第23章 人机协同模式
本章来源:综合自 Agentic Design Patterns 第十三章(Human-in-the-Loop 模式深度分析)、Practical Guide to Context Engineering(协同 Agent 与自主 Agent 形态分析)
核心问题 —— 本章要解答什么
上一章讨论了如何通过 Guardrails 确保智能体行为的安全性。但安全机制的覆盖范围是有限的——规则无法预见所有场景,自动审查无法替代人类对复杂情境的判断。当智能体面对高风险决策、道德模糊地带或超出其能力边界的任务时,需要一种更根本的安全保障:将人类的判断力整合到智能体的工作流中。
本章探讨人机协同(Human-in-the-Loop, HITL)模式的架构设计。核心问题不是"是否需要人类参与",而是**"人类应该在什么时候、以什么方式、在多大程度上参与智能体的决策过程"**。这涉及信任校准、自主性谱系的设计,以及协同平台的工程实现。
设计空间 —— 可选方案与取舍
23.1 人机交互的模式谱系
人机协同并非一种单一模式,而是一个从"完全人控"到"完全自主"的连续谱系。不同位置的模式适用于不同的风险等级和任务特征:
Human-in-the-Loop(人在循环中):人类直接参与智能体的每个关键决策点。智能体提出建议或生成初步结果,人类审查、修改并最终批准。这种模式提供了最高的安全性和准确性,但可扩展性最差。
Human-on-the-Loop(人在循环外):人类定义总体策略和规则,智能体在规则框架内自主执行。人类通过监控仪表板观察系统运行,仅在异常情况下介入。这种模式在安全性和效率之间取得了较好的平衡。
Human-off-the-Loop(人离循环外):智能体完全自主运行,人类仅在事后审查系统行为和结果。这种模式效率最高,但对智能体的可靠性要求也最高。
23.2 协同 Agent 与自主 Agent 的形态划分
从交互形态的视角,智能体可以分为两类:
协同 Agent:人和智能体在同一个工作空间中"协作式"地完成任务。人类可以观察智能体的行为,智能体也可以感知人类的操作。双向的信息流动使得实时纠偏成为可能。编码领域的 Cursor 和 Windsurf、写作领域的协作工具都是协同 Agent 的典型实现。Cursor 在 2024 年达到超过 1 亿美元 ARR [Anysphere, 2024],验证了协同 Agent 的市场价值。
自主 Agent:智能体主导整个任务完成过程,人类只负责输入任务描述。这种形态对模型能力的要求更高,也面临更多挑战——缺乏精确度(缺少任务执行过程中的上下文补充)、缺乏反馈(人类未参与过程,对结果容忍度低)、难以个性化(不同用户的偏好难以在前期完全捕获)。
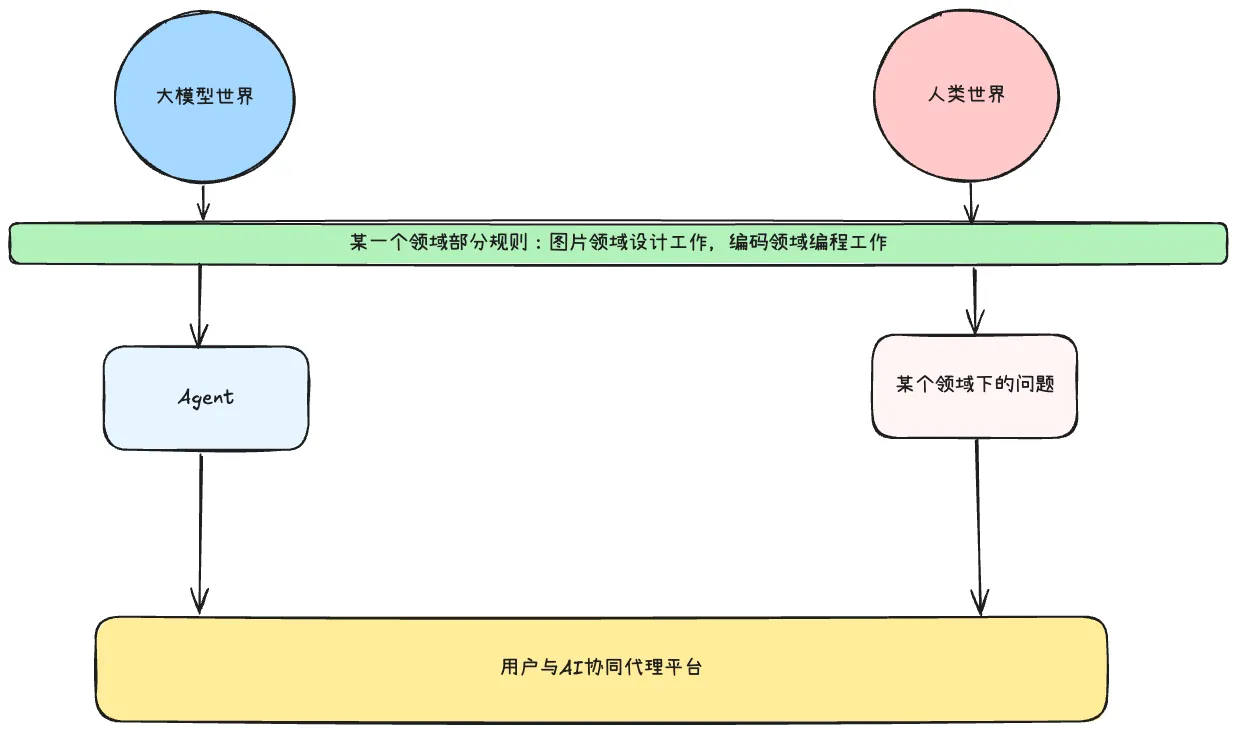
关键认知是:完全自主 Agent 是长期方向,但当前阶段的主要价值在于协同模式。协同平台不是为某一方搭建的,而是兼顾人类世界和 AI 世界的交流空间——双方都可以在其中观察、理解和影响对方的行为。
23.3 何时需要人类介入
决定人类介入时机的关键因素包括:
| 因素 | 倾向自主 | 倾向人类介入 |
|---|---|---|
| 错误后果 | 低(可逆、低成本) | 高(不可逆、高风险) |
| 任务模糊度 | 低(规则明确) | 高(需要判断力) |
| 道德敏感性 | 低(纯技术任务) | 高(涉及伦理决策) |
| 领域专业性 | 低(通用知识) | 高(专家判断) |
| 数据敏感性 | 低(公开信息) | 高(隐私/机密) |
架构解析 —— HITL 模式的关键组件
23.4 人类监督与干预机制
HITL 模式的核心组件包括:
人类监督(Human Oversight):通过日志审查或实时仪表板监控智能体的性能和输出,确保其遵循指南并防止不良结果。监督的粒度可以从粗到细——从定期审查汇总报告到实时监控每次交互。
干预与纠正(Intervention and Correction):当智能体遇到错误或模糊场景时请求人工干预。人类操作员纠正错误、提供缺失数据或指导智能体行为。干预的结果同时用于改进智能体的未来表现。
用于学习的反馈(Human Feedback for Learning):人类反馈被系统性地收集并用于完善 AI 模型。在带有人类反馈的强化学习(RLHF)中 [Ouyang et al., 2022],人类偏好直接影响智能体的学习轨迹。InstructGPT 的实验表明,仅 1.3B 参数的 RLHF 模型在人类偏好评估中优于 175B 参数的无 RLHF 基线模型。
决策增强(Decision Augmentation):智能体提供分析和建议,但最终决策权在人类手中。智能体的角色是增强人类的决策能力,而非替代人类决策。
升级策略(Escalation Policies):预定义的协议规定智能体何时、如何将任务升级给人类。这是 HITL 模式中最关键的工程决策之一——升级阈值太低会导致人类负担过重,太高则可能放过需要人类判断的关键场景。
23.5 ADK 中的 HITL 实现
Google ADK 提供了将 HITL 模式集成到智能体工作流中的具体机制。以下示例展示了一个技术支持智能体如何在需要时将问题升级给人类专家:
from google.adk.agents import Agent
def troubleshoot_issue(issue: str) -> dict:
return {"status": "success", "report": f"Troubleshooting steps for {issue}."}
def create_ticket(issue_type: str, details: str) -> dict:
return {"status": "success", "ticket_id": "TICKET123"}
def escalate_to_human(issue_type: str) -> dict:
# 在实际系统中,这会将任务转入人工队列
return {"status": "success", "message": f"Escalated {issue_type} to a human specialist."}
technical_support_agent = Agent(
name="technical_support_specialist",
model="gemini-2.0-flash-exp",
instruction="""
You are a technical support specialist.
For technical issues:
1. Use troubleshoot_issue to analyze the problem.
2. Guide the user through basic troubleshooting steps.
3. If the issue persists, use create_ticket to log the issue.
For complex issues beyond basic troubleshooting:
1. Use escalate_to_human to transfer to a human specialist.
""",
tools=[troubleshoot_issue, create_ticket, escalate_to_human]
)这个设计的关键在于升级决策嵌入在智能体指令中。智能体通过其推理能力判断问题是否超出自身处理范围,并主动调用 escalate_to_human 工具发起升级。升级不是一个被动的错误处理机制,而是智能体主动的决策行为。
23.6 个性化回调机制
在 HITL 场景中,智能体需要根据用户的具体情况调整其响应。ADK 的回调机制允许在 LLM 请求发送前动态注入用户上下文:
from google.adk.callbacks import CallbackContext
from google.adk.models.llm import LlmRequest
from google.genai import types
from typing import Optional
def personalization_callback(
callback_context: CallbackContext, llm_request: LlmRequest
) -> Optional[LlmRequest]:
"""在 LLM 请求前注入个性化上下文"""
customer_info = callback_context.state.get("customer_info")
if customer_info:
customer_name = customer_info.get("name", "valued customer")
customer_tier = customer_info.get("tier", "standard")
recent_purchases = customer_info.get("recent_purchases", [])
personalization_note = (
f"\nCustomer Name: {customer_name}\n"
f"Customer Tier: {customer_tier}\n"
)
if recent_purchases:
personalization_note += f"Recent Purchases: {', '.join(recent_purchases)}\n"
if llm_request.contents:
system_content = types.Content(
role="system", parts=[types.Part(text=personalization_note)]
)
llm_request.contents.insert(0, system_content)
return None回调机制将个性化逻辑与智能体的核心推理解耦。智能体不需要知道个性化信息从何而来,回调函数从会话状态中提取客户数据并注入到 LLM 请求中。这种设计使得同一个智能体可以在不修改指令的情况下,为不同用户提供差异化的服务。
23.7 Human-on-the-Loop 变体
Human-on-the-Loop 是一种在实际系统中广泛使用的 HITL 变体。在这种模式下,人类专家定义总体策略,智能体在策略框架内自主执行即时操作。
自动金融交易系统是一个典型应用:人类金融专家设定投资策略(如"维持 70% 科技股和 30% 债券的组合,不在单一公司投资超过 5%,自动卖出跌幅超过 10% 的股票")。智能体实时监控市场并在满足条件时自动执行交易。人类设定策略这一"慢"操作,智能体处理执行这一"快"操作。
现代呼叫中心提供了另一个例子:人类经理设定客户交互规则(如"提到'服务中断'的呼叫立即转接技术支持"、"检测到高度沮丧情绪时提供人工连接选项"),智能体在规则框架内自主处理来电,无需对每个案例进行人工干预。
这种模式的核心优势在于将人类的战略性思考与 AI 的执行效率结合:人类负责需要经验和判断力的策略制定,AI 负责需要速度和一致性的策略执行。
关键实现决策 —— 协同平台设计
23.8 协同平台的工程架构
协同 Agent 的核心基础设施是协同平台——人与 AI 的共享工作空间。一个设计良好的协同平台需要实现双向的信息流动:
从人类到 AI 的信息流包括:用户的显式输入(指令、选择、确认)和预定义的规则,以及平台自动收集的状态上下文(相关代码片段、错误消息、历史记录等)。
从 AI 到人类的信息流包括:AI 的输出结果(供用户审核和确认/拒绝),以及 AI 对当前状态的理解和判断(正在获取什么信息、当前进展如何、遇到了什么问题)。
23.9 Cursor 的上下文工程
以编码协同平台 Cursor 为例,其上下文分为两种类型:
意图上下文:定义用户希望模型做什么——"将那个按钮从蓝色变为绿色"。这是规定性的,由用户直接输入。
状态上下文:描述当前世界的状态——错误消息、控制台日志、代码片段。这是描述性的,由平台自动收集。
两种上下文协同工作:意图上下文描述期望的未来状态,状态上下文描述当前状态。智能体的任务是规划从当前状态到目标状态的路径。用户的规则(Rules)进一步约束这条路径应该遵循的原则和偏好。
Windsurf 从协同 Agent 的视角补充了三个关键设计原则:一是需要清晰的方法让人类观察流程执行过程,以便在偏差出现时及早纠正;二是人类观察 Agent 的行为很重要,但 Agent 观察人类的行为也同样重要;三是人类始终可以在中间步骤中纠正 AI,需要批准某些高风险操作(如执行终端命令),并负责实时审查变更。
23.10 Augment 的上下文工程架构
Augment 的架构提供了另一个协同平台的参考实现。其核心洞察是更相关的上下文能提升产品质量。为实现这一目标,Augment 引入了缓存机制:如果两个查询高度相似,第二个查询可以复用第一个查询的检索结果,从而减少查询延迟。
一个值得关注的实现细节是:Augment 的缓存可能不仅缓存检索到的文本片段,还缓存底层的 Token 表示。这种深层缓存策略能够更有效地减少重复计算,同时保持上下文的语义准确性。
23.11 协同 Agent 的设计方向
基于对现有协同平台的分析,可以提炼出五个设计方向:
1. 建立平衡的协作关系:协同 Agent 需要在人类贡献和 AI 贡献之间找到平衡。平台不应偏向任何一方,而是让双方各发挥优势——AI 处理重复性的数据分析和代码生成,人类负责创造性的问题定义和质量判断。
2. 收集足够完整的上下文:借助平台不仅收集当前问题的上下文,还收集用户行为、历史记录等长期上下文。完整的上下文是准确响应的前提。
3. 提供完整的工具描述:工具不仅限于函数和 API,还包括固定的工作流和专门的子智能体。每个工具都需要完整的"说明书"——作用、输入、输出、使用条件,越完整越好。
4. 为每个工具建立精确上下文筛选机制:上下文多不等于好——无关的上下文会稀释信号。每个工具需要的上下文不同,需要建立针对性的上下文筛选机制,找到上下文、工具和模型之间的最佳平衡点。
5. "商量式"而非"命令式"的输出方式:智能体的输出结果不应直接生效,而是需要人类审核确认后才能应用。这种设计让 AI 保持"帮助者"的定位,最终决策权始终在人类手中。
前沿动态 —— 最新进展
23.12 信任校准与自适应自主
人机协同领域正在从"固定分工"走向"动态信任校准"。核心思路是:随着智能体在特定任务上积累更多成功经验,系统可以逐步增加其自主度——从最初的每一步都需要人类确认,到后来只在异常情况下请求人类介入。
这种信任校准机制需要多维度的评估:任务完成质量的历史统计、用户对智能体输出的接受率、错误类型和严重程度的分布。当这些指标持续改善时,系统可以自动放宽人类审批要求;当指标恶化时,自动收紧控制。
23.13 HITL 的可扩展性挑战
HITL 模式的根本局限在于可扩展性。人类操作员无法管理百万级的任务量,这造成了准确性与规模之间的基本权衡。当前的应对策略包括:
分层升级:只将真正需要人类判断的边缘案例升级,大多数常规任务由 AI 自主处理。
主动学习:智能选择最有信息量的样本请求人类标注,而非随机或全量审查。
群体智慧:通过合理的任务分配和冗余审查机制,利用非专家的群体判断来扩展审查能力。
此外,HITL 的实施还面临隐私挑战——敏感信息必须在暴露给人类操作员之前严格匿名化,以及专业性依赖——只有具备相关领域专业知识的人类才能提供有效的监督和反馈。
⚠️ 已知局限:人机协同模式的核心瓶颈是人类认知负荷与审查质量的退化。研究表明,当人类操作员需要连续审查 AI 输出超过 2 小时后,审查准确率下降约 20-30%("自动化偏见"效应)——操作员逐渐倾向于无条件信任 AI 建议,失去了 HITL 机制的核心价值。此外,升级策略的阈值设定是一个未解难题:阈值过低导致人类疲劳(系统退化为全人工处理),阈值过高则关键异常被遗漏。Cursor 等协同平台的实践还揭示了"上下文不对称"问题——AI 对代码库的全局理解通常优于人类操作员的局部视角,导致人类审查者难以有效判断 AI 建议的全局影响。
本章小结
人机协同模式的设计核心在于三个维度的决策:
介入时机决定了自主与监督的平衡——根据任务的风险等级、模糊程度和领域敏感性,选择 Human-in-the-Loop(直接参与决策)、Human-on-the-Loop(策略级监督)还是 Human-off-the-Loop(事后审查)。
交互形态决定了协作的深度——协同 Agent 通过共享工作空间实现双向信息流动和实时纠偏,自主 Agent 则在前端完成任务定义后独立执行。当前阶段协同模式的实用价值更高,完全自主是长期演进方向。
平台设计决定了协作的质量——优秀的协同平台需要在人类和 AI 之间建立平衡的关系,收集完整而精确的上下文,提供详尽的工具描述,并确保输出以"商量式"而非"命令式"的方式呈现给用户。
HITL 模式的价值不在于"人类比 AI 更好",而在于人类和 AI 各自拥有对方不具备的优势。AI 擅长速度、一致性和大规模数据处理;人类擅长判断力、创造力和对复杂情境的理解。将两者的优势通过合理的架构设计结合起来,才能构建出既强大又可信赖的智能系统。