第6章 Reflection——反思与自我进化
本章来源:综合自 Hello-Agents/chapter4(Reflection范式构建)、agentic-design-patterns/Chapter 4(Reflection设计模式)
核心问题 —— 本章要解答什么
无论是ReAct的动态推理还是Plan-and-Solve的计划执行,智能体完成任务后,其输出就被视为最终结果。然而,LLM生成的内容——无论是文本、代码还是决策——都可能包含错误、低效或遗漏。Reflection机制的核心思想是为智能体引入一种事后自我校正循环:审视自己的工作,发现不足,迭代优化。这本质上是将人类"写完初稿→自我审查→修改完善"的工作模式编码为智能体的行为模式。本章聚焦以下关键问题:
- Reflection的"执行-反思-优化"循环如何形式化定义?
- Producer-Critic模型(生产者-评审者)的设计要点是什么?两个角色的提示词分别承担什么职责?
- 反思的质量如何保障?什么样的反馈是"有效"的?
- 记忆模块在Reflection中扮演什么角色?为什么迭代优化依赖于轨迹记忆?
- Reflection的收敛条件是什么?如何避免无效的反复修改?
设计空间 —— 可选方案与取舍
| 维度 | 取值范围 | 设计考量 |
|---|---|---|
| 评审者来源 | 同一模型自反思 ↔ 独立模型交叉评审 ↔ 外部验证器 | 自反思简单但可能盲区一致;交叉评审视角更广但成本倍增;外部验证器最可靠但适用范围有限 |
| 反馈粒度 | 整体评分 ↔ 维度化评审 ↔ 逐行批注 | 整体评分信号弱;维度化评审平衡了信息量和成本;逐行批注信息最丰富但消耗大量Token |
| 迭代次数 | 固定次数 ↔ 质量阈值驱动 ↔ 改进幅度驱动 | 固定次数简单但可能过多或过少;质量阈值需要可靠的评估指标;改进幅度驱动最智能但实现复杂 |
| 记忆策略 | 只保留最新版本 ↔ 保留完整轨迹 | 只保留最新版本节省上下文;完整轨迹让模型避免重复同一错误 |
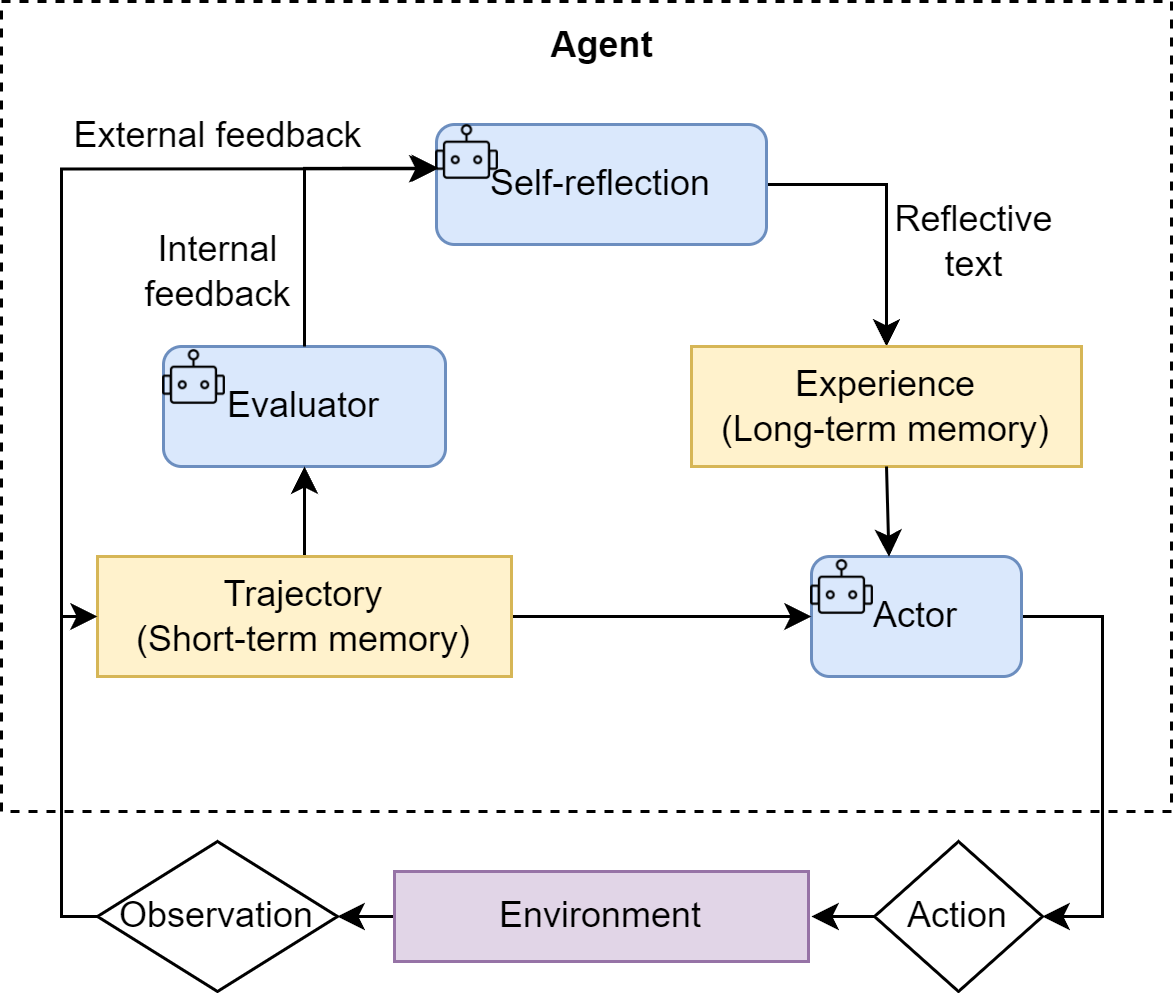
架构解析 —— Reflection的自我进化机制
6.3.1 从"一次性生成"到"迭代优化"
ReAct和Plan-and-Solve的共同局限在于:输出是一次性的。即使结果有缺陷,智能体也没有内建的机制来发现和修正它们。外部用户必须手动检查输出、提出修改意见、再要求智能体重新生成——这本质上是将"反思"的责任外包给了人类。
Reflection [Shinn et al., 2023] 将这一过程自动化,构建了一个内部的质量控制回路。其灵感直接来源于人类的学习过程:完成初稿后校对、解出数学题后验算、写完代码后自测。
6.3.2 形式化定义:执行-反思-优化循环
Reflection机制的核心是一个三步迭代循环。设
优化模型
这个循环重复进行,直到满足终止条件:
- 反思阶段不再发现新的问题(质量收敛)
- 达到预设的最大迭代次数(安全边界)
- 连续两轮的改进幅度低于阈值(边际收益递减)
6.3.3 Producer-Critic模型
Reflection的工程实现通常采用Producer-Critic模型(生产者-评审者模型),通过不同的提示词让LLM在两个角色间切换:
Producer(生产者/执行者):负责生成或改进输出。在第一轮,它根据任务描述生成初稿;在后续轮次,它根据评审者的反馈修改上一版输出。Producer的提示词应该:
- 明确角色定位(如"你是一位资深的Python程序员")
- 聚焦于任务本身的执行质量
- 在后续轮次中,明确要求"根据以下反馈进行修改"而非"从头重写"
Critic(评审者/反思者):负责审查Producer的输出并提供结构化反馈。Critic是Reflection机制的灵魂——反馈的质量直接决定了优化的有效性。一个好的Critic提示词应该:
- 赋予评审者身份(如"你是一位严格的高级代码评审员")
- 指定评审维度(正确性、效率、可读性、边界情况处理等)
- 要求可操作的具体建议而非笼统的评论
- 明确告知"如果已经足够好,请回复'LGTM'"作为终止信号
反馈质量的关键指标是可操作性。"代码可以改进"是低质量反馈;"第15行的循环可以用列表推导式替代以提升可读性,第23行缺少对空列表的边界检查"是高质量反馈。后者给出了明确的修改位置和修改方向,Producer可以直接据此行动。
6.3.4 记忆模块:迭代的基础设施
Reflection的迭代特性要求智能体能够记住之前的所有尝试和收到的反馈。如果没有记忆,模型可能在第三轮重新引入第一轮已经被修正的错误。
记忆模块的设计通常包含:
- 轨迹存储:按时间顺序记录每一轮的(输出, 反馈)对。
- 轨迹序列化:将完整轨迹格式化为可注入提示词的文本,为模型的反思和优化提供完整上下文。
- 最新版本快速访问:支持快速获取最近一次的输出,作为当前轮次反思的对象。
轨迹记忆的工程价值在于:它不仅为当前任务提供了经验记录,还可以在未来的类似任务中被检索和复用。智能体不仅知道最终答案,还记得自己是如何从有缺陷的初稿迭代到最终版本的——这种"过程知识"比单纯的"结果知识"更有价值。
6.3.5 一次完整的Reflection执行轨迹
以"编写一个Python函数,找出1到n之间所有的素数"为例:
第0轮(初始执行): Producer生成初始代码——一个使用试除法的简单实现,时间复杂度
第1轮(反思 + 优化):
- Critic评审:功能正确,但效率低下。建议使用埃拉托色尼筛法(Sieve of Eratosthenes),时间复杂度降低到
。同时指出缺少对 的边界检查。 - Producer根据反馈重写为筛法实现,并添加边界检查。
第2轮(反思 + 优化):
- Critic评审:算法正确且高效。建议优化内存使用(使用位数组代替布尔列表)并补充docstring中的复杂度分析。
- Producer进行微调优化。
第3轮(反思 → 终止):
- Critic评审:代码质量优秀,无需进一步修改。回复"LGTM"。
- 循环终止,输出最终版本。
这个轨迹展示了Reflection如何将一个"能用"的初始实现逐步提升为"优秀"的最终版本——每一轮都在明确的维度上做出可量化的改进。
关键实现决策 —— Reflection的工程化选择
决策一:自反思 vs 交叉评审
自反思:同一个模型既当Producer又当Critic,通过不同的提示词切换角色。优点是简单、成本低。缺点是模型可能对自己的输出存在"盲区"——它无法发现自己系统性的偏见或知识空白。
交叉评审:使用不同的模型(或同一模型的不同配置,如不同的温度)分别担任两个角色。优点是视角更广,缺点是成本倍增且需要管理模型间的兼容性。
实践中的折中方案是:Producer和Critic使用同一个模型,但Critic的提示词中包含明确的评审维度和检查清单,迫使模型从多个角度审视输出,弥补自反思的盲区。
决策二:终止条件的设计
如何判断"够好了"是Reflection的核心工程挑战。三种策略各有适用场景:
- 固定次数(如最多3轮):最简单可预测,适用于对输出质量要求不极高的场景。
- 质量信号驱动:Critic在反馈中包含一个显式的终止信号(如"LGTM"),循环在收到该信号时终止。这要求Critic有可靠的质量判断能力。
- 改进幅度驱动:当连续两轮的改进幅度(通过某种度量衡量)低于阈值时终止。最智能但需要定义和计算"改进幅度"。
在实践中,通常将"质量信号"和"固定次数"结合使用作为双重终止条件。
决策三:反馈的结构化程度
非结构化反馈(自由文本):灵活但可能含糊、冗余,Producer难以准确执行。
结构化反馈(按维度组织):如要求Critic按"正确性/效率/可读性/边界处理"四个维度分别评分和评论。这种结构化使反馈更精确、更可操作,但可能限制Critic发现模板中未预设维度的问题。
推荐的做法是半结构化:提供评审维度作为参考但不强制,允许Critic在发现维度外的问题时自由补充。
前沿动态 —— 反思能力的演进
趋势一:从文本反思到多模态反思
Reflection的反思对象正在从文本扩展到代码、图像、音频等多模态输出。例如:对生成的UI设计进行视觉评审,指出布局不合理之处;对生成的代码进行实际运行测试,将运行结果(包括错误信息)作为反馈的一部分。这种"execution-based feedback"比纯文本反思更加客观和精确。
趋势二:Reflexion——将反思经验持久化
Reflexion [Shinn et al., 2023] 框架将Reflection的轨迹记忆从短期扩展到长期。在HumanEval代码生成基准上,Reflexion将pass@1从GPT-4的67%提升至91%,展现了迭代反思对代码质量的显著提升效果。智能体不仅在当前任务中迭代优化,还将从失败和成功中学到的经验提炼为持久化的"经验教训",在未来的任务中被检索和复用。这将Reflection从"单次任务内的优化"升级为"跨任务的持续学习"。
趋势三:与强化学习的融合
Reflection的"反馈→优化"循环与强化学习的"奖励→策略更新"存在结构性的同构。前沿方向是将Reflection产生的反馈信号作为训练信号,通过Agentic RL将反思能力内化到模型参数中——让模型不需要显式的Critic提示就能自发地进行自我校正。
本章小结
Reflection范式通过引入自我审查和迭代优化循环,为智能体提供了质量保障和持续改进的能力:
- 核心机制:执行-反思-优化三步循环,Producer生成输出,Critic审查并提供结构化反馈,Producer根据反馈改进输出。
- 设计要点:反馈的可操作性是Reflection有效性的关键;记忆模块是迭代的基础设施;终止条件的设计需要在质量和效率之间平衡。
- 与其他范式的关系:Reflection不是独立的,它可以叠加在ReAct和Plan-and-Solve之上——在ReAct执行完成后对整个轨迹进行反思,在Plan-and-Solve的计划生成后对计划质量进行评审。
至此,本书第二篇"智能体经典范式"完结。我们系统地解析了三种最具代表性的智能体行为模式:
- ReAct:推理与行动的实时交织,适用于需要工具交互和动态适应的探索性任务。
- Plan-and-Solve:规划与执行的时间解耦,适用于结构明确的计划性任务。
- Reflection:生成与审查的迭代循环,适用于需要高质量输出和持续改进的任务。
⚠️ 已知局限:Reflection的有效性高度依赖Critic的评审质量。当LLM同时充当Producer和Critic时,模型对自身的系统性偏见存在"盲区"——它倾向于认可自己生成风格的内容,无法发现自身知识空白导致的错误。此外,过多的反思迭代不仅增加延迟和成本,还可能导致"过度优化"——模型在反复修改中引入新的问题或偏离原始意图。
这三种范式不是互斥的选择,而是可以自由组合的构建模块。一个成熟的智能体系统往往会融合多种范式——用Plan-and-Solve做全局规划,用ReAct执行每个计划步骤,用Reflection对关键输出进行质量审查。在后续篇章中,我们将看到这些范式如何与记忆系统、RAG、工具管理等组件结合,构成完整的智能体架构。