第13章 记忆的存储后端与工程实践
本章来源:综合自 Hello-Agents 第8章(Qdrant/Neo4j/SQLite 存储后端实现、RAG 系统构建)、Agentic Design Patterns 第8章(Memory Management 中的 ADK 持久化方案)、Practical Guide 会话存储模块
核心问题 -- 本章要解答什么
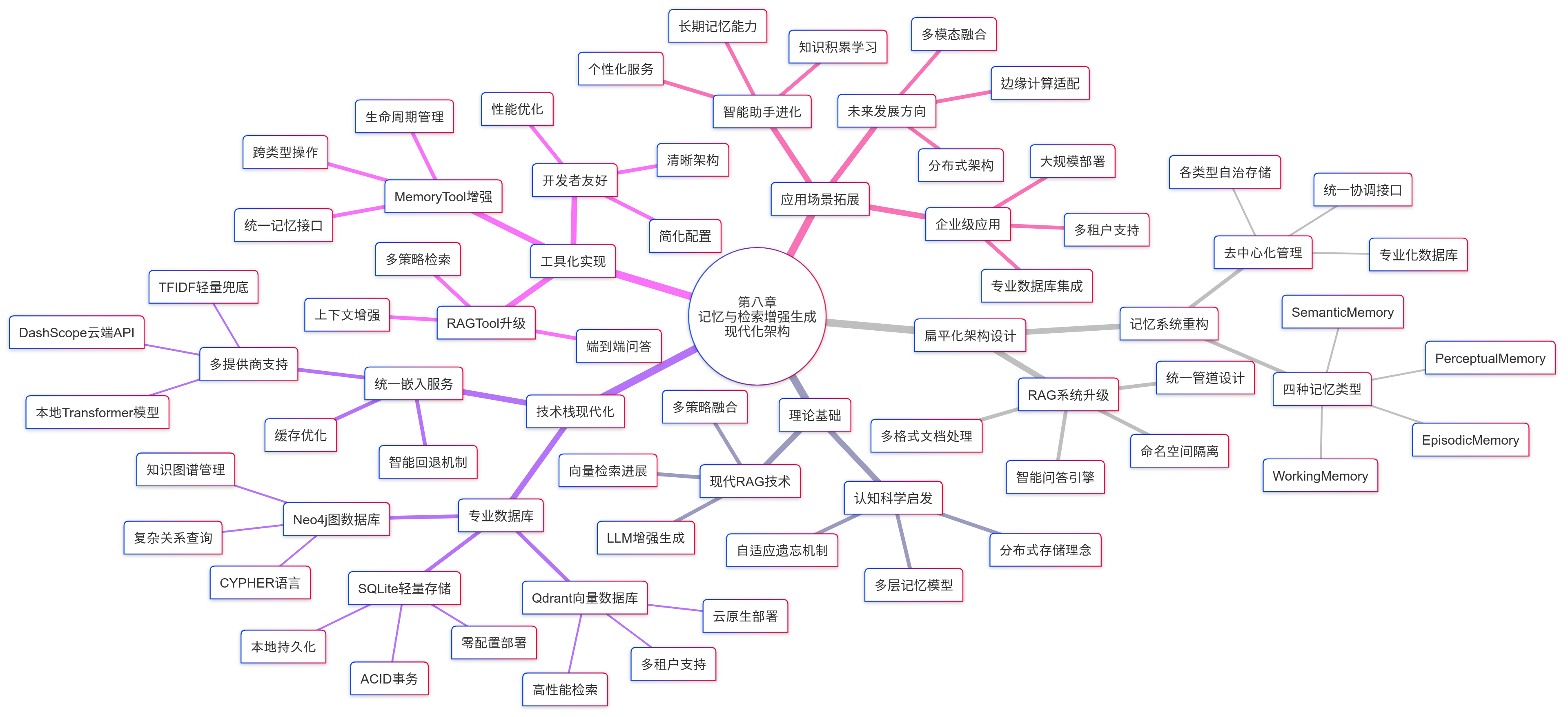
前两章讨论了记忆系统的认知科学基础(第11章)和四种记忆类型的架构设计(第12章)。本章聚焦最后一个关键层面:这些记忆实际存储在哪里、如何存储、以及如何高效检索?
存储后端的选择直接决定了记忆系统的性能特征——向量数据库决定语义搜索的精度和速度,图数据库决定关系推理的能力,文档数据库决定结构化查询的效率。同时,本章还讨论 RAG(检索增强生成)系统的工程实践——它是记忆系统的重要补充,将外部知识注入智能体的推理过程。
设计空间 -- 可选方案与取舍
13.1 三种存储后端的定位
| 存储后端 | 核心能力 | 对应记忆类型 | 典型查询 |
|---|---|---|---|
| Qdrant(向量数据库) | 高维向量的近似最近邻搜索 | 情景、语义、感知记忆 | "找到语义上与X最相关的记忆" |
| Neo4j(图数据库) | 实体-关系的图遍历和模式匹配 | 语义记忆(知识图谱) | "X和Y是什么关系?" |
| SQLite(文档数据库) | 结构化数据的条件查询和排序 | 情景、感知记忆的元数据 | "过去7天重要性>0.8的所有交互" |
这三种后端不是互相替代的关系,而是互补协作——各自处理不同维度的查询需求,共同支撑完整的记忆系统。
13.2 Qdrant 向量数据库
13.2.1 核心原理
Qdrant 是一个高性能的向量相似度搜索引擎。其核心工作流程是:
- 嵌入:将文本或多模态数据通过嵌入模型转换为高维向量
- 索引:使用 HNSW(Hierarchical Navigable Small World)算法构建近似最近邻索引
- 搜索:给定查询向量,在索引中高效找到最相似的 K 个向量
HNSW 是当前最高效的近似最近邻搜索算法之一。它构建多层图结构——上层图连接距离较远但全局覆盖好的节点,下层图连接距离近但覆盖范围小的节点。搜索从上层开始粗略定位,逐层下降精确搜索,实现了 O(log N) 的查询复杂度。
13.2.2 在记忆系统中的应用
Qdrant 在记忆系统中承担语义检索的核心角色:
情景记忆检索:将交互记录的文本嵌入为向量存储,支持"找到与当前问题最相关的历史交互"。查询时可以结合向量相似度和 payload 过滤(如时间范围、会话 ID),实现语义 + 结构的混合检索。
语义记忆检索:存储知识条目的向量嵌入,支持"找到与 X 概念最相关的知识"。与 Neo4j 配合使用——Qdrant 负责发现语义相关的知识,Neo4j 负责追踪这些知识之间的结构化关系。
感知记忆检索:存储多模态数据(CLIP 嵌入),支持跨模态搜索。
命名空间隔离:通过 Collection 和命名空间机制,将不同类型的记忆存储在独立的向量空间中,避免跨类型的干扰。
13.2.3 部署选项
Qdrant Cloud:托管服务,无需运维,通过 URL + API Key 连接。适合生产环境和快速原型。
本地 Docker 部署:docker run -p 6333:6333 qdrant/qdrant。适合开发测试和对数据隐私有要求的场景。
嵌入式模式:直接在 Python 进程中运行,无需单独的服务进程。适合轻量级部署和单机场景。
13.3 Neo4j 图数据库
13.3.1 核心原理
Neo4j 以节点(Node)和关系(Relationship)为基本单元存储数据。节点代表实体,关系代表实体间的连接,两者都可以携带属性。查询使用 Cypher 语言——一种声明式的图查询语言。
与关系数据库的 JOIN 操作不同,图数据库的关系遍历是常数时间复杂度——无论数据量多大,从一个节点出发沿关系边到达相邻节点的时间是恒定的。这使得图数据库在多跳关系查询上具有本质性的性能优势。
13.3.2 在知识图谱中的应用
Neo4j 在语义记忆中承担关系存储和推理的角色:
实体存储:每个实体(人、概念、组织等)作为图节点存储,携带属性(名称、类型、描述等)。
关系存储:实体间的关系作为有向边存储,带有类型标签(IS-A, HAS-ROLE, RELATED-TO 等)和属性(置信度、来源等)。
多跳查询:支持复杂的关系推理。例如,"找到张三的团队中所有使用 Python 的成员"需要多跳遍历:张三 → 所属团队 → 团队成员 → 使用的编程语言。
模式发现:通过图算法发现数据中的模式——社区检测发现紧密关联的知识簇,最短路径发现实体间的间接关联。
13.3.3 与 Qdrant 的协同
语义记忆中 Qdrant 和 Neo4j 的典型协作流程:
用户查询:"Python 相关的知识"
↓
Qdrant 语义搜索:找到语义上与"Python"相关的知识向量
↓ 返回候选集
Neo4j 关系扩展:对每个候选节点,查询其关联实体和关系
↓ 返回扩展的知识子图
结果融合:将向量相似度和图距离综合排序
↓
返回结构化的知识结果(包含实体、关系和上下文)这种"语义发现 + 关系扩展"的组合,使语义记忆既能处理模糊的自然语言查询,又能返回结构化的知识图谱片段。
13.4 SQLite 文档存储
13.4.1 核心定位
SQLite 在记忆系统中扮演结构化元数据管理的角色。它不处理语义搜索(Qdrant 的职责)或关系推理(Neo4j 的职责),而是提供精确的条件查询和排序能力。
13.4.2 存储内容
每条记忆的结构化信息都存储在 SQLite 中:
- 基本信息:ID、内容文本、记忆类型、创建时间、最后访问时间
- 评估信息:重要性评分、访问次数、情感标签
- 关联信息:会话 ID、用户 ID、关联记忆 ID 列表
- 自定义元数据:JSON 格式的扩展字段
13.4.3 查询能力
SQLite 支持 Qdrant 和 Neo4j 不擅长的查询类型:
- 精确条件过滤:
WHERE importance > 0.8 AND memory_type = 'episodic' - 时间范围查询:
WHERE created_at BETWEEN '2024-01-01' AND '2024-03-31' - 聚合统计:
SELECT memory_type, COUNT(*), AVG(importance) FROM memories GROUP BY memory_type - 排序分页:
ORDER BY importance DESC LIMIT 10 OFFSET 20
这些查询在 stats(统计)、summary(摘要)、forget(遗忘策略执行)等操作中被大量使用。
13.4.4 为什么选择 SQLite
在多种关系数据库中选择 SQLite 的原因:
- 零配置:无需安装单独的数据库服务,文件即数据库
- 嵌入式:直接在 Python 进程中运行,无网络开销
- 可靠性:单文件事务支持,不会因进程崩溃而损坏数据
- 性能:对于记忆系统的典型数据规模(万到百万级记录),SQLite 的性能完全足够
当数据规模或并发需求超出 SQLite 的能力时,可以平滑迁移到 PostgreSQL 等服务端数据库。
架构解析 -- 深入分析主流架构
13.5 RAG 系统架构
RAG(Retrieval-Augmented Generation)是记忆系统的重要补充。如果说记忆系统解决的是"记住过去发生了什么",RAG 解决的是"利用外部知识回答问题"。
13.5.1 RAG 管道的四个阶段
文档处理(Document Processing):将多格式文档(PDF、Markdown、HTML 等)解析为纯文本,进行分块(Chunking)——将长文档拆分为适合嵌入的短片段。分块策略直接影响检索质量:
- 固定大小分块:按字数或 token 数切分。简单但可能切断语义单元。
- 语义分块:在段落或章节边界处切分,保持语义完整性。
- 递归分块:先按大粒度切分,对超长片段递归细分。LangChain 的 RecursiveCharacterTextSplitter 就采用这种策略。
- 重叠分块:相邻片段有重叠部分,减少信息丢失。
嵌入表示(Embedding):将文本片段转换为向量。与记忆系统的嵌入服务共享——统一的嵌入模型确保记忆和 RAG 在同一个语义空间中,支持跨系统的联合检索。
向量存储与检索(Storage & Retrieval):使用 Qdrant 存储文档片段的向量。检索时可以使用多种策略:
- 标准向量检索:直接用查询向量搜索最相似的片段
- Multi-Query Expansion (MQE):将用户查询改写为多个不同表述,分别检索后合并去重。提高召回率但增加延迟。
- HyDE (Hypothetical Document Embeddings):先让 LLM 生成假设性答案,用假设答案的嵌入去搜索。适合查询和文档表述差异较大的场景。
增强生成(Augmented Generation):将检索到的相关片段作为上下文注入 LLM 的 prompt,生成基于实际文档的回答。上下文构建需要考虑 token 限制——如果检索片段总量超过上下文窗口,需要智能截断或摘要。
13.5.2 RAG 与记忆系统的关系
RAG 和记忆系统有重叠但不等同:
| 维度 | 记忆系统 | RAG |
|---|---|---|
| 数据来源 | 交互历史、学习经验 | 外部文档、知识库 |
| 数据所有者 | 智能体自身积累 | 用户提供或预加载 |
| 更新频率 | 实时更新 | 批量更新或按需索引 |
| 核心价值 | 个性化、上下文连续性 | 知识准确性、减少幻觉 |
| 存储架构 | 多后端(向量 + 图 + 文档) | 主要依赖向量存储 |
在 HelloAgents 框架中,RAG 被设计为独立的工具(RAGTool),与记忆工具(MemoryTool)并列。两者共享嵌入服务和 Qdrant 向量存储基础设施,但使用不同的命名空间隔离数据。重要的 RAG 检索结果可以自动存储到语义记忆中,形成"外部知识 → 内化记忆"的转化通道。
13.6 ADK 的持久化方案
Google ADK 提供了三种持久化等级,对应不同的部署场景:
InMemorySessionService:所有数据存储在进程内存中。适合开发和测试,应用重启后数据丢失。零配置成本,即开即用。
DatabaseSessionService:使用 SQLAlchemy 连接关系数据库(SQLite、PostgreSQL 等)。适合需要数据持久化的生产环境。需要配置数据库 URL 和驱动。
VertexAiSessionService:使用 Google Cloud 的 Vertex AI 基础设施。适合大规模云部署,自动扩展和高可用。需要 GCP 项目配置和认证。
这种分层设计使开发者可以在不修改业务代码的情况下切换存储后端——开发时用 InMemory,生产时切换到 Database 或 VertexAI。
关键实现决策 -- 工程实践中的关键选择点
13.7 嵌入模型的选择与配置
嵌入模型是连接文本世界和向量世界的桥梁。配置策略:
云端 API 方案(如 DashScope text-embedding-v3):
- 向量维度:1024
- 优势:高质量嵌入,无需本地 GPU
- 配置:API Key + Base URL
本地模型方案(如 sentence-transformers/all-MiniLM-L6-v2):
- 向量维度:384
- 优势:无网络依赖,隐私保护
- 配置:模型自动下载到本地
TF-IDF 兜底方案:
- 向量维度:可配置
- 优势:极轻量,无模型依赖
- 局限:仅词频匹配,无语义理解
实践中建议的降级策略:云端 API → 本地模型 → TF-IDF。系统启动时尝试云端 API,连接失败则切换本地模型,本地模型加载失败则使用 TF-IDF 兜底。确保记忆系统在任何环境下都可用。
13.8 分块策略的优化
RAG 系统中文档分块的质量直接影响检索效果:
- 块大小:太小(<100 token)丢失上下文,太大(>1000 token)引入噪声。建议 200-500 token。
- 重叠比例:建议 10-20% 的重叠。完全不重叠可能在块边界丢失关键信息。
- 元数据保留:每个块应保留来源文档的标题、章节信息和位置索引,便于检索后追溯和上下文重建。
13.9 检索质量的评估
记忆和 RAG 系统的检索质量需要持续监控:
- 召回率(Recall):相关信息是否被检索到。低召回率意味着智能体"忘记"了有用的信息。
- 精确率(Precision):检索到的信息中有多少是真正相关的。低精确率意味着上下文被无关信息污染。
- 延迟:检索操作的响应时间。超过 200ms 的延迟会影响交互体验。
- 新近性偏差:检索是否过度偏向最近的信息而忽略更相关的历史信息。
13.10 存储后端的运维
Qdrant:
- 监控向量集合的大小和查询延迟
- 定期优化索引(HNSW 参数调优)
- 备份策略:快照导出
Neo4j:
- 监控图的节点和边数量
- 创建适当的索引(节点标签索引、关系类型索引)
- 定期清理孤立节点
SQLite:
- 监控数据库文件大小
- 定期执行 VACUUM 回收空间
- 创建常用查询的复合索引
13.11 记忆系统与 RAG 工具的集成模式
在智能体中同时使用记忆和 RAG 时,需要协调两者的优先级:
用户查询
├── 记忆检索:搜索个人交互历史和学习经验
└── RAG 检索:搜索外部知识库文档
↓
结果融合:
1. 记忆结果提供个性化上下文
2. RAG 结果提供知识支撑
3. 去重和排序
↓
注入 LLM 上下文:
[系统 prompt] + [记忆上下文] + [RAG 知识] + [用户查询]一个有效的启发式规则是:记忆结果优先级高于 RAG 结果。如果记忆中已有用户明确表达的偏好,它应该覆盖 RAG 检索到的一般性知识。
前沿动态 -- 学术界/工业界最新进展
13.12 向量数据库的性能竞赛
向量数据库领域正在经历快速迭代。Qdrant、Milvus、Weaviate、Pinecone 等产品在检索速度、过滤能力、多模态支持等维度上持续竞争。关键趋势包括:混合搜索(向量 + 结构化过滤的原生支持)、量化压缩(用更少的内存存储更多向量)、以及与 LLM 推理管线的更紧密集成。
13.13 GraphRAG:图增强的检索
传统 RAG 将文档视为独立片段进行检索,忽略了文档间的结构关系。GraphRAG 在文档索引阶段构建实体和关系的知识图谱,检索时不仅返回相关片段,还返回片段之间的关系链接。这使得 RAG 能回答需要跨文档推理的问题(如"A 文档中的方法和 B 文档中的方法有什么联系?")。微软的 GraphRAG [Edge et al., 2024] 项目是这个方向的典型代表,在多文档综合问答任务上相比标准RAG提升了约20-30%的答案完整性。
13.14 自适应 RAG
传统 RAG 对每个查询都执行检索。Self-RAG [Asai et al., 2023] 让智能体自主决定是否需要检索——对于模型已知的简单问题直接回答,对于需要外部知识的问题才触发检索。这种选择性检索在保持回答质量的同时减少了不必要的检索延迟和成本。
本章小结
存储后端是记忆系统的物理基础。Qdrant 提供高效的向量语义搜索,是记忆检索的核心引擎。Neo4j 提供实体-关系的图存储和遍历,使语义记忆具备关系推理能力。SQLite 提供结构化元数据管理,支持精确条件查询和聚合统计。三者协同工作,覆盖了记忆系统从模糊语义搜索到精确条件查询的完整需求谱。
RAG 系统作为记忆的重要补充,将外部知识注入智能体的推理过程。其四阶段管道(文档处理、嵌入、检索、增强生成)中,分块策略和检索策略是影响最终效果的关键决策点。RAG 与记忆系统共享嵌入和向量存储基础设施,通过命名空间实现数据隔离,通过结果融合实现协同检索。
工程实践中的核心决策包括:嵌入模型的降级策略(云端 → 本地 → TF-IDF)、分块参数的优化(200-500 token + 10-20% 重叠)、检索质量的持续监控(召回率、精确率、延迟)、以及存储后端的运维管理。这些决策共同决定了记忆系统在生产环境中的可靠性和性能。
⚠️ 已知局限:三后端协同架构的运维复杂度在实际生产中常被低估。当Qdrant、Neo4j和SQLite的数据产生不一致时(如某条记忆在向量库中存在但在SQLite中缺失),系统缺乏自动修复机制。此外,RAG检索的质量高度依赖嵌入模型与知识领域的匹配度——通用嵌入模型在高度专业化领域(如法律、医学)的检索召回率可能低于60%,需要领域微调才能达到可用水平。
至此,记忆系统的三个章节——认知科学基础(第11章)、架构设计(第12章)、存储后端与工程实践(第13章)——完整覆盖了从理论到实现的全链路。从人类认知的启发出发,经过四层记忆类型的架构设计,到三种存储后端的具体实现和 RAG 系统的集成,构成了智能体记忆能力的完整技术栈。