第 21 章 生产部署与可观测性
Agent 的真正价值不在 demo 中,而在生产环境中——部署到用户机器上的安装体验、运行时可观测性、自验证闭环、以及持续的质量保证体系,共同决定了一个 coding agent 能否从原型走向可靠的工程工具。
21.1 部署架构
多平台安装
Coding agent 的安装体验直接影响采用率。主流产品都在追求"单命令上手",但底层策略因平台而异。
npm 全局安装是 Node.js 生态的天然入口。Codex 和 Claude Code 都以 npm 包形式发布:
# Codex
npm install -g @openai/codex
# Claude Code
npm install -g @anthropic-ai/claude-codenpm 安装的优势在于跨平台一致性和版本管理(npm update -g),但依赖 Node.js 运行时。对于 Rust 编写的 Codex 核心(codex-rs),npm 包实际上是一个 thin wrapper,通过 postinstall 脚本下载对应平台的预编译二进制。
系统包管理器覆盖非 Node.js 用户群体:
| 平台 | 包管理器 | 安装命令 |
|---|---|---|
| macOS | Homebrew | brew install codex |
| Windows | Scoop | scoop install codex |
| Linux (Arch) | pacman/AUR | pacman -S codex |
| 跨平台 | Nix | nix-env -iA nixpkgs.codex |
系统包管理器的优势是原生集成(自动添加 PATH、man page、shell completion),代价是发布周期通常滞后于 npm——Homebrew formula 需要维护者合并 PR,AUR 依赖社区打包。
直接二进制分发是最快的安装方式,适合 CI/CD 环境:
# 一行安装脚本,自动检测 OS/arch
curl -fsSL https://install.example.com | sh安装脚本内部逻辑:检测 uname -s(Linux/Darwin)和 uname -m(x86_64/aarch64),下载对应的 tarball,解压到 ~/.local/bin,验证 SHA256 校验和。这种方式绕过了包管理器的版本滞后问题,但失去了自动更新能力。
Remote Sandbox Partners
生产部署的一个关键趋势是将 agent 的代码执行环境从本地机器移到远程沙箱。这解决了两个核心问题:安全隔离(agent 的操作不影响宿主机)和环境一致性(不同用户的 Python/Node 版本差异不再是问题)。
graph TB
subgraph "本地"
CLI["Agent CLI<br>(用户机器)"]
end
subgraph "远程沙箱"
D["Daytona<br>持久化开发环境"]
M["Modal<br>无服务器函数容器"]
R["RunLoop<br>AI 代码执行优化"]
end
CLI -->|SSH/API| D
CLI -->|gRPC| M
CLI -->|WebSocket| RDaytona 提供持久化的远程开发环境。它的核心价值在于 devcontainer 标准支持——agent 可以在与 VS Code Remote 完全一致的容器环境中执行代码,确保环境配置可复现。Agent CLI 通过 SSH 隧道连接到 Daytona workspace,文件系统操作和命令执行都在远端完成。
Modal 走无服务器路线,每次 agent 调用时按需启动容器。适合突发性工作负载——agent 空闲时不消耗资源,执行时可以弹性扩展到 GPU 实例。代价是冷启动延迟(首次执行约 2-5 秒),但 Modal 的 snapshot 机制可以预热常用环境。
RunLoop 专门为 AI 代码执行优化,提供低延迟的 WebSocket 连接和持久化的文件系统快照。DeepAgents 框架对这些沙箱提供了统一的接口抽象:
# DeepAgents 的 sandbox 统一接口
agent = ralph(
task="Build a REST API",
sandbox_type="modal", # 或 "daytona", "runloop"
sandbox_id="my-sandbox", # 复用已有沙箱实例
sandbox_setup="./setup.sh", # 沙箱内初始化脚本
)三种沙箱的选择策略:需要持久开发环境选 Daytona,需要弹性计算选 Modal,需要低延迟 AI 执行选 RunLoop。本地开发和测试时,sandbox_type="none" 直接在宿主机执行。
21.2 可观测性
OpenTelemetry 集成
Codex 的可观测性基础设施构建在 OpenTelemetry(OTel)标准之上,覆盖 logs、traces、metrics 三根支柱。其核心组件 OtelProvider 统一管理三类 exporter 的生命周期:
// OtelProvider 的三层结构
pub struct OtelProvider {
pub logger: Option<SdkLoggerProvider>, // 日志导出
pub tracer_provider: Option<SdkTracerProvider>, // 分布式追踪
pub tracer: Option<Tracer>, // Tracer 实例
pub metrics: Option<MetricsClient>, // 指标采集
}配置体系通过 OtelSettings 统一管理,允许为 logs、traces、metrics 分别指定不同的 exporter:
let settings = OtelSettings {
environment: "production".to_string(),
service_name: "codex-cli".to_string(),
service_version: env!("CARGO_PKG_VERSION").to_string(),
exporter: OtelExporter::OtlpHttp { /* 日志 endpoint */ },
trace_exporter: OtelExporter::OtlpGrpc { /* 追踪 endpoint */ },
metrics_exporter: OtelExporter::Statsig, // 内置 Statsig 集成
runtime_metrics: true,
};这里的设计决策值得注意:logs 和 traces 的 exporter 可以是不同的协议和 endpoint。典型的生产配置是 logs 走 OTLP/HTTP(兼容性好、穿越防火墙方便),traces 走 OTLP/gRPC(低延迟、支持流式传输),metrics 走内置的 Statsig 集成(直接推送到 https://ab.chatgpt.com/otlp/v1/metrics)。
Exporter 类型构成了灵活的多后端支持:
pub enum OtelExporter {
None, // 禁用
Statsig, // 内置 Statsig 快捷方式
OtlpGrpc { endpoint, headers, tls }, // gRPC 协议
OtlpHttp { endpoint, headers, protocol, tls }, // HTTP 协议
}Statsig 变体是一个有趣的抽象——它在运行时被解析为 OtlpHttp,自动填充 Statsig 的 endpoint 和 API key,在测试环境中自动降级为 None。这种"逻辑 exporter"模式允许在配置层保持简洁,而实际传输层保持标准 OTLP。
TLS 支持覆盖了企业部署的常见需求:自定义 CA 证书(内网 PKI)、客户端证书(mTLS 双向认证)。gRPC 和 HTTP 两种协议的 TLS 配置通过统一的 OtelTlsConfig 结构体描述,但底层实现分别使用 tonic(gRPC)和 reqwest(HTTP)的 TLS 客户端。
Target 过滤解决了"什么数据该发到哪里"的问题:
// 日志和追踪使用不同的 target 前缀进行路由
const OTEL_LOG_ONLY_TARGET: &str = "codex_otel.log_only";
const OTEL_TRACE_SAFE_TARGET: &str = "codex_otel.trace_safe";
// 日志 exporter 接收所有 codex_otel.* 事件,但排除 trace_safe
fn is_log_export_target(target: &str) -> bool {
target.starts_with("codex_otel") && !is_trace_safe_target(target)
}
// 追踪 exporter 只接收 trace_safe 前缀的事件
fn is_trace_safe_target(target: &str) -> bool {
target.starts_with("codex_otel.trace_safe")
}这种 target-based 路由的设计意图是:traces 可能被发送到第三方服务(如 Datadog、Jaeger),因此只包含安全的元数据(不含用户 prompt 内容);而 logs 发送到自有后端,可以包含更详细的信息。通过在代码中标注 target 前缀,数据的安全边界在编译时就确定了。
Metrics 子系统
Metrics 是可观测性中最具结构化的部分。Codex 通过 MetricsClient 提供三种基本操作:
// Counter:累加计数
metrics.counter("codex.session_started", 1, &[("source", "tui")])?;
// Histogram:分布统计
metrics.histogram("codex.request_latency", 83, &[("route", "chat")])?;
// Timer:自动计时(Drop 时记录)
let _timer = metrics.start_timer(
"codex.tool.call.duration_ms",
&[("tool", "shell")],
)?;
// ... 执行工具调用 ...
// timer 在作用域结束时自动记录耗时Timer 的 RAII 设计特别优雅——它在 Drop 时自动调用 record_duration,即使函数提前返回或发生 panic,计时数据也不会丢失。这种模式保证了"测量无遗漏"。
预定义的 metric 名称覆盖了 agent 运行的关键路径:
| 指标名 | 类型 | 含义 |
|---|---|---|
codex.tool.call | Counter | 工具调用次数 |
codex.tool.call.duration_ms | Histogram | 工具调用耗时 |
codex.api_request | Counter | API 请求次数 |
codex.api_request.duration_ms | Histogram | API 请求耗时 |
codex.turn.e2e_duration_ms | Histogram | 单轮端到端耗时 |
codex.turn.ttft.duration_ms | Histogram | Time to First Token |
codex.turn.ttfm.duration_ms | Histogram | Time to First Message |
codex.sse_event / codex.websocket.event | Counter | 流式事件计数 |
RuntimeMetricsSummary 提供了运行时指标的聚合快照能力。通过 ManualReader(手动触发采集,而非定期推送),可以在任意时间点拍摄当前会话的指标快照:
// 在会话结束时获取运行时摘要
if let Some(summary) = telemetry.runtime_metrics_summary() {
println!("Tool calls: {} ({} ms)",
summary.tool_calls.count,
summary.tool_calls.duration_ms);
println!("API calls: {} ({} ms)",
summary.api_calls.count,
summary.api_calls.duration_ms);
println!("TTFT: {} ms", summary.turn_ttft_ms);
}这个 snapshot 机制的一个关键设计是 Delta Temporality——每次 collect() 返回的是自上次采集以来的增量数据,而非累计值。这使得"单轮指标"可以通过 reset_runtime_metrics() + 执行 + snapshot() 的三步序列精确获取。
Session Telemetry
SessionTelemetry 是 Codex 的业务事件发射器,在 OTel 基础设施之上封装了 session 级别的语义事件。它自动为每个事件附加 session 元数据(conversation_id、model、auth_mode、originator 等),并区分 log-safe 和 trace-safe 两种安全级别。
核心事件覆盖了 agent 会话的完整生命周期:
codex.conversation_starts:会话启动,携带 provider、reasoning effort、sandbox policy、MCP server 列表等配置快照codex.user_prompt:用户输入,logs 中包含完整 prompt(可通过log_user_prompts标志关闭),traces 中只包含长度和输入类型计数codex.api_request:API 调用,包含 HTTP 状态码、耗时、重试次数、认证元数据codex.tool_result:工具执行结果,logs 包含完整输出,traces 只包含长度和行数codex.sse_event/codex.websocket_event:流式事件,区分成功/失败/超时,自动解析 Responses API 的 timing metrics
Trace Context 传播支持跨进程的分布式追踪。当 agent 调用子进程或远程沙箱时,通过 W3C Trace Context 标准(traceparent / tracestate header)将 trace 上下文传递到下游:
// 从当前 span 提取 W3C trace context
let trace_ctx = current_span_w3c_trace_context();
// -> Some(W3cTraceContext { traceparent: "00-abc...def-01", tracestate: None })
// 在子进程中从环境变量恢复 trace context
let parent_ctx = traceparent_context_from_env();
// 读取 TRACEPARENT 环境变量,恢复父 span 上下文这使得在 Jaeger / Tempo 等追踪后端中,可以看到从用户输入到 LLM 调用再到工具执行的完整调用链——即使这些步骤跨越了多个进程边界。
LangSmith 集成
LangSmith 是 LangChain 生态中 agent 可观测性的标准方案。与 Codex 的原生 OTel 集成不同,LangSmith 的集成是声明式的——通过环境变量启用,无需修改 agent 代码:
# 在 .env 中添加以下配置即可启用 LangSmith 追踪
LANGCHAIN_TRACING_V2=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=your_langsmith_api_key_here
LANGCHAIN_PROJECT=text2sql-deepagent启用后,DeepAgents 框架自动将每次 agent 调用的完整执行轨迹发送到 LangSmith:
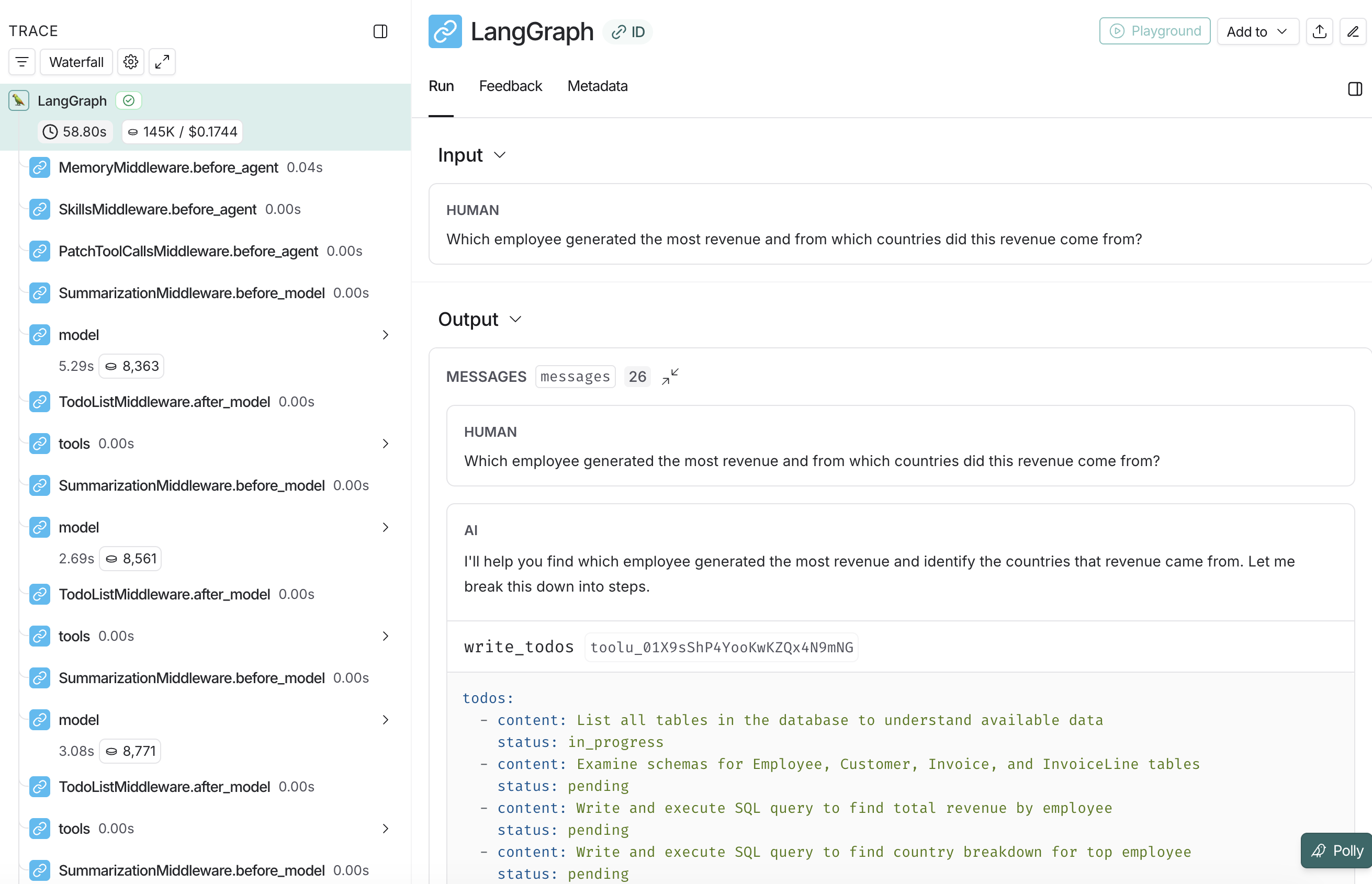
LangSmith trace 中可以看到:
- 完整的调用链:从用户问题到 planning(
write_todos)到工具调用到最终回答 - 每一步的输入/输出:包括生成的 SQL 查询、执行结果、中间推理
- Token 消耗和成本:按步骤细分 input/output token 和费用
- 延迟分解:每个 LLM 调用和工具调用的耗时
- 错误追踪:失败的 SQL 查询、重试过程、错误恢复
LangSmith 和 OTel 的定位差异:OTel 提供标准化的基础设施级可观测性(可以接入任意后端),LangSmith 提供 LLM 应用专属的高级分析(prompt 对比、regression 检测、人工标注反馈)。在生产环境中,二者通常共存——OTel 用于运维告警,LangSmith 用于模型行为分析。
机器可读可观测性
传统可观测性面向人类(Dashboard、日志搜索),但 autonomous agent 需要自己观测自己。Harness Engineering 的核心理念之一,就是将可观测性工具暴露给 agent 使用。
Sandbox + LogQL/PromQL 模式:通过 git worktree 为 agent 的每次修改创建隔离环境,在沙箱中运行服务并将 logs/metrics 推送到 Loki/Prometheus。然后向 agent 开放 LogQL/PromQL 查询工具,让它能执行量化验证:
Agent 接收到指令:"确保服务在 800ms 内启动"
Agent 执行的验证步骤:
1. 在 git worktree 中构建并启动服务
2. 查询 PromQL: startup_duration_seconds{service="api"} < 0.8
3. 查询 LogQL: {app="api"} |= "error" | count_over_time[5m] == 0
4. 两项均通过 → 报告验证成功这种模式的关键在于:agent 不是"看一眼日志觉得没问题",而是执行结构化查询并判断返回值。LogQL/PromQL 的查询语法是机器友好的——返回的是数字而非自然语言,agent 不需要"理解"日志内容,只需要判断查询结果是否满足预期。
UI/截图验证解决"代码没报错但界面渲染错误"的问题。通过 Puppeteer 或 Chrome DevTools Protocol(MCP)集成,agent 可以:
Agent 的 UI 验证流程:
1. 启动浏览器,导航到应用 URL
2. 抓取 DOM 树,检查关键元素是否存在
3. 截图,与基线图对比(pixel diff 或 LLM 视觉判断)
4. 点击按钮,验证交互是否正常
5. 检查 console 是否有错误日志这使 agent 具备了端到端验证能力——不仅确保代码正确,还确保用户看到的界面是正确的。
21.3 自验证循环
Agent 最大的可靠性风险不是写错代码,而是不验证就宣称完成。自验证循环(Self-Verification Loop)是 Harness Engineering 中最核心的控制机制。
完成前清单强制检查
在 agent 尝试标记任务为"完成"之前,设置中间件拦截器强制执行 PreCompletionChecklist:
PreCompletionChecklist(示例配置):
□ 单元测试全部通过(npm test / pytest 返回 0)
□ 构建成功(无编译错误)
□ Linter 通过(无新增 warning)
□ 修改的文件已 git add
□ 没有引入新的 TODO/FIXME(除非显式标注为有意为之)实现方式是在 agent 的工具调用层注册 hook——当 agent 调用 attempt_completion 或类似的终止工具时,hook 先运行检查清单。如果任何一项未通过,清单结果作为工具返回值反馈给 agent,阻止其结束会话。
这种设计的关键在于:检查结果是结构化的(通过/未通过 + 具体错误信息),而非要求 agent 自己判断"够不够好"。这消除了 LLM 的乐观偏差——它不能通过生成一段"我认为这应该可以工作"的解释来绕过验证。
死循环检测
Agent 容易陷入 doom loop:反复修改同一个文件,每次都"修复"了上一轮自己引入的问题,但始终无法收敛。检测机制如下:
Doom Loop Detection 规则:
- 同一文件被编辑 > N 次(默认 N=5)且测试仍未通过
→ 注入打断提示:"你已尝试 N 次修改此文件但未成功。
请退一步,重新阅读完整的错误日志,彻底更换思路。"
- 同一测试连续失败 > M 次(默认 M=3)
→ 强制 agent 执行:
1. 读取完整错误堆栈
2. 列出 3 个不同的修复假设
3. 选择与之前尝试最不同的方案
- 某个工具调用参数在 K 次调用中完全相同
→ 判定为无效重复,直接阻断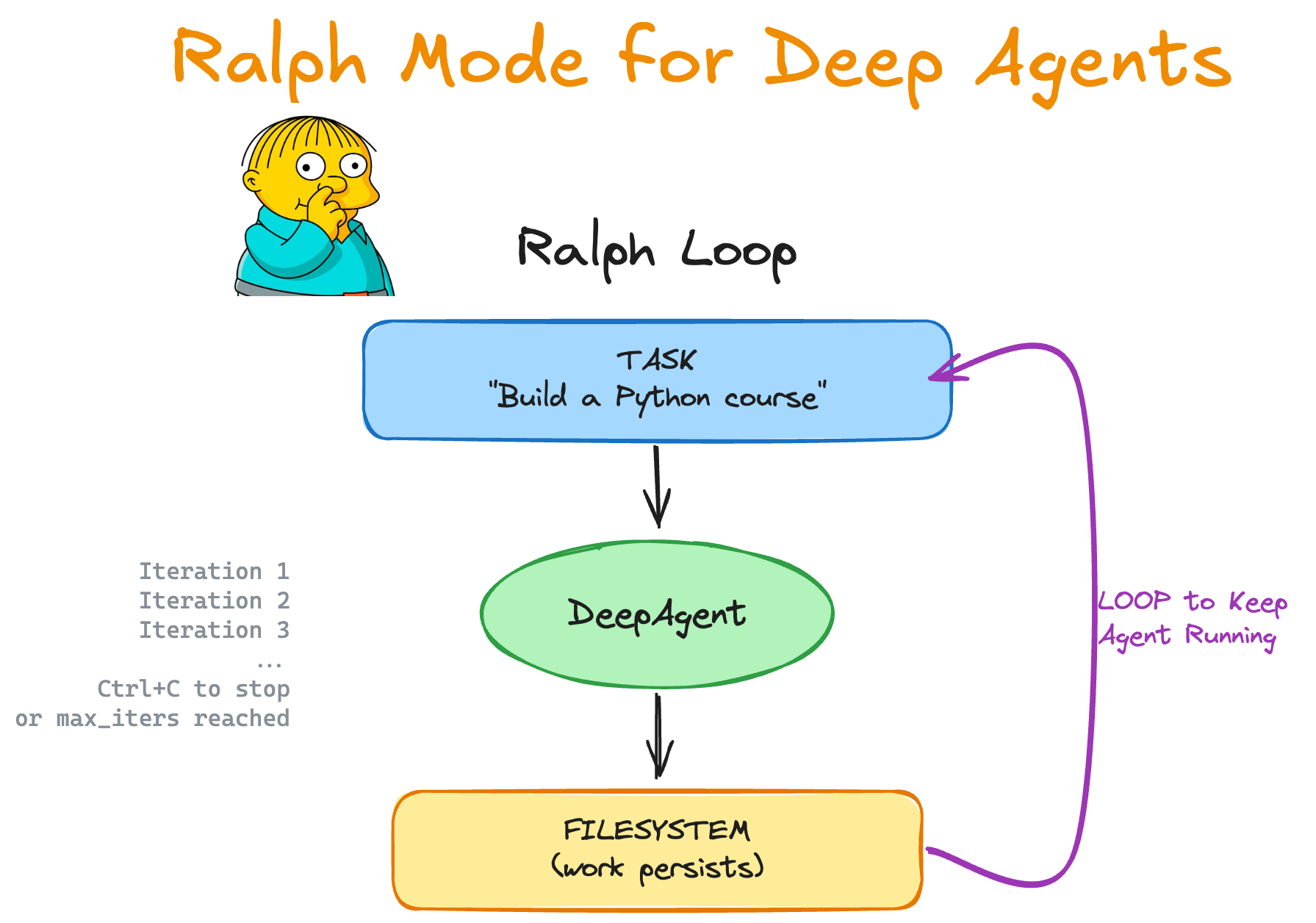
Ralph Mode 是一种更激进的处理方式——每次迭代都使用全新的上下文(fresh context),文件系统作为跨迭代的唯一记忆。这从根本上消除了 doom loop 的上下文累积问题:
# Ralph 循环的核心逻辑
async def ralph(task, max_iterations=0):
iteration = 1
while max_iterations == 0 or iteration <= max_iterations:
prompt = (
f"## Ralph Iteration {iteration}\n\n"
f"Your previous work is in the filesystem. "
f"Check what exists and keep building.\n\n"
f"TASK:\n{task}\n\n"
f"Make progress. You'll be called again."
)
# 每次迭代使用全新的 thread(无历史对话)
exit_code = await run_non_interactive(
message=prompt,
assistant_id="ralph",
quiet=True,
)
iteration += 1原始的 Ralph 模式只有一行:while :; do cat PROMPT.md | agent ; done。上面的实现增加了远程沙箱支持(Modal/Daytona/RunLoop)、迭代次数控制、模型参数配置等生产级特性,但核心哲学未变:fresh context + persistent filesystem = implicit doom loop prevention。
Peer Review:另一个 Agent 检查产出
单个 agent 的自验证有天然盲区——它可能系统性地忽略某类问题(如 edge case、安全漏洞、性能退化)。Peer Review 通过引入独立的审查 Agent 来打破自我确认偏差:
开发 Agent ──→ 提交 PR ──→ 审查 Agent
│
┌─────────┼─────────┐
↓ ↓ ↓
跑测试 读代码 检查风格
│ │ │
└─────────┼─────────┘
↓
┌───────┴───────┐
│ APPROVE? │
├───────────────┤
│ Yes → 合并 │
│ No → 修改意见 │
│ → 打回重做 │
└───────────────┘关键约束:
- 审查 Agent 没有修改权限——它只能读代码和提出意见,不能直接改代码。这确保了职责分离。
- 审查 Agent 使用不同的模型或参数——如开发用 GPT-4o,审查用 Claude Opus。不同模型的错误模式不同,交叉检查能发现更多问题。
- 人工只在重大架构决策时介入——日常的"缩进风格""变量命名""边界检查"由 agent 之间自行解决。
计算预算 "三明治"
对于支持可变推理深度的模型(如 o3-mini 的 reasoning effort),计算资源不应均匀分配,而应按任务阶段调整:
| 阶段 | Reasoning Effort | 目的 |
|---|---|---|
| 规划 | xhigh | 深度阅读代码库,理解需求,制定详尽的 .plan 文件 |
| 执行 | high | 快速编写代码,提高效率,防止超时 |
| 验证 | xhigh | 仔细检查错误日志,深度思考修复方案 |
计算预算分配:
┌──────────┐ ┌──────────────────────────┐ ┌──────────┐
│ xhigh │ │ high │ │ xhigh │
│ Plan │ │ Implement │ │ Verify │
│ (~20%) │ │ (~60%) │ │ (~20%) │
└──────────┘ └──────────────────────────┘ └──────────┘
深思 快速执行 深度审查这个"三明治"策略的直觉是:规划和验证需要全局视角和深度推理(值得花更多 token),而代码编写是相对机械的任务(高 reasoning effort 带来的边际收益递减,但会显著增加延迟和成本)。
21.4 评估与质量保证体系
离线回放(Transcript Replay)
Agent 的交互过程天然产生结构化的 transcript——每一轮对话的 input、output、tool calls、tool results 构成一条完整的执行轨迹。将这些 transcript 存储下来,就获得了一个可以离线回放的测试集。
Transcript 结构:
{
"session_id": "abc-123",
"turns": [
{
"user_input": "Fix the login bug",
"model_output": "I'll look at the auth module...",
"tool_calls": [
{ "name": "read_file", "args": {"path": "auth.py"}, "result": "..." },
{ "name": "edit_file", "args": {"path": "auth.py", "diff": "..."}, "result": "ok" }
],
"metrics": {
"ttft_ms": 450,
"total_tokens": 3200,
"tool_call_count": 2
}
}
]
}回放(Replay)的两种模式:
确定性回放:固定 model response,只验证工具调用链的正确性。用于测试 agent 框架本身的变更——如果修改了工具注册逻辑,回放相同的 transcript 应该产生相同的工具调用序列。
非确定性回放:只固定 user input 和 tool results,让模型重新生成 response,然后对比新旧 response 的质量。用于评估模型升级的影响——当从 GPT-4o 切换到 GPT-4.1 时,在历史 transcript 上回放可以量化新模型的行为变化。
回归集:任务/提示/工具基准
将 transcript replay 系统化,就形成了回归测试集:
回归集的三个维度:
1. 任务回归集(Task Benchmarks)
- 100 个代表性的编程任务
- 每个任务有 gold standard solution 和评判标准
- 覆盖:bug fix / feature / refactor / test writing
2. 提示回归集(Prompt Benchmarks)
- 50 个 edge case 提示(模糊指令、矛盾需求、超长上下文)
- 验证 agent 在"困难输入"下的鲁棒性
- 覆盖:ambiguous / adversarial / context-overflow
3. 工具回归集(Tool Benchmarks)
- 200 个工具调用场景
- 验证每种工具在各种输入下的正确行为
- 覆盖:正常路径 / 边界条件 / 错误处理 / 权限检查回归集的维护是持续的:每当生产环境中发现新的 failure case,自动将其转化为回归测试用例。这形成了"生产问题 → 回归用例 → 防止复现"的闭环。
LLM-as-a-Judge 的偏差控制
当评估 agent 的输出质量时,人工评估成本太高、速度太慢。LLM-as-a-Judge 用另一个 LLM 来评判 agent 的产出,但这引入了系统性偏差:
已知偏差及控制手段:
| 偏差类型 | 表现 | 控制方法 |
|---|---|---|
| 位置偏差 | 倾向于选择列表中第一个/最后一个选项 | 随机化候选答案的呈现顺序 |
| 冗长偏差 | 倾向于给更长的回答更高评分 | 在评分标准中明确惩罚不必要的冗长 |
| 自我偏好 | 同模型 judge 倾向于给同模型的输出更高分 | 使用不同模型做 judge(如用 Claude 评判 GPT 的输出) |
| 格式偏差 | 使用 Markdown/代码块的回答获得不公平加分 | 评分前统一移除格式,或明确指示 judge 忽略格式 |
| 确认偏差 | 对"看起来自信"的回答评分更高 | 要求 judge 验证关键声明,而非评估语气 |
实践中的控制架构:
LLM-as-a-Judge 的去偏差流水线:
Input: Agent A 的输出, Agent B 的输出
Step 1: 预处理
- 移除格式标记
- 匿名化(移除模型名称)
- 随机化呈现顺序
Step 2: 多 Judge 评估
- Judge 1 (Model X): 评分 + 理由
- Judge 2 (Model Y): 评分 + 理由
- Judge 3 (Model Z): 评分 + 理由
Step 3: 聚合
- 如果 3 个 judge 一致:取共识
- 如果 2:1 分歧:取多数
- 如果 3 方分歧:标记为"需人工审核"
Step 4: 校准
- 定期用人工评分校准 judge 的评分尺度
- 计算 judge 间一致性(Cohen's Kappa)
- Kappa < 0.6 → 评分标准需要修订线上指标到训练数据回流
可观测性的终极价值不是"看到问题",而是"改进模型"。完整的数据回流管道将生产环境中的 agent 行为转化为训练信号:
线上指标 → 训练数据回流管道:
1. 数据采集层
┌────────────┐
│ OTel Traces │ → 结构化的执行轨迹
│ LangSmith │ → 带人工标注的轨迹
│ User Feedback│ → 好评/差评 + 文字反馈
└────────────┘
2. 质量分类层
┌────────────────────────────┐
│ 成功轨迹(测试通过 + 用户好评)│ → 正样本
│ 失败轨迹(测试失败 + 用户差评)│ → 负样本
│ 人工修正轨迹 │ → 高质量正样本
└────────────────────────────┘
3. 过滤层
- 移除包含敏感信息的轨迹(PII 检测)
- 移除过短/过长的异常轨迹
- 去重(同一 bug fix 的多次尝试只保留最终成功版)
4. 训练层
- 正样本 → SFT(Supervised Fine-Tuning)
- 正负样本对 → DPO/RLHF preference learning
- 人工修正 → 特别高权重的 SFT 样本这条管道的核心度量是回流率(Flywheel Rate):每 1000 次生产交互中,有多少条最终成为有效的训练数据。业界的经验值是 5-15%——大部分交互要么太简单(模型已经做对了,无学习价值),要么太嘈杂(失败原因是环境问题而非模型能力)。提高回流率的关键是质量分类层的精度——错误地将失败案例标为正样本会导致模型退化。