污染、被干扰、发生冲突——时,智能体会以难以察觉的方式失败。本章系统剖析上下文失败的四种模式,并给出从架构设计到压缩算法的完整管理方案。
17.1 核心问题:为什么上下文会"变坏"
在第16章中,我们将上下文解构为六大组件,并引入了信号密度和注意力预算的概念。那一章回答的是"上下文由什么构成";本章要回答的是"上下文如何崩溃,以及如何修复"。
一个直觉是:既然模型的上下文窗口在持续扩大(GPT-5 达到 400K tokens,Gemini 2.5 Pro 达到 1M tokens),那么只要窗口足够大,把所有信息都塞进去不就行了吗?
实际上,这种"杂货抽屉"策略几乎必然失败。Chroma 的技术报告 Context Rot 明确指出:大语言模型被假设能均匀处理上下文中的每一个 token,但这一假设不成立——即便在简单任务上,随着输入长度的变化,模型表现会出现显著差异。Databricks 的研究进一步证实:使用更长的上下文并不总能提升 RAG 的表现;小参数模型的准确率在上下文增长后甚至会不升反降,而 SOTA 模型虽然抗干扰能力更强,但准确率的提升也会在某个点之后趋于平缓。
Gemini 2.5 技术报告在描述其自主通关宝可梦游戏的实验时,明确记录了这一现象:当上下文显著超过 10 万 token 时,智能体倾向于重复其历史中的动作,而不是生成新的计划。这不是个别现象,而是 Transformer 注意力机制的结构性约束:每个 token 与上下文中所有 token 建立关联,随着上下文增长,模型对这些两两关系的建模能力被"拉薄"。
因此,上下文管理不是可选的优化,而是构建可靠智能体的必修课。
17.2 设计空间:上下文失败的四种模式
Drew Breunig 提出了四种上下文失败模式的经典分类。我们在此基础上结合 ce101 的三维分类框架,将其组织为一个完整的故障图谱。
17.2.1 上下文污染(Context Poisoning)
定义:幻觉或其他错误信息进入上下文,并被模型反复引用,导致持续的错误行为。
污染的危险之处在于其自我强化特性。一旦错误信息进入上下文(无论是通过工具调用的错误返回、记忆模块的误解、还是模型自身的幻觉),它会被后续的推理步骤反复引用,形成一个正反馈的"毒化循环"。
典型场景一:用户记忆污染
在记忆系统中,LLM 会对用户输入的历史记录进行整理和归纳。但如果在整理过程中发生误解,错误的记忆就会被持久存储。例如,用户一次情绪化的表达——"这节课烦死了,根本没用"——可能被系统整理为"用户认为《课程 C》没有价值"。后续检索时,这条记忆会反复伴随相关查询出现,在长期交互中持续误导模型。
问题在于:(1) 用户可能后来改变了态度,那次表达可能只是当时心情糟糕;(2) "这节课"可能指的是某个知识点而非整个课程体系。
典型场景二:工具调用错误的级联传播
当工具调用返回错误时,许多系统会触发重试机制。但如果错误信息的设计不够精确——即 LLM 接收到的错误消息并不能准确反映工具出错的真正原因——模型就会在"错误"中反复重试,每一次重试都在上下文中积累更多的错误信息,进一步污染后续的决策。
典型场景三:宝可梦游戏中的上下文投毒
Gemini 2.5 技术报告描述了一个极其生动的案例:在自主玩宝可梦游戏时,大量关于游戏状态的错误信息被写入上下文(包括目标设定、状态总结等),导致模型执着于实现根本不可能的目标。更严重的是,这种污染会导致模型采取极端策略——例如"黑屏策略":故意让所有宝可梦昏迷以传送回宝可梦中心,而不是尝试正常离开当前区域。尽管这些行为对人类来说明显荒谬,但由于错误信息在上下文中大量存在,模型会忽视常识,不断重复错误判断。
17.2.2 上下文干扰(Context Distraction)
定义:当上下文变得过长时,模型过度关注上下文中的信息,忽视了在训练期间学到的内容。
干扰与污染的区别在于:污染是信息本身有误,而干扰是信息太多——即使所有信息都是正确的,过多的上下文依然会"淹没"模型的推理能力。
注意力的稀释效应
Transformer 的注意力机制让每个 token 与上下文中所有 token 建立关联。上下文越长,模型需要建模的两两关系越多(理论上是
干扰导致模式固化
在代理的工作流程中,随着上下文增长,模型会收集越来越多的历史动作记录。这些累积的上下文可能会让模型过度关注过去的行为模式,而较少利用其训练获得的策略能力。对于需要创造性输出的智能体,这尤其危险——模型的输出会趋于"固化",且是较低质量的固化。
Manus 团队在实践中观察到了同样的现象:语言模型擅长模仿上下文中呈现的行为模式。当上下文充满了相似的"动作-观察"对时,模型会机械地遵循这些模式,即便这些行为已不再是最优选择。例如,让 Manus 帮助审阅 20 份简历时,智能体很容易陷入"节奏"——重复执行同样的操作,导致漂移、过度泛化甚至幻觉。
指令淹没
Databricks 的研究识别出长上下文导致的几种失败模式:重复内容(无意义的词语重复)、随机内容(与主题完全无关的生成)、未遵循指令(模型忽略了系统提示中的要求,转而去做其他事情)以及错误回答。其中"未遵循指令"直接说明:过长的上下文会导致系统提示中的指令和目标被"淹没",使模型忽略关键约束。
17.2.3 上下文混淆(Context Confusion)
定义:模型使用上下文中多余的或不相关的内容来生成低质量的响应。
与干扰的区别在于:干扰是信息总量过多导致注意力稀释;混淆是特定的无关信息被模型当作有效输入。
工具定义混淆
在工具调用场景中,工具定义是必须传入 LLM 的。但过多的无关工具和模糊的工具描述会导致模型在选择工具时变得混乱。DeepSeek-v3 的提示工程实践表明:当可用工具数量超过 30 个时,工具描述开始互相重叠,导致选择准确率下降;超过 100 个时,模型几乎无法正确选择工具。
相似文本的干扰效应
Chroma 的研究通过控制实验展示了一个关键发现:在上下文长度固定的情况下,增加与目标答案相似但不同的干扰文本,会显著降低模型的准确率。这意味着上下文中的"噪声"不仅仅是"占用空间"那么简单——语义上相似的无关信息对模型注意力的干扰效果远大于完全不相关的内容。
17.2.4 上下文冲突(Context Clash)
定义:上下文中新加入的有效信息与已有信息产生矛盾或冲突。
冲突与混淆的关键区别在于:混淆中的信息是无用的,而冲突中的信息都是有效的——只是它们彼此矛盾。
多智能体场景中的冲突
这在多智能体架构中最为常见。由于多个智能体的上下文彼此独立,它们可能基于不同的信息来源得出矛盾的结论。当主智能体并行调用子智能体 B 和 C 进行信息检索时,B 和 C 可能返回相互冲突的结果。这些冲突的信息汇合后输入主智能体,输出质量就会显著下降。
新旧信息的冲突
在长时程任务中,外部世界的状态可能在任务执行期间发生变化。如果上下文同时包含了"旧状态"和"新状态"的信息,模型可能无法判断哪个版本是当前有效的。
17.3 架构解析:上下文管理的策略体系
识别了四种失败模式之后,我们需要一个系统性的管理策略。这些策略并非相互排斥,而是构成一个层次化的防御体系。
17.3.1 策略一:RAG——按需注入相关上下文
检索增强生成是上下文管理的第一道防线:不要把所有信息塞入上下文,而是选择性地添加与当前任务相关的信息。
RAG 的核心价值在于将"上下文的组装"从"人工预设"转变为"动态检索"。每当上下文窗口上限增加时,就会诞生一场新的"RAG 已死"的争论,但 RAG 的作用从来不只是"克服窗口限制"——它更是一种信号密度的保证机制。即使窗口可以容纳所有信息,RAG 依然有价值,因为它确保了进入上下文的信息是经过筛选的高相关性信息。
关于 RAG 的技术细节,我们在第14-15章已经做了系统的介绍。这里强调的是 RAG 在上下文管理中的定位:它不是"获取信息"的工具,而是"控制信息质量"的闸门。
17.3.2 策略二:工具配置与定义优化
工具定义是上下文中容易被忽视的"噪声源"。优化策略包括:
工具描述的 RAG 化:将工具描述存储到向量数据库中,根据用户输入检索最相关的工具子集,而非将全部工具定义一次性注入。如前所述,DeepSeek-v3 的经验表明,利用 RAG 将工具数量筛选到 30 个以内,可以显著缩短提示长度,并将工具选择的准确率提升多达 3 倍。
边界清晰的工具设计:如果工具数量不多且边界清晰,完整提供工具定义反而效果更好。关键是确保每个工具的职责单一、相互低重叠、接口语义无歧义。正如 Hello-Agents 所言:"如果人类工程师都说不准用哪个工具,别指望智能体做得更好。"
17.3.3 策略三:上下文隔离(Context Quarantine)
定义:将上下文隔离到各自专用的线程中,每个线程由一个或多个 LLM 独立使用。
当上下文既长又全部有效(无法裁剪)时,隔离是最有效的策略。核心思想是将大任务分解为更小、更隔离的子任务,每个子任务拥有独立的上下文窗口。
Anthropic 的博客文章对此有精确的描述:
搜索的本质是压缩:从庞大的语料库中提炼见解。子代理通过并行操作自己的上下文窗口来促进压缩,在将最重要的标记压缩给主要研究代理之前,同时探索问题的不同方面。
这种多智能体的上下文隔离架构带来了多重好处:(1) 每个子代理拥有"干净的"上下文窗口,避免了信息的交叉污染;(2) 主代理只需处理来自子代理的凝练摘要(通常 1,000-2,000 tokens),而非原始的庞大上下文;(3) 可以为不同子代理配置专属的工具集,避免工具定义的混淆。
Anthropic 的内部评估显示,以 Claude Opus 4 为主智能体、Claude Sonnet 4 为子智能体的多智能体系统,在内部研究评估中比单智能体 Claude Opus 4 表现高出 90.2%。
17.3.4 策略四:上下文修剪(Context Pruning)
定义:在将上下文正式输入给 LLM 之前,对上下文内容进行评估并移除冗余部分。
修剪的核心理念是"在正式推理之前做一次预处理"。当智能体通过工具调用和信息积累组装了大量上下文时,在调用 LLM 之前进行内容评估并移除冗余部分是值得的——这不仅让上下文更精简,也能释放模型更大的推理能力。
具体的修剪技术——Token 压缩策略——将在 17.4 节详细介绍。
17.3.5 策略五:上下文总结(Context Summarization)
定义:将累积的上下文浓缩成简要摘要。
当上下文(尤其是会话历史记录)超过最大上下文长度时,可以使用 LLM 生成简短摘要。总结的核心要求是在压缩的同时保留关键信息——架构决策、未解决的问题、用户偏好等。
总结与修剪的区别在于:修剪是物理删除不重要的消息;总结是语义压缩,用更少的 token 表达相同的核心信息。两者常常配合使用。
17.3.6 多样性注入:打破模式固化
针对上下文干扰导致的模式固化,Manus 提出了一个巧妙的解决方案:在动作和观察中加入少量有结构的变化——不同的序列化模板、替换措辞、在顺序或格式上加入细微扰动。这种"可控的随机性"有助于打破固定模式,重新调整模型的注意力焦点。
这个策略的本质是:上下文越单一、越一致,智能体就越脆弱。通过刻意引入多样性,可以防止模型陷入循环圈套。
17.4 关键实现决策:上下文压缩的工程实践
上下文压缩是上下文管理中工程复杂度最高的部分。本节从两个维度展开:基于 LLM 的摘要压缩,和基于算法的消息删除压缩。
17.4.1 上下文管理容器的整体架构
一个完整的上下文管理系统需要处理四个核心流程:
消息添加流程:添加用户/助手/工具消息 → 调用通用消息处理方法 → 消息格式验证 → 存储到多后端数据库 → 更新 Token 总数。
LLM 获取上下文流程:获取系统提示词 → 从数据库获取会话历史 → 判断是否需要压缩 → 消息格式化为 LLM API 格式 → 传入 LLM 执行。
Token 压缩流程:判断是否有必要压缩 → 选择压缩策略 → 执行压缩 → 保留压缩历史记录到数据库。
消息格式化流程:获取 LLM 提供商 → 调用特定提供商的格式化方法 → 统一内部消息格式到 API 消息格式。
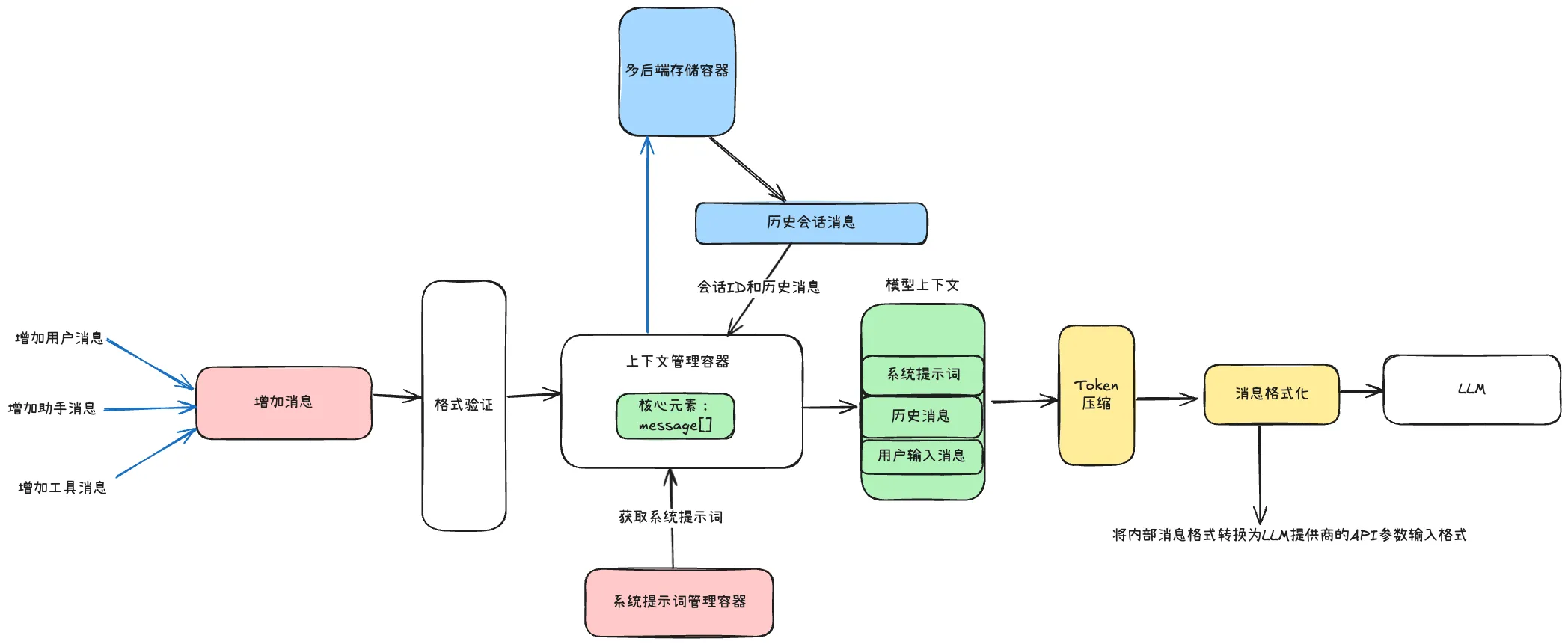
这个容器设计的关键决策在于:压缩历史记录的持久化存储。保留最近 10 次压缩操作的详细记录,用于监控、分析和优化,这使得压缩不再是一个"黑箱"操作。
17.4.2 基于 LLM 的摘要压缩:Claude Code 的方案
Claude Code 直接使用模型来生成总结摘要以压缩上下文。Anthropic 在工程分享文章中描述了这一思路:
在 Claude Code 中,我们通过将消息历史传递给模型来实现这一点,以总结和压缩最关键的信息。模型保留架构决策、未解决的错误和实现细节,同时丢弃冗余的工具输出或消息。
Claude Code 的 /compact 命令使用了一个精心设计的 9 段式压缩提示词,要求模型从以下九个维度保留关键信息:
| 维度 | 保留内容 | 工程价值 |
|---|---|---|
| 主要请求和意图 | 用户的所有明确请求 | 确保压缩后目标不偏移 |
| 关键技术概念 | 技术、框架、设计决策 | 重建开发环境的上下文 |
| 文件和代码部分 | 具体文件名、代码片段、修改记录 | 保留工作成果的精确引用 |
| 错误和修复 | 遇到的错误及修复方法 | 避免重蹈覆辙 |
| 问题解决 | 已解决和进行中的故障排除 | 维持调试的连续性 |
| 所有用户消息 | 非工具结果的用户反馈 | 追踪用户意图的变化 |
| 待处理任务 | 明确被要求处理的未完成任务 | 保持任务的连续性 |
| 当前工作 | 摘要请求前正在进行的具体工作 | 精确的断点恢复 |
| 可选的下一步 | 与当前工作相关的后续步骤 | 引导压缩后的延续方向 |
这个设计有两个值得注意的细节:
XML 格式要求:提示词要求模型以 XML 格式输出摘要,而非 JSON。这是因为 Claude 模型在训练时大量使用了 XML 标签,对 XML 语法的理解更加友好。
开篇语注入:压缩完成后,系统会在新对话的开头注入一段开篇语——"上下文已使用结构化 8 节算法压缩。所有必要信息已保留,可无缝继续对话。"这段文本的作用是给模型一个明确的信号:接下来的内容是压缩后的摘要,而非原始对话。
// 1. 传入历史记录使用 LLM 进行压缩
const summaryResponse = await queryLLM()
// 2. 增加开篇语
const startText = createUserMessage(
`Context has been compressed using structured 8-section algorithm.
All essential information has been preserved for seamless continuation.`,
)
// 3. 压缩后的消息 + 开篇语 = 新一轮对话的上下文
const result = setForkConvoWithMessagesOnTheNextRender([
startText,
summaryResponse,
])17.4.3 基于 LLM 的摘要压缩:Gemini CLI 的方案
Gemini CLI 采用了类似的 LLM 摘要方案,但在两个方面有所不同:
更精简的信息维度:Gemini CLI 只保留 5 个维度的关键信息(相对于 Claude Code 的 9 个):
- Overall Goal(总体目标):用户的高层目标
- Key Knowledge(关键知识):关键事实、约定和约束
- File System State(文件系统状态):哪些文件被创建、修改、删除
- Recent Actions(最近操作):最近的重要操作及其结果
- Current Plan(当前计划):分步计划及完成状态
Scratchpad 链式思考:Gemini CLI 使用了 <scratchpad> 标签引导模型先在"草稿纸"上进行推理,然后再生成最终的结构化快照。提示词明确要求模型"首先在私有的 scratchpad 中思考整个历史",然后才生成 <state_snapshot> XML 对象。这种链式思考机制增强了模型的信息提取能力。
两种方案的对比揭示了一个设计权衡:Claude Code 的 9 段式摘要更全面,适合需要精确断点恢复的场景;Gemini CLI 的 5 段式摘要更精简,信息密度更高,适合需要快速恢复的场景。共同点是:两者都使用 XML 格式、都强调结构化输出、都将"当前计划/任务"作为必保留的维度。
17.4.4 基于算法的消息删除压缩
与 LLM 摘要不同,基于算法的压缩不借助模型,而是通过确定性的规则来决定删除哪些消息。这种方式更可控、延迟更低,但设计难度更大。
三种核心策略
| 策略 | 原理 | 适用场景 |
|---|---|---|
| 中间移除(MiddleRemoval) | 保留对话的开始和结束部分,移除中间消息 | 对话开始(系统指令)和结尾(最新交互)都重要 |
| 最旧移除(OldestRemoval) | 优先移除最早的消息,保留较新的消息 | 长对话中最近上下文最重要 |
| 混合策略(Hybrid) | 智能结合上述两种策略 | 需要根据对话特征自动选择 |
三层策略选择机制
策略的选择通过三层级联筛选完成:
第一层:基于供应商/模型的选择。不同模型对上下文的处理特性不同,因此需要不同的默认策略:
| 提供商 | 模型 | 推荐策略 | 原因 |
|---|---|---|---|
| OpenAI | GPT-4 | 混合策略 | 平衡保留,适合通用对话 |
| OpenAI | O1 | 中间移除 | 需要更多上下文的推理模型 |
| Anthropic | 所有 | 最旧移除 | 保留更多结束消息,适合 Anthropic 对话风格 |
| Gemini 1.5 | 中间移除 | 大上下文模型,需要更保守的压缩 | |
| 本地模型 | 所有 | 混合策略 | 较小上下文,需要更激进的压缩 |
第二层:基于对话特征的选择。仅当第一层选择了混合策略时才进入此层。系统会分析对话的特征数据(消息总数、平均消息长度、最近消息 Token 占比、是否含长消息/系统消息/工具消息、压缩严重程度),然后应用以下规则:
- 轻度压缩且对话较短(<20 条消息)→ 中间移除(置信度 0.8)
- 重度压缩且对话较长(>30 条消息)→ 最旧移除(置信度 0.9)
- 最近消息 Token 占比高(>40%)→ 中间移除(置信度 0.7)
- 包含长消息且需要显著压缩 → 最旧移除(置信度 0.6)
- 包含工具或系统消息 → 中间移除(置信度 0.7)
第三层:自适应方法。当第二层输出的置信度低于 0.6 时,系统会同时执行两种压缩策略,计算各自的效率分数,然后选择效率更高的结果。
效率的计算公式为:
其中 Token 减少率占 60% 权重(核心目标),消息保留率占 40% 权重(次要但重要的目标)。
以一个具体例子说明:假设 15 条消息、9000 tokens,需压缩到 6000 tokens。中间移除策略压缩到 6200 tokens,保留 12 条消息(效率 = 0.507);最旧移除策略压缩到 5800 tokens,保留 10 条消息(效率 = 0.480)。虽然最旧移除减少了更多 token,但中间移除保留了更多消息,综合效率更高,因此被选中。
17.4.5 消息优先级系统
无论选择哪种压缩策略,系统都会先为每条消息分配优先级。这是所有压缩策略的公共前置步骤:
| 条件 | 优先级 | 说明 |
|---|---|---|
| 已有优先级 | 保持不变 | 尊重显式标记 |
| 系统消息 | CRITICAL | 系统指令永不删除 |
| 工具消息 | HIGH | 工具结果通常包含关键信息 |
| 对话开始/结束位置 | HIGH | 保留上下文的"首尾框架" |
| 长消息(>800 tokens) | HIGH | 长消息通常信息密度高 |
| 短消息(<20 tokens,无问号) | LOW | 短确认消息价值低 |
| 包含函数调用 | HIGH | 函数调用是动作的关键节点 |
| 其他 | NORMAL | 默认优先级 |
这个优先级系统体现了一个重要的设计原则:消息的"位置"和"角色"比"内容"更能预测其重要性。系统消息和工具消息几乎总是重要的,而短确认消息几乎总是可以安全删除的。
17.4.6 工具消息裁剪:Claude 平台的策略
除了基于 LLM 的摘要和基于算法的消息删除,还有第三种压缩路径:直接清理工具调用的输入和输出。
Claude 团队对此有明确的描述:
上下文编辑在接近 token 限制时,会自动清除上下文窗口中的过时工具调用和结果。当你的代理执行任务并积累工具结果时,上下文编辑会移除过时内容,同时保留对话流程。
这个策略的合理性来自一个关键观察:在 Claude Code 这类工具中,用户的输入和模型的输出实际上并不多,大部分上下文空间被工具调用(尤其是工具的输出——如大量文件内容的读取)所占据。因此,按类别裁剪时,优先移除工具相关上下文是最合理的选择。

具体的实现思路:
- 从历史记录中识别所有工具调用轮次(每个轮次包含一个 assistant 的工具调用消息和对应的 tool 结果消息)
- 保留最近 N 轮工具调用(可配置,默认保留最近 1 轮)
- 移除其余所有工具调用和结果消息
- 保留所有系统消息和非工具相关的用户/助手消息
interface CompressionOptions {
enabled: boolean;
keepLastToolRounds?: number; // 保留最近 N 轮工具调用
}
function compressContext(
messages: Message[],
options: CompressionOptions
): Message[] {
// 1. 识别所有工具调用轮次
const toolRounds = identifyToolRounds(messages);
// 2. 确定要保留的轮次
const roundsToKeep = toolRounds.slice(-options.keepLastToolRounds);
// 3. 过滤:保留系统消息 + 保留轮次 + 非工具消息
return messages.filter((msg, i) => {
if (msg.role === 'system') return true;
if (roundsToKeep.some(r => r.indices.has(i))) return true;
if (msg.role !== 'tool' && !msg.tool_calls) return true;
return false;
});
}这种方法的优势在于:不需要调用 LLM,延迟极低;不需要复杂的优先级计算;保留了对话流程的完整性(用户和助手的自然语言交互不受影响)。
17.4.7 压缩触发机制
何时触发压缩同样是一个关键的工程决策。ContextManager 使用以下机制:
利用率监控:utilization = currentTokenCount / maxTokens。当利用率达到阈值(默认 90%)时触发压缩。
频率控制:通过 lastCompressCheck 时间戳控制检查频率(默认 5 秒间隔),避免频繁检查带来的性能开销。
maxToken 的动态计算:最大 Token 数不是写死的值,而是根据 LLM 提供商和模型动态计算。这意味着切换模型时,压缩策略会自动适配。
全量重计算:每次更新 Token 总数时,会遍历整个消息数组从头计算,而非增量累加。全量重计算的原因是:(1) 压缩操作会删除或修改消息;(2) 消息优先级可能动态调整;(3) 确保 Token 计数的准确性,避免累积误差。
17.5 前沿动态:上下文管理的演进方向
17.5.1 从被动压缩到主动管理
早期的上下文管理是被动的——等到上下文快溢出了才开始压缩。当前的趋势是转向主动管理:在上下文构建阶段就进行信号密度的优化,而非等到溢出时才做紧急修剪。
Claude Code 的实践是一个典型例子:在任务执行过程中,系统会反复更新 TODO 列表(注意力锚定),通过在上下文中维护一个持续更新的结构化状态,确保模型不会因为上下文增长而"走神"。这种方式不是在事后压缩,而是在过程中就保持上下文的聚焦。
17.5.2 上下文编辑(Context Editing)的兴起
Anthropic 在 Claude 开发者平台上引入了"上下文编辑"(Context Editing)的概念:系统自动清除过时的工具调用和结果,而非简单地截断或摘要。这标志着上下文管理从"全局压缩"向"局部精确编辑"的转变——只移除过时的部分,保留仍然有效的信息。
17.5.3 GSSC 流水线的标准化
Hello-Agents 框架提出的 GSSC(Gather-Select-Structure-Compress)流水线正在成为上下文管理的事实标准。这个四阶段的流水线将"获取-选择-结构化-压缩"抽象为可复用的工程模式,使得上下文管理从"临时应对"转变为"系统化工程"。其中 Select 阶段使用相关性和新近性的加权评分(默认 0.7:0.3),通过贪心算法在 Token 预算内选择最有价值的信息包。
17.5.4 混合压缩策略的收敛
工业实践正在收敛到一种混合压缩模式:
- 常态运行:使用工具消息裁剪(低延迟、高可控)作为第一道压缩
- 阈值触发:使用基于算法的消息删除(中间移除/最旧移除)作为第二道压缩
- 深度压缩:使用 LLM 摘要作为最后手段,在需要大幅压缩时生成高质量摘要
这种分层策略在压缩效果和计算开销之间取得了良好的平衡。
17.6 本章小结
本章从"上下文为什么会变坏"出发,系统剖析了上下文管理的完整技术栈。
上下文失败的四种模式形成了诊断框架:
- 污染(错误信息的自我强化)→ 通过记忆更新机制和错误重试上限来防御
- 干扰(信息过多导致注意力稀释)→ 通过压缩、修剪和多样性注入来缓解
- 混淆(无关信息被当作有效输入)→ 通过 RAG 和工具定义优化来解决
- 冲突(有效信息彼此矛盾)→ 通过上下文隔离和子代理架构来化解
上下文管理的策略体系构成了防御层次:RAG(信息质量闸门)→ 工具优化(减少噪声源)→ 上下文隔离(分而治之)→ 修剪与总结(主动瘦身)。
压缩的工程实践覆盖了三条技术路径:LLM 摘要压缩(Claude Code 的 9 段式、Gemini CLI 的 5 段式)、基于算法的消息删除(三层策略选择 + 消息优先级系统)、工具消息裁剪(按类别精准移除)。
⚠️ 已知局限:当前的上下文压缩方案在"信息保留"维度上缺乏客观评估标准。LLM摘要压缩可能在压缩过程中引入新的幻觉或遗漏关键细节,而开发者难以在不重读原始对话的情况下发现这些问题。基于算法的消息删除虽然可控,但其优先级规则是静态的,无法适应不同任务类型的信息重要性分布。此外,多次压缩的累积信息损失目前没有有效的度量和预警机制——当关键信息在第三次压缩中被丢弃时,系统无法感知到这一退化。
核心结论是:上下文不是越多越好,而是越精准越好。优秀的上下文管理追求的是在有限的注意力预算内,用最高的信号密度,最大化获得期望结果的概率。下一章将把这些管理技术应用到长时程任务场景中,探讨如何在跨越数小时甚至数天的任务中维持上下文的连贯性与目标导向。