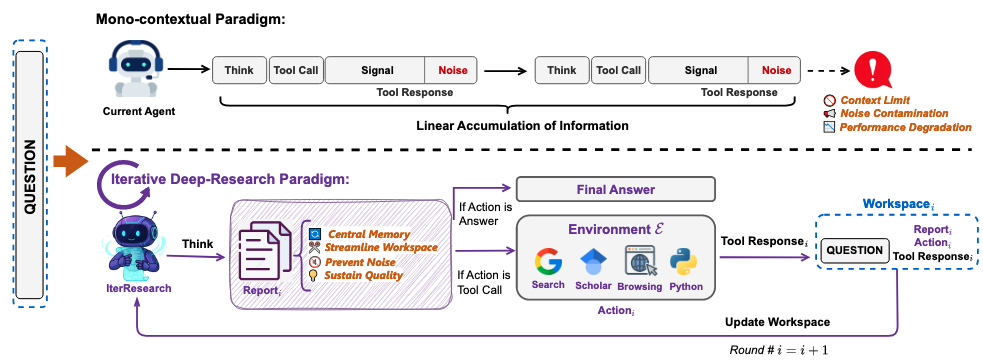
第 23 章 Deep Research 系统 —— 长程多 Agent 研究
Deep Research (DR) 的核心命题是将 LLM 从单轮问答的"搜索引擎增强版"升级为端到端的自主研究员——它能规划子问题、迭代检索证据、在长程上下文中维护记忆、最终综合出带引用的结构化报告,这条路径正在从 Agentic Search 一路演化到 Full-stack AI Scientist。
23.1 Deep Research 的架构模式
DR 系统的标准架构由四个层次组成:Orchestrator(编排器)负责任务分解与调度,Subagents(子智能体)执行具体的检索和分析,Synthesizer(综合器)将分散的发现整合为连贯叙事,Citation Agent(引用代理)负责来源验证和引用格式化。
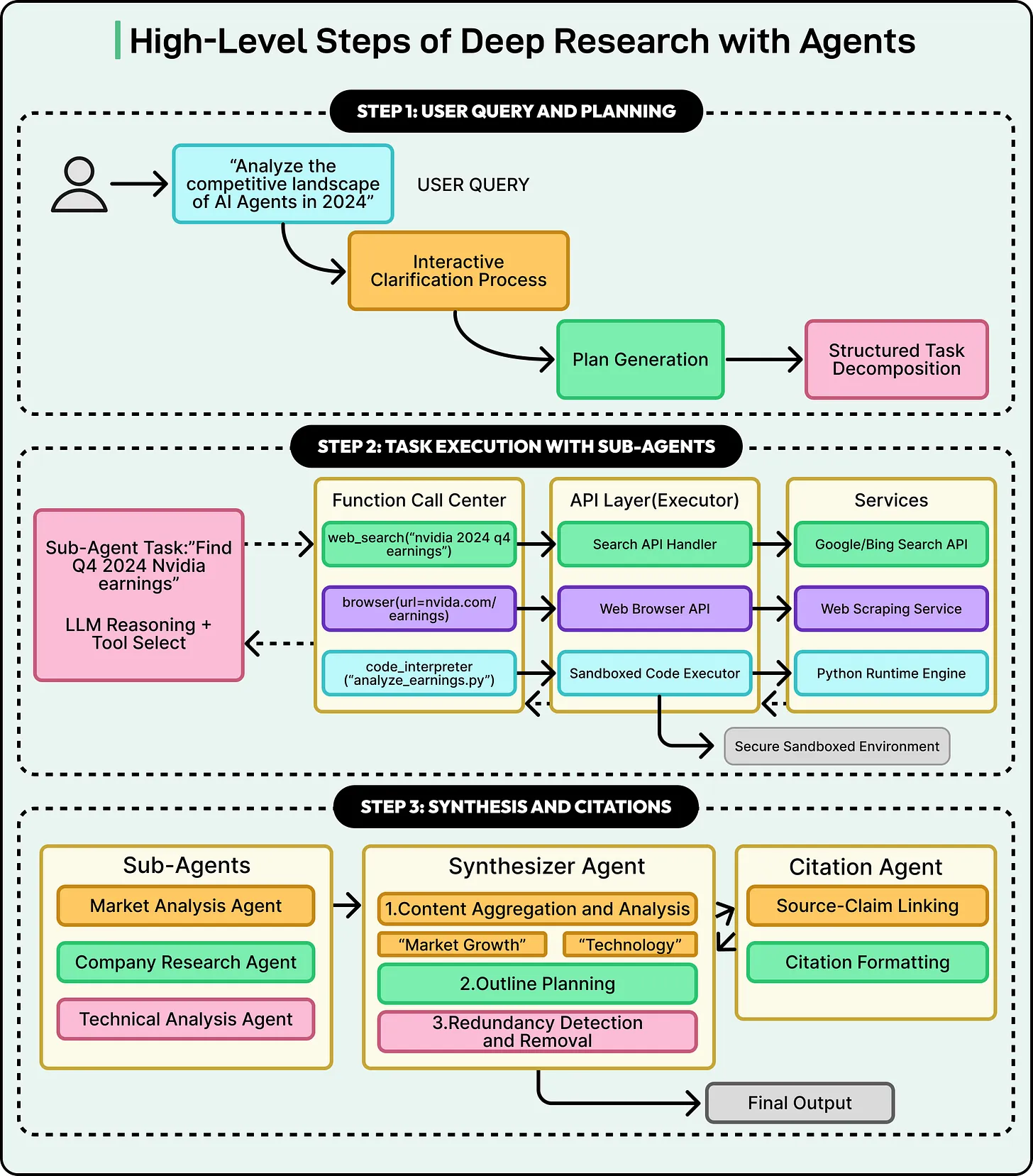
Orchestrator:编排与预算控制
编排器是整个系统的决策中枢。以 Anthropic Deep Research 为例,其核心职责包括:
- 查询分层:分析用户查询的语义类型和难度,确定研究策略
- 预算分配:根据任务复杂度动态调整子智能体数量——简单事实查询分配 1-2 个子智能体,多视角对比分析扩展到 10+ 个
- 冲突监控:并发运行的子智能体返回结果后,编排器检测覆盖缺口和事实冲突,决定是否追加检索轮次
编排器的核心设计原则是"偏向单个子智能体"——一个综合性研究任务比拆成多个窄任务更 token-efficient,只有在需要显式对比(如 A vs B vs C)或地理/领域天然分离时才并行化。
Subagents:隔离上下文的专项研究
每个子智能体在独立的上下文窗口中运行,接收编排器分配的单一主题,执行搜索-反思-搜索的迭代循环。关键约束是工具调用预算:简单查询 2-3 次搜索,复杂查询最多 5 次,超限必须停止。这种硬限制防止了 agent 陷入无穷检索的死循环。
子智能体的另一个设计要点是"think tool"——每次搜索后强制触发一个反思步骤:
@tool
def think_tool(reflection: str) -> str:
"""每次搜索后强制反思:
1. 当前发现了什么关键信息?
2. 还缺什么?
3. 是否已有足够证据给出完整回答?
4. 应该继续搜索还是停止?
"""
return f"Reflection recorded: {reflection}"这个工具本身不执行任何操作,但它在推理流中制造了一个"刻意停顿",迫使模型在发起下一次搜索前评估当前进展。实验表明,没有 think tool 的 agent 倾向于过度搜索或重复搜索同类信息。
Synthesizer + Citation Agent
综合器负责将多个子智能体的发现合并为一份连贯报告。关键操作是引用去重——不同子智能体可能引用了同一个 URL,综合器需要将它们合并为统一的引用编号。引用代理则负责最终验证:每条声明是否都有对应的来源链接,来源链接是否真实可达。
Memory / Plan Persistence
DR 系统需要在长程交互中持久化两类状态:
- Plan 状态:当前的 TODO 列表、已完成的子任务、待处理的子任务。编排器用结构化的 TODO 列表管理研究进度,每个子智能体完成后更新状态
- Memory 状态:已收集的证据片段、中间结论、待验证的假设。记忆管理是 DR 与简单 RAG 的根本区别——它赋予 agent 在长程任务中保持一致性和自我进化的能力
graph TB
User["用户查询"] --> Orch["Orchestrator<br>查询分层 + 预算分配"]
Orch -->|"分配子任务"| SA1["Subagent 1<br>主题A检索"]
Orch -->|"分配子任务"| SA2["Subagent 2<br>主题B检索"]
Orch -->|"分配子任务"| SA3["Subagent 3<br>主题C检索"]
SA1 -->|"发现"| Synth["Synthesizer<br>证据整合 + 冲突消解"]
SA2 -->|"发现"| Synth
SA3 -->|"发现"| Synth
Synth --> Cite["Citation Agent<br>引用验证 + 格式化"]
Cite --> Report["结构化研究报告"]
Orch <-->|"读写"| Plan["Plan Store<br>TODO 列表"]
Synth <-->|"读写"| Mem["Memory Store<br>证据 + 中间结论"]23.2 Systematic Survey:四大核心组件
《Deep Research: A Systematic Survey》首次对 DR 系统进行了全面系统化梳理,提出四大核心组件框架,并定义了三个演化阶段。
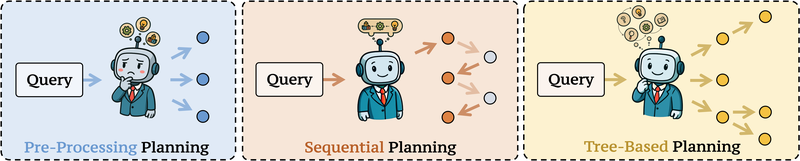
组件 1:Query Planning
查询规划将用户的复杂问题分解为可执行的子查询序列。三种策略各有取舍:
并行规划(Parallel):一次性分解为多个独立子查询同时处理。代表工作 Least-to-Most Prompting 引导模型将复杂任务分解为有序的简单子查询,CoVE 生成多个独立子问题并行验证事实性。优势是效率高,劣势是忽略子查询间的逻辑依赖。
顺序规划(Sequential):多轮迭代逐步分解,每轮基于上一轮的输出决定下一步。Search-R1 和 R1-Searcher 将顺序规划集成到端到端多轮搜索框架中,模型在推理过程中动态决定何时触发检索。优势是能处理强逻辑依赖,劣势是计算成本高且可能产生累积误差。
树状规划(Tree-based / MCTS):将子查询组织为树或 DAG,用蒙特卡洛树搜索(MCTS)探索推理路径。RAG-Star 利用 MCTS 和 UCT 引导迭代分解,DeepRAG 通过二叉树探索决定使用参数化知识还是检索。在并行与顺序之间取得平衡,但训练稳健的树状模块极具挑战。
graph LR
subgraph "并行规划"
Q1["原始查询"] --> S1["子查询1"]
Q1 --> S2["子查询2"]
Q1 --> S3["子查询3"]
end
subgraph "顺序规划"
Q2["原始查询"] --> T1["子查询1"] --> T2["子查询2<br>依赖T1结果"] --> T3["子查询3<br>依赖T2结果"]
end
subgraph "树状规划 MCTS"
Q3["原始查询"] --> U1["分支1"]
Q3 --> U2["分支2"]
U1 --> U3["子分支1.1"]
U1 --> U4["子分支1.2"]
U2 --> U5["子分支2.1"]
end组件 2:Information Acquisition
信息获取涉及三个子问题——用什么工具检索、什么时候触发检索、如何过滤噪声。
检索工具三类:词汇检索(BM25、SPLADE 等基于精确词匹配)、语义检索(将查询和文档编码到连续向量空间)、商业搜索引擎(Google/Bing,提供实时信息和跨源验证)。此外还有多模态检索,能挖掘文本、表格、图表等异构信息。
**检索时机(Adaptive Retrieval)**是核心难题——盲目检索不仅浪费计算资源,低质量文档还可能误导模型。演进路径为:固定检索(IR-CoT)→ 动态触发(ReAct, Self-RAG, Search-o1)→ 基于 RL 的策略学习(Search-R1 通过 GRPO 让模型自主学习何时以及搜索什么)。
信息过滤分三类:
- 文档选择:逐点评分(BGE 嵌入模型)、逐对排序(PRP)、列表式全局排序(RankGPT、Rank-R1 基于 GRPO 训练)
- 内容压缩:词汇级摘要(RECOMP, Chain-of-Note)和嵌入级极致压缩(xRAG 压缩为单 token)
- 规则清洗:HtmlRAG 清除 CSS/JS 噪声,TableRAG 提取核心表格信息
组件 3:Memory Management
记忆管理是 DR 与简单 RAG 的根本区别,赋予 agent 在长程任务中维持一致性的能力。四个核心操作:
记忆整合:将短期信息转化为持久表示。非结构化方式如 MemoryBank 的日常摘要、Generative Agents 的反思机制;结构化方式如 TiM 的实体关系元组、HippoRAG 的知识图谱。
记忆索引:信号增强索引(添加情感、时间、语义元数据)、图索引(利用图结构支持多跳推理)、时间线索引(按时间/因果序列组织)。
记忆更新:非参数化方式对外部存储执行 ADD/UPDATE/MERGE 显式操作;参数化方式通过模型权重编辑实现。
记忆遗忘:被动遗忘如 MemGPT 的 FIFO 队列、MemoryBank 的艾宾浩斯遗忘曲线;主动遗忘如 Mem0 的 DELETE 命令。
组件 4:Answer Generation
答案生成是 DR 系统的最终综合环节,包含四个递进阶段:
- 上游信息整合:将子查询结果、排序后的证据和记忆状态汇聚。Self-RAG 按需自适应检索并生成反射 token 评估相关性
- 证据综合与连贯性维护:冲突解决(可信度感知注意力、多智能体审议如 MADAM-RAG 模拟专家委员会、基于 RL 的事实性训练);长文本连贯性(LongWriter 证明
) - 推理结构化:从 Chain-of-Thought 到显式 DAG 大纲生成(RAPID)再到工具增强推理(Toolformer)
- 展示生成:从纯文本扩展到数据可视化(LIDA, ChartGPT)、同步音频(PresentAgent)、可编辑演示文稿(PPTAgent)
三个演化阶段
DR 的演化不是价值层级而是能力轨迹,三个阶段捕捉了系统能力的渐进扩展:
Phase I — Agentic Search(智能搜索):专注于精确证据获取和忠实提取。通过查询改写/分解提高召回率,检索并重排候选文档,产出简洁的带引用答案。评估侧重检索 recall@k 和答案精确匹配。代表场景:开放域问答、多跳问答。
Phase II — Integrated Research(集成研究):超越孤立事实,产出整合异构证据的连贯结构化报告。研究循环变为显式迭代——规划子问题、从 HTML/表格/图表等多种原始内容中检索和提取关键证据、综合为叙事性报告。评估转向细粒度事实性、引用验证、结构连贯性和关键点覆盖。
Phase III — Full-stack AI Scientist(全栈 AI 科学家):超越信息聚合,追求科学理解与创造。DR agent 不仅聚合证据,还要生成假设、设计实验验证、批评现有观点、提出新视角。只有这个阶段支持创新与假设提出。代表场景:论文审稿、科学发现、实验自动化。
核心差异在于:从 Phase I 到 III,系统的动作空间从窄到宽,推理视野从单次到长程,工作流从固定到灵活,输出形式从短跨度答案进化到学术论文。
23.3 框架、训练与数据的演化
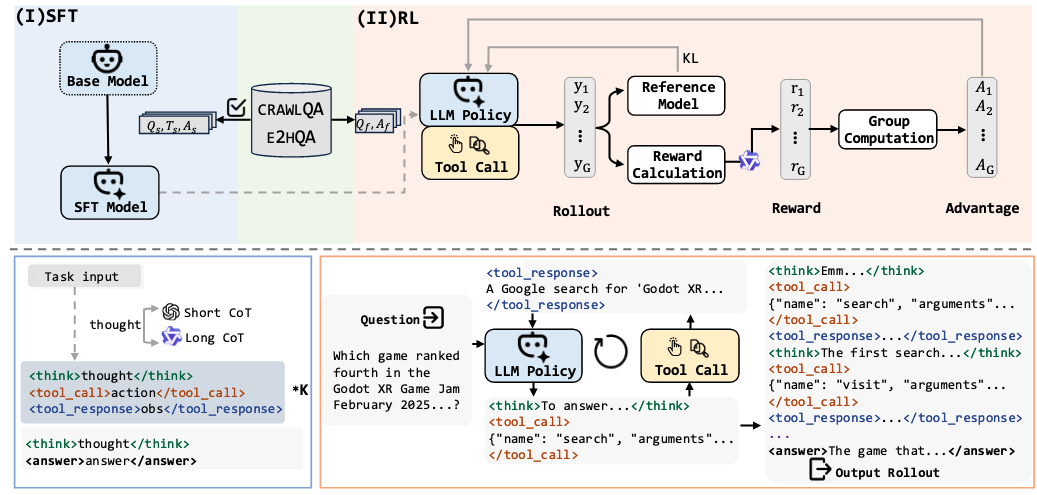
DR 的技术体系沿三条主线同时演化:Agent 框架、奖励设计、数据构建。三条线相互补充,共同构成下一代研究型 Agent 的基础。
Agent 框架:ReAct → ReSum → Multi-agent
阶段一:ReAct 单智能体
最早的 DR 方法基于 ReAct 风格的单 Agent 设计,模型在统一的决策序列中同时执行推理、查询、信息读取和回答。这里存在两条路线:
- 推理延伸路线(Search-R1, R1-Searcher):模型生成
<think>进行内部推理,遇到知识空缺就用<search>query</search>触发检索,将结果插入上下文继续思考。R1-Searcher 扩展了动作空间——单个搜索动作可发出多个 query,并行覆盖不同检索方向 - 工具标准化路线(WebDancer, WebSailor-V2):用
<tool_call>标签 + 工具名称 + 参数发起调用,<tool_response>表示返回结果。WebSailor-V2 进一步扩展动作空间到访问网页、解析 DOM、执行复杂操作
单 Agent 范式的局限在任务变复杂后暴露:长链任务中的记忆过载和推理轨迹过长带来的不稳定性。
阶段二:ReSum — 双模型协作
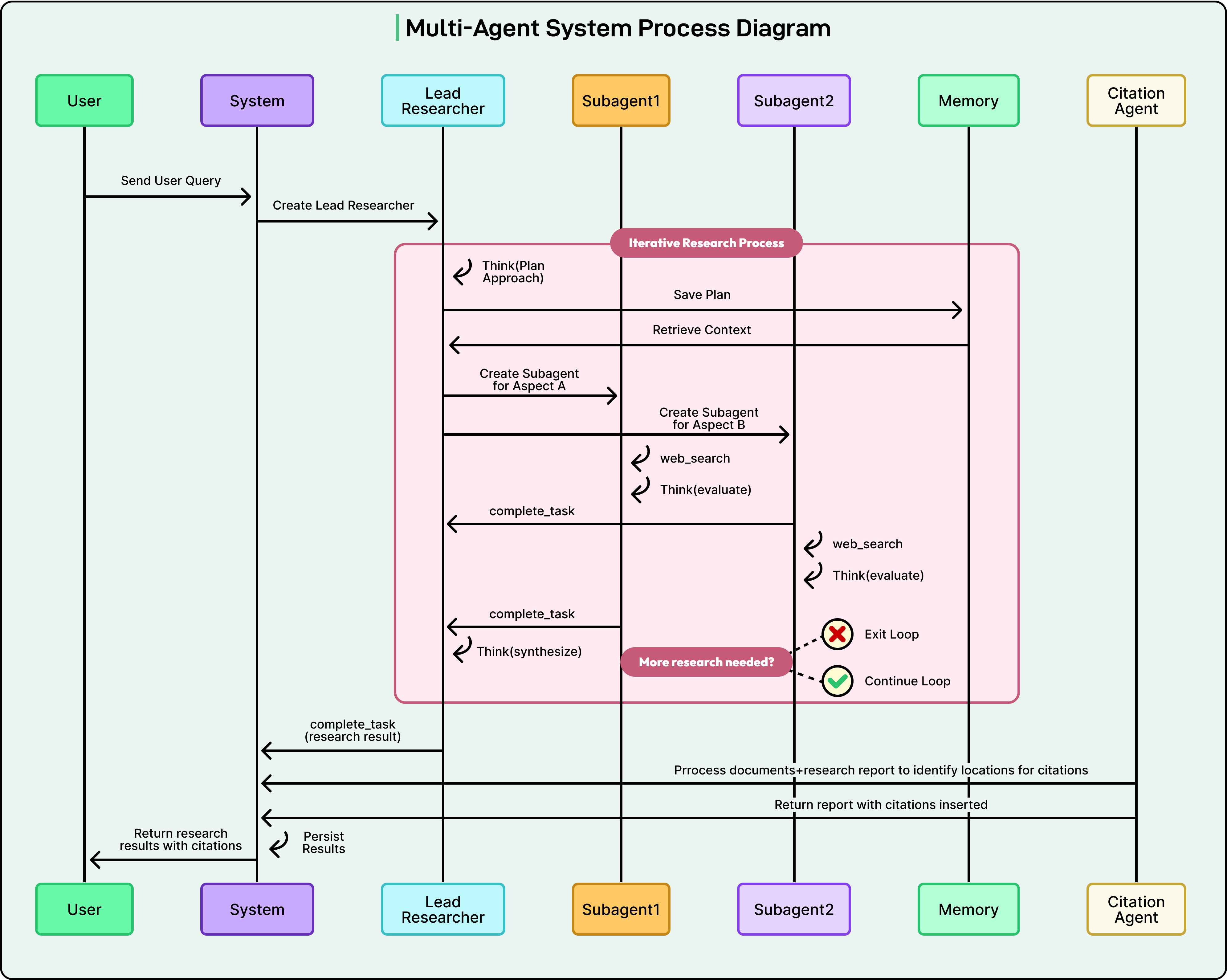
ReSum 是从 ReAct 向多 Agent 演化的关键节点。核心思想是引入专门训练的 ReSumTool 摘要模型,对不断膨胀的交互历史进行周期性压缩,将系统状态浓缩为紧凑的"reasoning state"。摘要模型在主 Agent 训练之前通过监督数据单独训练,强化学习阶段只优化主模型。从架构看已形成"主 Agent(搜索与决策)+ 摘要器(长期记忆管理)"的双模型协作形态。
阶段三:多智能体系统
- MMOA-RAG:由 Retriever、Selector、Generator 三个协作 Agent 组成,各自独立优化
- C-3PO:Compact Plug-and-Play Proxy Optimization,多 Agent 通过结构化状态通信,训练阶段实现协同优化
- WebResearcher:将 DR 任务建模为多阶段长时序迭代过程,主研究者 Agent、上下文管理器和并行探索器协作生成不断演进的报告(evolving report)
奖励设计:仅结果 → 分阶段 → 多角色 → 双层信用分配
奖励机制的发展聚焦于如何在多步骤任务中实现更细粒度的信用分配(credit assignment)。
仅结果奖励(Search-R1):以最终答案正确性作为唯一奖励信号。简单直接,但在长链任务中信号稀疏,优化效率有限。使用 GRPO 算法,组内相对归一化计算优势:
分阶段奖励(R1-Searcher):将检索行为与推理结果分开评估,模型在"是否发起检索、检索哪些信息"上获得明确反馈。
多角色奖励(MMOA-RAG):为 Retriever、Selector、Generator 三个 Agent 设计独立奖励信号,每个角色按自身职责被优化。
蒙特卡洛信用分配(C-3PO):对每一次搜索、点击或判断动作进行轨迹采样,通过蒙特卡洛方法计算每个动作对最终结果的贡献度,实现更细粒度、更稳定的信用分配。
双层信用分配(GiGPO, Group-in-Group Policy Optimization):一层评估整个 episode 的相对优势(组间比较),另一层基于锚点状态对每一步决策进行微观优势估计(组内比较)。无需外部 critic,直接融入 GRPO 框架。虽非专门针对 DR,但其多步骤多角色训练机制对 DR 场景的 RL 优化极具参考价值。
数据构建:QA → CRAWLQA → E2HQA → WebSailor-V2 → WebResearcher
训练数据的演化路径清晰反映了任务复杂度的提升:
基础 QA(Search-R1, R1-Searcher):依赖 HotpotQA 等基于 Wiki 的多跳问答数据集,提供问题-答案对和推理路径,但不包含真实的搜索/点击行为序列。大多数问题较浅,一两步搜索即可解决。
CRAWLQA + E2HQA(WebDancer):两类数据互补。CRAWLQA 从真实网站抓取根 URL 并递归访问子页面,记录完整的浏览轨迹(Thought-Action-Observation),使模型学习完整的网页操作行为。E2HQA(Easy-to-Hard QA)从简单问题逐步生成更复杂的多跳问题,在推理复杂度上递进。
知识图 + 遮掩扰动(WebSailor-V2):将网页内容组织为密集互联的知识图(有循环和多路径依赖,而非简单树状结构),同时对网页信息进行随机遮掩和扰动构造"高不确定性任务"。模型必须学会反复确认信息、迭代搜索、在信息不完整下仍能合理推理。
三阶段数据引擎(WebResearcher):面向长 horizon 多步骤 research 任务。阶段一从多学科文档中提取信息块,经 Summary Agent 压缩后由 ItemWriter Agent 生成种子 QA 对。阶段二通过工具增强 Agent 迭代升级问题和答案,增加认知复杂度和跨步骤推理要求,每轮输出可作为下一轮种子。阶段三通过 QuestionSolver、Judge 和 SimilarityScorer 等 Agent 进行筛选和验证,剔除过易或错误样本。
23.4 REDSearcher:低成本长程搜索框架
REDSearcher 提供了一条从预训练模型到长程深度搜索 agent 的完整训练路径。其核心突破在于:将深度搜索任务合成建模为图拓扑(treewidth)与证据分散度(MSD)的双约束优化问题,论文报告称,其分阶段训练策略使 30B-A3B 规模的开源模型在部分 benchmark 上取得了接近或超越同期闭源系统的结果(具体评测设定与分数见下文,来源为该论文自报数据,未经独立复现验证)。
双约束任务合成
REDSearcher 回答了一个关键问题:如何刻画深度搜索问题的复杂度? 答案是两个正交维度。
拓扑逻辑复杂度(Treewidth):借鉴算法理论中的经典洞察——图结构问题的计算难度取决于底层图的树宽。给定查询的逻辑结构图
推理代价近似为
直觉上:链式推理
信息源分散度(Minimum Source Dispersion, MSD):treewidth 刻画结构耦合,但不能完全决定搜索难度——单个综合文档可能包含多个关联事实,形成"快捷检索"。MSD 定义为覆盖所有推理节点所需的最少文档数:
当
分阶段训练策略
REDSearcher 的训练流水线分为 Mid-training 和 Post-training 两大阶段:
Mid-training Stage I(32K 上下文,~90B tokens)——原子能力:
- 意图锚定提取(Intent-anchored Grounding):在嘈杂网页环境中根据推理意图精确识别缺失信息。通过反向 QA 合成 + 干扰项训练模型在噪声中精确提取
- 层次规划(Hierarchical Planning):将问题的求解入口分为"具体目标"(明确查询意图)和"模糊目标"(需通过查询缩小不确定性),利用知识图谱拓扑结构生成规划
Mid-training Stage II(128K 上下文,~10B tokens)——复合交互:
- Agent 工具使用:用 LLM 生成工具集并模拟环境反馈,构建完整 ReAct 多轮工具调用数据,不调用任何外部服务
- 长程交互:构建基于 Wikipedia 和 Web Crawl Dumps 的本地模拟搜索环境,支持 search 和 visit 操作
成本结构的关键设计:Stage I 用廉价合成数据大规模训练(90B tokens),Stage II 在有环境反馈的场景训练复合行为(10B tokens),成本比例约 9:1。这种分离使 downstream SFT/RL 的初始探索成功率大幅提升。
Post-training SFT:标准 next-token prediction loss,mask 环境观测部分不参与梯度更新,128K 上下文。
Post-training RL:使用 GRPO 算法,每个问题 16 个 rollout,二值结果奖励,采用 DAPO 的 clip higher 策略,不使用 entropy loss、KL loss 和格式奖励:
模拟环境与关键实验发现
功能等价模拟环境包含数千万文档,三个设计原则:接口一致性(API 与真实搜索 API 保持一致)、证据完备性(包含所有必要证据)、环境噪声(大量干扰文档)。实现了 URL 混淆流水线防止模型学习 Wikipedia URL 模式偏见。
核心实验发现:
- 30B-A3B 与闭源系统对比:论文报告称,其 Overall 得分 51.6 高于 Claude-4.5-sonnet(41.1)和 OpenAI-o3(49.6);GAIA 得分 80.1 高于 GPT-5-Thinking-High(76.7)。以上数据为论文自报结果,评测条件(推理预算、工具配置、评测时间点等)可能与各闭源系统的最优设定存在差异
- Context management 效果显著:BrowseComp 从 42.1 提升到 57.4(+15.3)
- RL 学会更高效搜索:训练过程中 rollout 长度逐渐下降(平均工具调用次数从 100.6 降至 90.1),但奖励保持稳定或继续提升——模型减少了冗余工具调用
- 工具使用与参数知识解耦:REDSearcher 在无工具模式下得分最低(对参数记忆依赖低),启用工具后大幅提升。tool-enabled 增益比最终准确率更能反映深度搜索能力的真实水平
23.5 Benchmark 概览
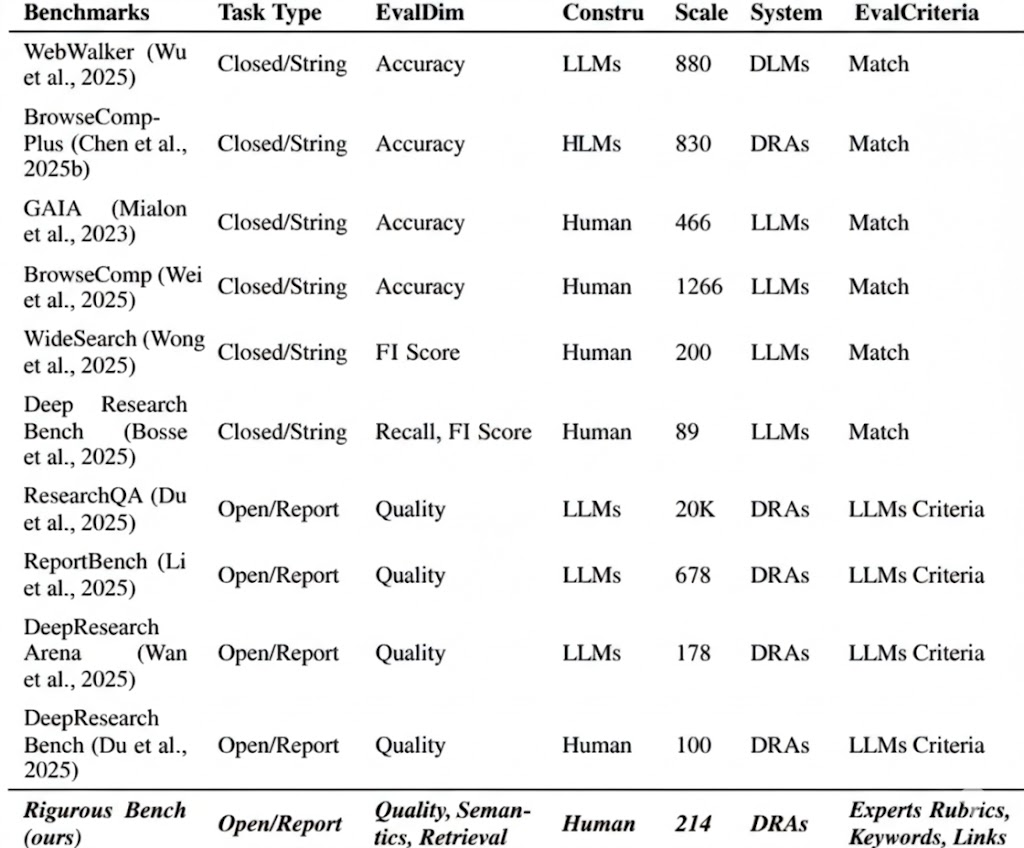
DR 系统的评估沿三个维度展开,复杂度逐级递增:
智能信息搜寻
查询复杂度梯度:
- 单跳 QA(Natural Questions, TriviaQA, SimpleQA)→ 多跳推理(HotpotQA, 2WikiMultihopQA, MuSiQue)→ 深度探索(GPQA 研究生级问题, GAIA 多步推理, HLE 全学科基准)
交互环境梯度:
- 静态语料库 → 实时网络(BrowseComp 要求持续导航定位难找信息)→ 真实网站交互(WebArena, Mind2Web)→ 多模态环境(MMInA)
综合报告生成
这是 Phase II 的核心评估维度。代表性 benchmark:
- Deep Research Bench(89 个高难度多步骤网页搜索任务):核心创新是 RetroSearch 环境,通过冻结并存储网页快照解决评估不可重复的问题。失败模式分析表明:遗忘上下文信息是主要失败原因
- DeepResearch Bench(ICLR 2026):100 个任务(50中文+50英文),从报告质量和来源准确性两方面评估
- ReportBench:根据现有专家综述论文反向生成研究问题,将原论文参考文献作为检索标准答案,量化评估文献检索的精确率与召回率
- Dr. Bench:214 个任务,每个配备 Reference Bundles(查询特定评分标准 QSRs、通用报告评分标准 GRRs、可信来源链接 TSLs、焦点锚定/偏差关键词),提出语义质量、主题聚焦、检索可信度三个指标
- DeepResearch Bench II:132 个任务,源自专家级调查报告,将研究能力细分为信息召回、分析深度和表达呈现三个维度
- MMDeepResearch-Bench:140 个多模态任务,覆盖 21 个领域,评估模块包括 FLAE(报告写作质量)、TRACE(引用忠实度)、MOSAIC(文图一致性)。关键发现:写作质量高的模型不一定在引用准确度上表现好,视觉能力反而增加细节错误
AI for Research
Phase III 的评估维度:
- 创意生成:评估新颖性——从人工评审到基于密度的 RND 算法
- 实验执行:PaperBench 评估 AI 复现论文能力
- 学术写作:Scientist-Bench 涵盖 16 个领域
- 同行评审:DeepReview-Bench 含 1.2K ICLR 2024-2025 投稿
23.6 工程落点
LangGraph 实现的多 Agent 研究系统
LangGraph 的 deepagents 包提供了一个可直接部署的 DR 系统实现,体现了 23.1 中描述的 Orchestrator-Subagent 架构。核心组装只需几行代码:
from deepagents import create_deep_agent
# 定义研究子智能体
research_sub_agent = {
"name": "research-agent",
"description": "Delegate research to the subagent researcher.",
"system_prompt": RESEARCHER_INSTRUCTIONS,
"tools": [tavily_search, think_tool],
}
# 组装:编排器 + 子智能体
agent = create_deep_agent(
model=model,
tools=[tavily_search, think_tool],
system_prompt=ORCHESTRATOR_INSTRUCTIONS,
subagents=[research_sub_agent],
)这个系统的工作流精确映射到 DR 架构的四个阶段:
- Plan:编排器通过
write_todos将研究请求分解为 TODO 列表 - Research:通过
task()工具将子任务委派给 research subagent,子智能体在隔离上下文中执行搜索-反思循环 - Synthesize:编排器收集所有子智能体的发现,合并引用(每个唯一 URL 分配一个全局编号)
- Write Report:输出结构化的最终报告到文件
Prompt 设计的三层结构值得注意:
| 层级 | 对象 | 职责 |
|---|---|---|
RESEARCH_WORKFLOW_INSTRUCTIONS | 编排器 | 定义 5 步工作流、报告格式规范、引用格式 |
SUBAGENT_DELEGATION_INSTRUCTIONS | 编排器 | 何时并行化(显式对比)、何时用单个子智能体(默认)、并发上限 |
RESEARCHER_INSTRUCTIONS | 子智能体 | 搜索工具预算(简单 2-3 次/复杂最多 5 次)、强制 think_tool 反思、停止条件 |
搜索工具 tavily_search 的设计体现了一个重要取舍:它用 Tavily 做 URL 发现,然后自己抓取完整网页内容并转换为 Markdown,而不是使用 Tavily 的摘要。这保留了原始信息的完整性,让 agent 自主决定哪些信息相关——代价是 token 消耗更高。
Subagent Explore:Read-only 代码研究的简化版 DR
Coding agent 中的 subagent explore 模式是 DR 在代码库研究场景的简化版本。当用户提出需要深入理解代码库的问题时,主 agent 启动一个 read-only 子智能体:
- 子智能体拥有 Glob/Grep/Read 等只读工具,在隔离的上下文窗口中探索代码库
- 主 agent 提供研究方向("调查 X 模块的架构"),子智能体返回结构化的发现报告
- 与完整 DR 的区别:没有 web 搜索能力,没有多轮记忆管理,不需要引用验证——但核心的"编排器委派子任务 → 子智能体在隔离上下文中执行 → 返回发现"模式完全一致
这种 read-only research 模式的价值在于:主 agent 的上下文窗口不会被大量代码文件内容污染,子智能体在独立上下文中可以读取更多文件,最终只将精炼的结论传回主 agent。
Subagent + Team 作为 DR 基本积木
DR 的工程实现可以归结为两个基本积木的组合:
Subagent(子智能体):在隔离上下文中执行单一任务,具有自己的 system prompt 和工具集。核心属性是上下文隔离——子智能体看不到主 agent 的完整对话历史,只看到分配给它的具体任务描述。
Team(团队):多个子智能体的组合,由编排器协调。团队的关键设计决策是并发策略:
graph TB
subgraph "串行 Team"
O1["Orchestrator"] --> A1["Agent 1<br>完成后"] --> A2["Agent 2<br>依赖A1结果"] --> A3["Agent 3<br>依赖A2结果"]
end
subgraph "并行 Team"
O2["Orchestrator"] --> B1["Agent 1"]
O2 --> B2["Agent 2"]
O2 --> B3["Agent 3"]
B1 --> M["Merge 结果"]
B2 --> M
B3 --> M
end
subgraph "混合 Team (DR 典型模式)"
O3["Orchestrator"] -->|"Round 1"| C1["Agent 1"]
O3 -->|"Round 1"| C2["Agent 2"]
C1 -->|"发现"| O3
C2 -->|"发现"| O3
O3 -->|"Round 2<br>基于 Round 1 结果"| C3["Agent 3"]
C3 -->|"发现"| O3
O3 --> Final["最终综合"]
endDR 的典型模式是混合 Team:第一轮并行委派多个子智能体,收集结果后编排器评估覆盖缺口,第二轮针对性补充。这种"并行探索 + 迭代补充"的节奏是 DR 区别于简单并行搜索的核心——它引入了跨轮次的反馈闭环。
从实现角度,一个 DR 系统的最小可行配置是:1 个编排器 + N 个同构子智能体(共享相同的 system prompt 和工具集,只是接收不同的任务描述)。扩展配置则引入异构子智能体(搜索专家、代码分析专家、数据可视化专家各司其职),以及专门的记忆管理子智能体(类似 ReSum 的摘要器)。无论哪种配置,核心不变量是:编排器不直接执行研究,子智能体不感知全局计划,通过结构化的委派-返回协议实现松耦合协作。