第8章 工具使用模式:从函数调用到MCP
本章来源:综合自 Agentic Design Patterns 第5章(工具使用模式与 Function Calling 机制)、第10章(Model Context Protocol 架构)、Hello-Agents 第9章(上下文工程中的工具管理)、Practical Guide 工具管理模块(工具描述、动态注册与选择策略)
核心问题 -- 本章要解答什么
前面几章讨论的模式(链式调用、路由、并行化)主要关注 LLM 调用之间的编排。但 LLM 本身有一个根本性限制:它们只能生成文本,无法直接与外部世界交互。LLM 无法查询数据库、调用 API、执行代码或访问实时信息。
Toolformer [Schick et al., 2023] 率先证明了LLM可以自主学习何时以及如何调用外部工具。工具使用(Tool Use)模式解决了这个问题。它让 LLM 在推理过程中能够"伸出手"触及外部世界——调用搜索引擎获取实时信息、执行 Python 代码验证计算、查询数据库获取结构化数据、调用第三方 API 完成特定操作。
本章追踪工具使用从 Function Calling 到 Model Context Protocol(MCP)的架构演进,分析其设计空间与工程取舍。
设计空间 -- 可选方案与取舍
8.1 为什么 LLM 需要工具
LLM 的知识来自训练数据,这带来三个固有缺陷:
- 时效性:训练数据有截止日期,无法获取最新信息
- 精确计算:LLM 在数学运算、逻辑推理等精确任务上表现不稳定
- 外部交互:无法直接操作文件系统、数据库、API 等外部资源
工具使用模式通过一个关键的架构决策解决了这些问题:LLM 不执行工具,只决策调用哪个工具、传递什么参数。实际执行由外部系统完成,结果返回给 LLM 用于后续推理。
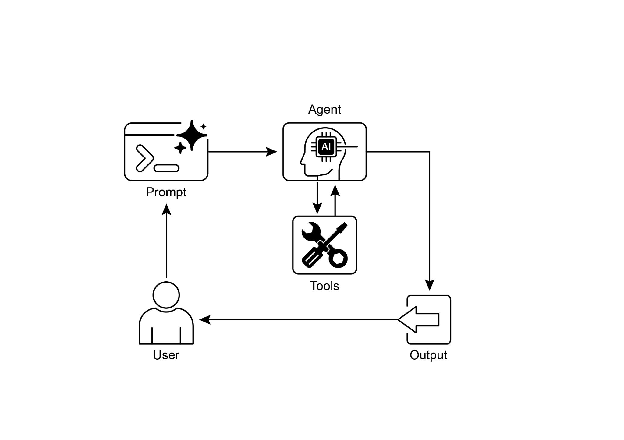
8.2 工具使用的核心流程
工具使用遵循一个三阶段循环:
用户请求 → LLM 推理 → 决定是否需要工具
↓ 是
生成工具调用(函数名 + 参数)
↓
执行工具,获取结果
↓
将结果注入上下文
↓
LLM 基于结果继续推理 → 最终回答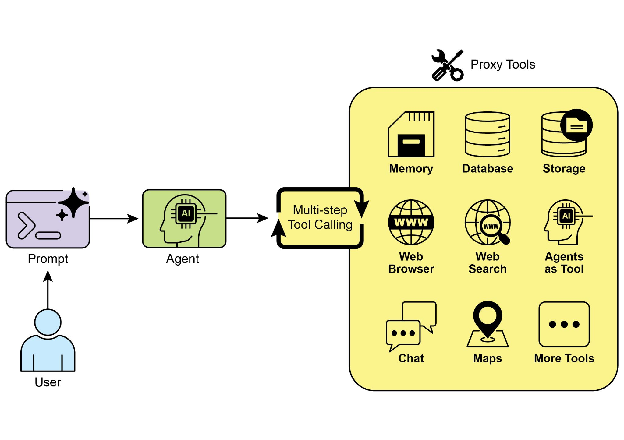
这个循环可以迭代多次——LLM 在获得第一个工具的结果后,可能决定调用第二个工具,形成多步工具链。
8.3 设计维度对比
| 维度 | 早期方案(Prompt 嵌入) | Function Calling | MCP |
|---|---|---|---|
| 工具描述 | 自然语言写在 prompt 中 | 结构化 JSON Schema | 标准化协议 |
| 调用格式 | 模型自由生成文本 | 模型输出结构化 JSON | 协议规范的 JSON-RPC |
| 参数验证 | 无(需人工解析) | Schema 级验证 | 协议级验证 |
| 工具发现 | 静态写死 | API 注册 | 动态发现 |
| 跨模型兼容 | 依赖 prompt 工程 | 各厂商格式不同 | 统一标准 |
| 生态集成 | 无 | 各框架自建 | 开放生态 |
架构解析 -- 深入分析主流架构
8.4 Function Calling 机制
8.4.1 工具定义
Function Calling 的第一步是向 LLM 描述可用的工具。描述需要包含三个要素:函数名称、功能说明、参数规格(名称、类型、描述、是否必选)。以 OpenAI 格式为例:
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name, e.g., 'San Francisco'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Temperature unit"
}
},
"required": ["location"]
}
}
}工具描述的质量直接影响 LLM 的调用决策。函数名应自描述(get_weather 而非 func1),参数描述应包含示例,description 应说明何时该使用此工具。
8.4.2 LLM 的决策与参数提取
收到用户请求和工具描述后,LLM 需要做两个决策:
- 是否需要调用工具:如果用户问的是"什么是量子力学",直接回答即可;如果问的是"北京今天天气如何",则需要调用天气 API
- 调用哪个工具、传什么参数:LLM 需要从用户的自然语言中提取出结构化的参数值
LLM 输出的不是自然语言回答,而是结构化的工具调用指令:
{
"function_call": {
"name": "get_weather",
"arguments": "{\"location\": \"Beijing\", \"unit\": \"celsius\"}"
}
}8.4.3 执行与反馈循环
工具的实际执行发生在 LLM 外部——由应用层代码负责调用真正的 API、解析返回值、处理错误。执行结果作为新的上下文注入 LLM 的对话历史,LLM 基于这些结果生成最终回答或决定进一步的工具调用。
这个"LLM 决策 → 外部执行 → 结果反馈 → LLM 继续推理"的循环,是工具使用模式的核心架构。LLM 扮演"大脑"角色(决策),外部系统扮演"手脚"角色(执行)。
8.4.4 并行工具调用
现代 LLM API 支持在单次推理中生成多个工具调用请求。例如,用户问"北京和上海的天气分别如何",LLM 可以同时输出两个 get_weather 调用。应用层并行执行这些调用,将所有结果一起返回给 LLM,减少交互轮数。
8.5 从 Function Calling 到 MCP
8.5.1 Function Calling 的局限
Function Calling 虽然建立了 LLM 与外部工具交互的基本机制,但存在几个架构层面的限制:
- 厂商碎片化:OpenAI、Google、Anthropic 各有不同的工具定义和调用格式,工具代码难以跨模型复用
- 静态工具集:工具通常在应用启动时注册,运行时无法动态添加或移除
- 缺乏标准化:每个应用需要自行实现工具注册、参数验证、错误处理等基础设施
- 集成成本高:每接入一个新的外部服务,都需要编写定制的适配代码
8.5.2 MCP 的架构跃迁
Model Context Protocol(MCP)由 Anthropic 提出,旨在建立 LLM 与外部数据源、工具之间的标准化通信协议。其核心设计思想是将工具使用从"应用级集成"提升为"协议级标准"。
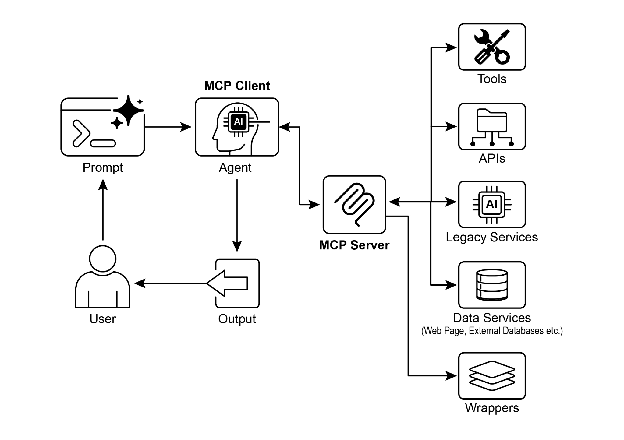
MCP 采用客户端-服务器架构:
- MCP 客户端:嵌入在 LLM 应用中,负责发现和调用工具
- MCP 服务器:独立运行的服务,暴露工具、资源和 prompt 模板
- 传输层:支持 stdio(本地进程)和 SSE(远程 HTTP)两种传输方式
MCP 相比 Function Calling 的关键改进包括:
工具发现:客户端可以在运行时动态发现服务器提供的工具列表,无需预先硬编码。
标准化协议:所有工具使用 JSON-RPC 2.0 进行通信,不依赖特定的 LLM 厂商格式。
资源访问:除了工具调用,MCP 还支持直接读取数据资源(文件、数据库记录等),为 LLM 提供更丰富的上下文。
生态效应:一个 MCP 服务器可以被任何 MCP 客户端使用,工具开发者只需实现一次,所有支持 MCP 的应用都能使用。
8.6 工具描述与选择的工程实践
8.6.1 工具描述的质量工程
工具描述是 LLM 做出正确调用决策的基础。实践中的关键原则:
- 名称语义化:使用
search_database而非tool_3,使用动词+名词的命名模式 - 描述精确:说明工具的功能边界("查询最近7天的天气"而非"查天气")和使用前提("需要提供城市名")
- 参数示例化:在参数描述中包含示例值,帮助 LLM 理解期望的格式
- 区分边界:当有多个功能相似的工具时,明确它们的区别("精确位置查询"vs"区域概况查询")
8.6.2 工具集膨胀问题
随着系统集成的服务增多,可用工具数量可能达到数十甚至上百个。所有工具描述都放入 prompt 会导致:
- prompt 膨胀:大量工具描述占用上下文窗口
- 选择困难:工具过多时 LLM 的选择准确率下降
- 成本增加:每次请求都需要处理完整的工具列表
Gorilla [Patil et al., 2023] 针对这一问题进行了系统研究,证明经过专门微调的LLM在超过1600个API的大规模工具集上,调用准确率可超越GPT-4。解决方案包括:
- 工具检索:根据用户查询,先用语义检索筛选相关工具的子集,只将相关工具的描述提供给 LLM。ToolLLM [Qin et al., 2023] 进一步构建了包含16000+真实API的工具检索和规划框架
- 分层注册:将工具分为"核心工具"(始终可用)和"扩展工具"(按需加载)
- 工具组合:将相关的原子工具组合为高层工具,减少 LLM 需要理解的工具数量
8.6.3 错误处理策略
工具调用可能因多种原因失败:参数格式错误、API 超时、权限不足、服务不可用。健壮的系统需要:
- 将错误信息返回给 LLM:而不是静默失败。LLM 可以根据错误信息调整策略(换参数重试、使用备选工具)
- 重试策略:对暂时性错误(网络超时)自动重试,对永久性错误(参数无效)立即反馈
- 回退机制:主工具失败时自动切换到备选工具(参见第9章异常处理模式)
关键实现决策 -- 工程实践中的关键选择点
8.7 工具粒度设计
原子工具:每个工具只做一件事(search_flights、book_ticket、cancel_reservation)。优点是 LLM 决策更精确,缺点是多步任务需要多轮调用。
复合工具:将多步操作封装为单个工具(plan_and_book_trip)。优点是减少交互轮数,缺点是降低了灵活性和可复用性。
实践建议是对外暴露原子工具,在框架层提供编排能力。LLM 负责决策调用顺序,框架负责优化执行效率。
8.8 安全与权限控制
工具使用引入了新的安全维度——LLM 可能生成意料之外的工具调用,执行有副作用的操作。关键防护措施:
- 只读/读写分级:区分查询类工具和修改类工具,对修改操作要求人工确认
- 参数校验:在执行前校验 LLM 提取的参数值,防止注入攻击
- 操作审计:记录所有工具调用的详细日志,支持事后审查
- 沙箱执行:代码执行类工具在隔离环境中运行
8.9 选择 Function Calling 还是 MCP
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 单一模型、少量工具 | Function Calling | 简单直接,无需额外基础设施 |
| 多模型、需要跨模型复用工具 | MCP | 标准化协议避免重复适配 |
| 需要动态工具发现 | MCP | 内建工具发现机制 |
| 企业级集成、多团队协作 | MCP | 服务化部署,独立演进 |
| 原型开发、快速验证 | Function Calling | 最低启动成本 |
前沿动态 -- 学术界/工业界最新进展
8.10 工具创建与自我进化
前沿研究不再局限于使用预定义的工具,而是探索让智能体自主创建工具。例如,当智能体发现某个操作模式反复出现时,将其封装为新工具。这种工具自创建能力使智能体的能力边界不再由开发者预先设定。
8.11 工具使用的强化学习优化
传统的工具调用依赖 LLM 的 prompt 工程或 SFT 数据。Agentic RL 方向探索用强化学习训练 LLM 的工具使用策略——通过在真实环境中的试错学习,让模型掌握何时调用工具、选择哪个工具、如何组合多个工具的最优策略。这种方法的优势在于可以学到 SFT 数据中不存在的工具组合方式。
8.12 MCP 生态的扩展
MCP 生态正在快速扩展。越来越多的数据源和服务提供了官方 MCP 服务器实现(GitHub、Slack、数据库等)。MCP 的"Resources"能力(直接读取结构化数据)也在从工具调用的补充逐步成长为独立的上下文注入通道,与 RAG 形成有趣的互补。
本章小结
工具使用是 LLM 从"语言模型"跃迁为"行动智能体"的关键能力。Function Calling 建立了 LLM 与外部工具交互的基本范式——LLM 负责决策,外部系统负责执行。MCP 将这一范式从应用级集成提升为协议级标准,解决了工具复用、动态发现和生态碎片化的问题。
⚠️ 已知局限:工具使用模式的最大脆弱点在于参数提取的不可靠性。LLM从自然语言中提取结构化参数时,对于模糊表述(如"最近的数据"中"最近"指多长时间)缺乏可靠的消歧能力。在AgentBench [Liu et al., 2023] 的评估中,即使是GPT-4在复杂多工具场景下的工具调用成功率也仅约70%。此外,MCP的安全模型目前仍较薄弱——缺乏细粒度的权限控制和工具调用审计机制,这在企业级部署中是一个关键阻塞项。
工程实践中的核心决策在于:工具描述的质量工程(好的描述是准确调用的前提)、工具集的规模管理(过多工具会淹没 LLM 的决策能力)、以及安全边界的设定(LLM 不应拥有无限制的操作权限)。