第 29 章:实战经验与避坑指南
构建 Agent 的核心能力不是写代码,而是像带实习生一样制定规则、提供工具、编写 SOP——真正的挑战从"能跑"到"可靠"之间的鸿沟开始。
29.1 "建 Agent 像带实习生"——八大实践
开发 Agent 不是在写确定性指令,而是在管理一个"极其听话、极其自信、打字极快,但完全缺乏业务背景知识"的实习生。你的角色是制定规则、提供工具、编写标准作业程序(SOP),而不是规定每一步的死代码。做 Agent 最核心的能力是耐心。
实践一:先设计"思考过程",再写代码
只管连通 API 不管 Agent 的思维逻辑,会导致胡编乱造、逻辑矛盾。动手前先回答五个问题:
- 接到任务第一步做什么?
- 怎么判断需要哪些信息?
- 怎么决定用哪个工具?
- 怎么判断自己做得对不对?
- 什么时候该停止?
这五个问题定义了 Agent 的决策骨架。如果你自己都回答不清楚,Agent 一定会在这些节点上"自信地即兴发挥"。
实践二:工具(Tools)设计是灵魂
工具设计的好坏,对最终效果的影响甚至超过模型选择。三条铁律:
- 粒度适中:用"一句话能说明白"作为标准。太泛(如"处理数据")Agent 不会用;太细(十几个微操工具)Agent 陷入选择困难。
- 描述即说明书:工具描述是写给 Agent 看的。必须写清楚功能、输入格式、输出字段、限制条件。你省的每一个字,都会变成 Agent 犯的错。
- 友好的错误返回:执行失败时绝不返回
None或直接抛异常,要返回引导性文本(如:"找不到数据,建议更换宽泛的关键词"),让 Agent 能据此决策下一步。
# 反面教材:Agent 拿到 None 后无所适从
def search(query: str):
result = db.query(query)
return result # 可能返回 None
# 正确做法:失败时返回可操作的提示
def search(query: str) -> str:
result = db.query(query)
if not result:
return "未找到匹配结果。建议:1) 使用更宽泛的关键词 2) 检查是否有拼写错误"
return format_results(result)实践三:Prompt 是 SOP,不是角色扮演
System Prompt 不只是给 Agent 贴一个"你是一个专业的 XX"标签,而是一份完整的入职培训手册:
- 包含明确的 SOP:清晰定义做事流程(第 1 步...第 2 步...)
- 赋予"说不"的权限:明确告诉 Agent "如果缺数据/做不到,请直接说明,禁止编造",以极大减少幻觉
- Few-shot 要提供完整的思考链:不仅给输入输出,还要给出推理过程——
我看到了什么 → 决定做什么 → 为什么 → 结果是什么 → 下一步做什么
实践四:结构化状态管理
随着步数增加,上下文暴增,必须主动介入管理。摘要压缩是初级做法(会丢细节),推荐做法是维护结构化的工作记忆:
# 维护一个结构化 State,而不是把几千字聊天记录扔给 LLM
state = {
"current_task": "分析用户留存数据",
"collected_data": ["DAU 趋势图", "7 日留存率"],
"findings": ["留存率在第 3 天骤降 15%"],
"next_step": "查询第 3 天的产品变更日志"
}每次调用 LLM 时,把更新后的 State 喂给它,而不是扔几千字的原始聊天记录。State 是 Agent 的"工作台",让它始终知道自己在哪、做了什么、下一步该干嘛。
实践五:评估体系——最不能偷懒的环节
- 定义成功:明确什么叫成功(是结果对?步骤对?还是不犯致命错?)
- 建立测试集:准备 20-30 个覆盖不同场景的 Case(输入、期望输出、合理步骤)
- 专注"失败模式"诊断——对症下药而非盲调参数:
| 失败模式 | 根因 | 修复方向 |
|---|---|---|
| 工具用错 | 工具描述不清 | 改工具描述或拆分工具 |
| 推理断裂 | 缺少引导 | 改 System Prompt 或加 Few-shot |
| 幻觉 | 缺乏事实锚点 | 加事实校验步骤 |
| 丢信息 | 上下文管理不当 | 优化记忆管理策略 |
实践六:框架选择
| 框架 | 定位 | 适用场景 |
|---|---|---|
| LangChain | 生态好但抽象层厚 | 快速 Demo,极难 Debug |
| LangGraph | 图编排状态流转 | 需要控制力的生产场景 |
| CrewAI | 多 Agent 协作 | 单 Agent 做扎实后再碰 |
| 手搓 While 循环 | 最高控制力 | 需要精细控制的核心场景 |
核心建议:在单 Agent 做扎实之前,极其不建议碰多 Agent——复杂度指数级上升。手写 while 循环(获取状态 → LLM 决策 → 解析动作 → 执行工具 → 更新状态)往往是最好维护的选择。
实践七:关键 Tips(踩坑血泪史)
步数限制 15-20:超时强制停止并呼叫人工。没有上限的 Agent 就像没有 max_iterations 的 while(true)——迟早烧穿你的 API 额度。
全链路日志记录:记录每一步的想法、动作和结果。没有日志,Agent 跑到第 15 步报错时你根本无从查起。日志不是锦上添花,是生命线。
Human-in-the-loop 关卡:高风险操作(删除、发消息、花钱的 API)必须加人工确认。Agent 的自信不等于正确。
小数据跑通原则:先用 2-3 条假数据跑通全流程逻辑,再上真实全量数据。
控制烧钱成本:调试流程、迭代 Prompt 时用便宜的小模型(GPT-4o-mini / DeepSeek);跑通后再换贵的大模型看最终效果。
实践八:目前仍未解决的难题
- 自我纠错:让 Agent 自己 Review 自己有点"左脚踩右脚上天",可靠性存疑
- 多 Agent 协作:信息损耗和沟通成本导致多个 Agent 合作往往不如一个强大的单 Agent 做到底
- 长任务可靠性:跑 10 步以上极易出现幻觉或遗忘,仍需等待大模型基础能力进一步提升
29.2 两周烧掉数百 M Token 的教训
Agent 的核心毕竟是基座模型——弱智的模型,接入再多工具、再花哨的流程,也不过是杯水车薪。但在基座模型还没强到无脑碾压一切的当下,适当的 Engineering 仍然能显著提升 Agent 效能。
关键权衡必须先想清楚:工具和 Workflow 只能释放模型已有的能力,不能凭空增加新能力。
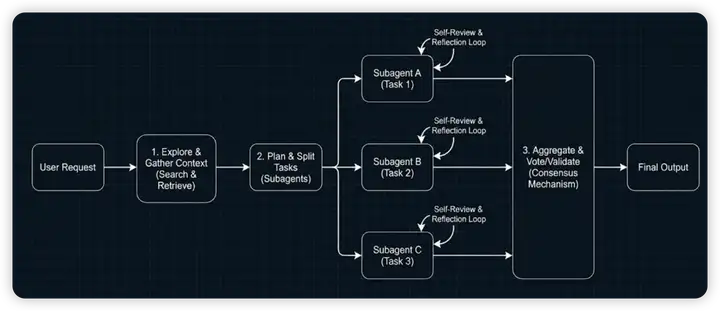
药方一:Context Engineering
过长的上下文让模型无法集中注意力,出现幻觉,并消耗更多 Token。核心手段是用 Subagent 隔离上下文:
- 让每个 Subagent 只做一件小事(爬取文档、运行测试等),完成后把压缩总结的信息传回主 Agent
- 当任务粒度足够细、足够简单时,指令遵循会更靠谱
- 局限:当上下文依赖极强时,拆分任务很困难
# 主 Agent 不直接处理爬虫结果,而是委派给 Subagent
async def research_topic(topic: str) -> str:
# Subagent 独立上下文,爬取+总结,只返回精华
summary = await subagent.run(
f"爬取关于 {topic} 的文档,总结为 200 字以内的要点"
)
# 主 Agent 上下文干净,只拿到精华信息
return summary药方二:Self Review & Reflection
让 LLM 进行多轮自我审查,减轻幻觉影响。背后的原理等价于增加推理算力——正如加入"Think step by step"能改善生成质量一样,多一轮审查就是多一轮深度思考。
注意陷阱:LLM 自己发现的问题有可能也是假的问题,需要再次审查。不能无条件信任 Review 结果。
药方三:并行执行 + 投票
发挥 LLM 便宜量大可并行的优势,两种并行思路:
| 策略 | 做法 | 目的 |
|---|---|---|
| Task Split | 大任务拆成 DAG,并行执行子任务 | 加速 |
| Redundancy | 同一任务并行生成多组解,投票选择 | 提高可靠性 |
为什么投票有效? LLM 是概率模型,单次生成可能落入糟糕的分布尾部,多次生成至少可以拿到平均水平附近的表现。
投票何时失效? 对于足够难的任务,可能多个生成中只有少数能获得正确解,此时"平均"的回答没有意义。除非有外界 Feedback 机制辅助验证。
药方四:先探索再规划(Explore First)
让 LLM 先做大量探索,带着任务去收集可能有效的 Context,再基于收集到的信息决策。如果不加约束,LLM 大概率会选择直接输出并产生幻觉——巧妇难为无米之炊。
信息收集途径包括:爬取文档、从上下文服务(如 Context7)获取文档、阅读代码库等。可以通过 Subagent 进行初步总结过滤,减少主 Agent 的上下文占用。
局限:即使将 Context 拿给 LLM,LLM 也未必会遵循。
药方五:Hard Workflow(必要时)
依赖软性 Prompt 控制 LLM 执行流,在上下文较长时容易注意力涣散。引入强约束的做法:
- 强制的输入输出格式:基于代码的格式检查(如 JSON Schema 验证)
- 状态机转移:用代码控制 Agent 的状态流转,而非依赖 Prompt
- Human Gate:在 Workflow State Machine 中加入人为反馈节点
# 用代码强制状态机,而非依赖 Prompt 控制流程
class AgentStateMachine:
TRANSITIONS = {
"init": ["explore"],
"explore": ["plan"],
"plan": ["execute"],
"execute": ["verify", "explore"], # 失败可回到探索
"verify": ["done", "execute"], # 不通过则重做
}
def transition(self, current: str, next_state: str):
if next_state not in self.TRANSITIONS[current]:
raise ValueError(f"非法转移:{current} → {next_state}")
self.state = next_state当执行流需要 Agent 灵活决定时,静态 Workflow 编排就不适用了——只能祈祷模型足够强。
29.3 Harness Engineering 的五个核心
随着 AI 已经能自主编写数十万甚至上百万行代码,软件工程的核心矛盾发生了转移:真正的挑战不再是"如何让 AI 写得更好",而是如何驾驭它。
Harness Engineering(驾驭工程)是一套围绕 AI Agent 构建的约束、反馈与控制系统。它不优化模型本身的智力,而是优化模型运行的"环境"——为千里马修建一条带有护栏、限速牌、指示标和加油站的高速公路。
核心哲学:你越想让 AI 获得更高的自主性,就越要把规矩定死。 增加系统对 AI 的信任,需要的不是给它更多自由,而是给它更多限制。
graph TB
subgraph "Harness Engineering 五大核心"
A["1. 结构化知识<br/>+ 渐进披露"] --> B["2. 机械架构约束<br/>+ 自定义 Linter"]
B --> C["3. 机器可读<br/>可观测性"]
C --> D["4. 自验证循环"]
D --> E["5. 垃圾回收"]
end
style A fill:#0d9488,color:#fff
style B fill:#3b82f6,color:#fff
style C fill:#8b5cf6,color:#fff
style D fill:#ec4899,color:#fff
style E fill:#f97316,color:#fff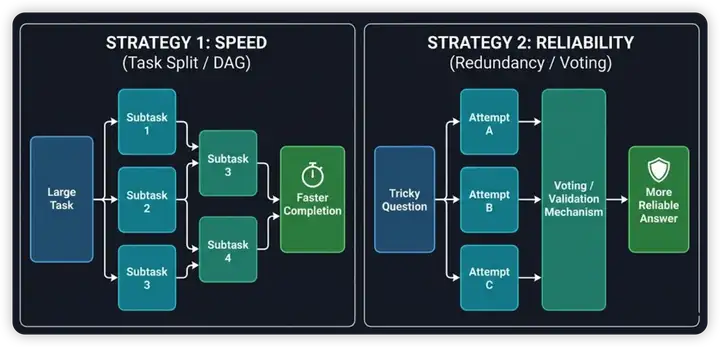
核心一:结构化知识 + 渐进披露(Progressive Disclosure)
痛点:把所有规范塞进一个巨大的 AGENTS.md,会导致上下文窗口溢出,"一切都重要等于一切都不重要",AI 开始随机忽略约束。
解法:把文档当"地图",而非"百科全书"。建立清晰的外部记忆目录树,Agent 启动时只读取顶层地图(约 100 行),随后根据当前任务按需加载深层文档。
repo/
├── AGENTS.md ← 顶层地图,指向下方具体文档
├── docs/
│ ├── architecture/ ← 整体架构设计与分层规则
│ ├── domains/ ← 各业务域的详细文档
│ └── references/ ← 针对特定技术的快速参考指南
├── ai/ ← 专供 AI 读取和写入的记忆区
│ ├── conventions/ ← 全局约定与流程(命名规范、日志要求)
│ ├── .plan/ ← 阶段性设计与执行计划
│ └── .modify/ ← 变更记录与实现说明实践技巧:引入 LocalContextMiddleware,在 Agent 启动时自动运行脚本,将当前绝对路径、可用工具、系统环境变量等确定性信息直接注入上下文,省去 AI 自己摸索带来的错误。
核心二:机械化架构约束 + 自定义 Linter
痛点:AI 每天可能提交几百个 PR,人工 Code Review 根本看不过来。不加限制,AI 会迅速破坏原有架构分层。
解法:将"品味"和"架构"编码为自动化规则。
- 严格的层级依赖树:如
Types → Config → Repo → Service → Runtime → UI,低层绝对不允许反向依赖高层 - 自定义 Linter 拦截:针对结构化日志记录、命名约定、文件大小限制编写规则
- 带解释的报错机制:最关键的一点——当 Linter 或 CI 报错时,不能只报 "Error",要在错误信息中明确注入修复指令
# 差的报错:AI 只知道出错,不知道怎么修
Error: Circular dependency detected.
# 好的报错:AI 拿到报错就能自我修正
Error: 架构违规 [RULE-003] — Service 层不允许直接调用 UI 层。
正确做法:通过 Providers 接口注入。
参考文档:docs/architecture/layer-rules.md这条原则也是 Harness 最反直觉的地方:写给 AI 看的报错信息,比写给人看的报错信息更需要详尽。
核心三:机器可读可观测性(Observability for AI)
痛点:传统日志、监控仪表盘和 UI 界面是给人看的。AI 写完代码如果不亲自运行,就只能靠"脑补"确认正确性。
解法:让 Agent 接入真实运行时环境。
| 层次 | 手段 | 效果 |
|---|---|---|
| 隔离环境 | git worktree 等技术为每次修改创建独立沙箱 | 防止改动互相干扰 |
| 接口级观测 | 开放 LogQL / PromQL 给 AI | 可量化验证("确保服务 800ms 内启动") |
| UI 视觉验证 | 浏览器自动化(Puppeteer / Chrome DevTools MCP) | 发现"代码没报错但 UI 渲染错位"的隐性 Bug |
让 Agent 像真实用户一样点击按钮、抓取 DOM 树、截图比对,能极大提升发现隐性 Bug 的能力。
核心四:自验证循环(Self-Verification)
痛点:LLM 极度偏好"给出第一个看起来合理的答案"。它们经常写完代码、端详一遍就宣布任务完成,根本不去跑测试。
解法:强制的验证闭环,三层机制并行:
提交前检查单(PreCompletionChecklist):设置中间件拦截器,在 Agent 尝试标记"完成"之前,强制它必须运行单元测试或启动应用验证。不验证,不放行。
死循环检测(Doom Loop Detection):Agent 容易陷入反复修改同一个文件却修不好 Bug 的循环。系统需监听文件编辑次数,一旦同一文件被编辑超过 N 次,自动注入强制打断提示:
"你已经尝试多次但未成功,请退一步,重新阅读错误日志并彻底更换思路。"
智能体互审(Agent Peer Review):设立专门负责 Code Review 的审查 Agent。开发 Agent 提交 PR,审查 Agent 跑测试并 Review,提出修改意见打回,直到双方达成一致。人工仅参与重大架构决策。
核心五:垃圾回收(Garbage Collection)
痛点:AI 产生代码的速度极快,系统迅速累积技术债。AI 甚至会"模仿"代码库中已有的烂代码,导致破窗效应蔓延。
解法:将"代码清理"和"文档维护"转变为后台运行的独立 Agent 任务。
- 文档园丁 Agent:扫描代码库中已改变的逻辑与旧文档之间的冲突,自动发起更新文档的 PR
- 技术债清理 Agent:定期比对代码是否偏离"黄金标准"(如发现重复的辅助函数),自动发起重构 PR
核心策略:以"高频、小额"的方式偿还技术债务,而不是让债务堆积到不可收拾。
长周期任务的攻克策略
跨越上下文窗口的断裂,业界顶级实践是双层 Agent 架构:
graph LR
I["Initializer Agent<br/>搭建环境 + 拆解需求"] --> |"功能清单 JSON<br/>所有 passes: false"| C["Coding Agent<br/>每会话只做一个功能"]
C --> |"修改 JSON 状态<br/>写 Git commit"| C
C --> |"所有 passes: true"| D["完成"]
style I fill:#3b82f6,color:#fff
style C fill:#8b5cf6,color:#fff
style D fill:#0d9488,color:#fffInitializer Agent:第一个会话不写业务代码,只搭建环境和拆解需求。产出自动化启动脚本和结构化功能清单(JSON 格式)。关键制约:所有功能状态必须硬编码为 "passes": false,严禁 Agent 删除或编辑测试用例——堵死通过"降低验收标准"来宣布完工的捷径。
Coding Agent:每个独立会话只做增量开发。开场 SOP:pwd 确认目录 → 读 Git log 和进度文件了解上一个自己做了什么 → 读功能清单挑选一个未完成的功能。严禁一口气写完整个 App。
推理算力的"三明治策略":规划阶段用最高算力(深度阅读代码库和需求)→ 执行阶段降低算力(快速编写,防止超时)→ 验证阶段再次拉高算力(仔细检查错误日志,深度思考修复方案)。
29.4 角色转变:程序员 → Agent 的架构师 + PM
在 Harness Engineering 下,程序员的工作不再是敲击键盘,而是变成了系统架构师 + 拥有超强执行力员工的产品经理。传统编程优化的是"生产",驾驭工程优化的是"监管"。新的工作流变成:设计 → 实施(AI 代劳)→ 验证 → 循环。
"双向翻译"(Two-Translation)习惯
为了避免被 AI 的产出淹没("有多少人工审计,就有多少智能"),需要养成双向翻译的习惯:
正向翻译(写代码前):不要给出一句话指令就让 AI 直接写代码。要求 AI 把它的理解和假设写下来。
Prompt 示例:
"在写任何代码之前,请用大白话向我详细复述你的理解、你的执行计划,
以及你在这个过程中做出的假设需要我批准。"在这个阶段抓出偏离轨道的"幻觉",成本远低于事后逆向工程。
逆向翻译(写代码后):不要自己去一行行读 AI 写的几千行代码。新开一个完全隔离的 AI 会话:
Prompt 示例:
"逐步告诉我这段代码到底做了什么,并列出可能的崩溃场景和越权风险。"用另一个 AI 来检验上一个 AI 的产出,打破自我确认偏见。
变更驱动与强制落盘
严禁让 AI 的计划和思路仅仅停留在对话流中。必须落实到可追溯的文件上:
| 阶段 | 落盘位置 | 内容 |
|---|---|---|
| 设计阶段 | ai/.plan | 需求理解、设计方案、关键决定 |
| 实施阶段 | ai/.modify | 改了什么、跑了什么命令、结果是什么 |
| 验证阶段 | Git commit message | 详细的变更说明,作为下一次会话的记忆 |
当 AI 需要面对事实、将操作落实为文字记录时,幻觉会被大幅压缩。同时这也为人类(或另一个审计 Agent)提供了追溯依据。
信任债务(Trust Debt)
不设 Harness 会导致信任债务的累积。AI 表面上完成了功能,但背后充满未经验证的假设——忽略边缘测试、随意引入第三方库、用隐式约定替代显式接口。这些隐式决策积累起来,在未来某一天集中爆发,让你花成倍代价去逆向工程那些从未意识到的错误逻辑。
Harness 的存在,就是在开发周期内强行阻断信任债务的产生。
29.5 姚顺雨的洞察
姚顺雨(ReAct 论文作者)对 AI Agent 领域的思考提供了三个值得深思的视角。
Reasoning 赋能泛化
推理带来了泛化能力。通过语言和推理,模型可以利用先验知识(Prior Knowledge)去适应从未见过的环境。这意味着 Agent 的核心能力不仅在于工具调用,更在于推理链条的构建——推理越强,Agent 在新场景下的适应能力越强。
这也解释了为什么基座模型能力是"重中之重":工具和 Workflow 只是脚手架,推理才是地基。
交互设计驱动商业机会
对于创业者而言,不要试图在基础模型能力上与 OpenAI 硬碰硬,而应专注于设计新的"交互方式"。如果你的应用形态只是 Chatbot,很容易被 ChatGPT 吞噬;但如果你能像 Cursor 一样重构人机协作流程,就能在巨头缝隙中生存。
核心启示:差异化不在模型层,在交互层。 同样的基座模型,不同的交互设计可以产出完全不同的产品形态和商业价值。
非共识研究 = 高回报
姚顺雨提到他早期做 Agent 研究时是"非共识"的——当时学术界的共识在如何训练更好的模型(方法),而非如何让模型完成任务(应用)。这提示我们关注那些"显而易见重要但没人做"的领域。
他将 AI 发展分为上下半场:
| 阶段 | 核心 | 关注点 |
|---|---|---|
| 上半场 | 方法 | 如何训练更强大的模型(架构、训练方法) |
| 下半场 | 任务 | 开发新颖的评估设置或任务,满足现实世界需求 |
下半场应该更好地理解模型边界,而不是提出更难的基准——关键不是让模型跑分更高,而是让模型真正解决问题。
当前除了 Coding,还有哪些数字环境(复杂的企业软件操作、非结构化的创意工作流)是 Agent 可以接管但尚未被充分开发的?这些就是潜在的机会点。