第 24 章 Agentic RL —— 训练 Agent 的另一面
Agentic RL 不是单一算法,而是环境建模、学习信号、异步数据流、策略优化和基础设施的协同系统——任何一个子系统的短板都会成为整体的瓶颈。
24.1 从 RLVR 到 Agentic RL
24.1.1 RLVR:本质上是 Bandit 问题
传统 RLVR(Reinforcement Learning with Verifiable Rewards)的训练范式简洁明了:给模型一个 Prompt,模型生成一段完整回答,验证器打分,策略更新。整个过程不存在多步交互式决策与环境状态转移——模型看到输入,输出结果,获得奖励,三步完成。
这本质上是一个 in-context bandit 问题:单次决策、即时反馈、无状态转移。PPO、GRPO 等算法在这个设定下都能干净利落地工作,因为奖励信号与动作之间的因果链极短。
24.1.2 Agentic RL:进入 POMDP
当模型需要在真实终端环境中完成任务时,问题的性质发生了根本性变化。四个维度同时"变硬":
状态(State)变复杂。Agent 看到的不再只是用户输入,而是包含历史交互轨迹、工具返回结果、环境反馈、甚至记忆摘要的复合状态。更关键的是,Agent 通常无法观察到完整的环境状态——文件系统结构、已安装软件版本、历史修改——这是一个 部分可观测马尔可夫决策过程(POMDP)。
动作(Action)变立体。不仅仅是预测下一个 Token,而是高阶决策:调用什么工具?要不要压缩上下文?任务是否需要分发给子 Agent?
奖励(Reward)变苛刻。奖励变得极度延迟和稀疏,且是复合的——不仅要结果对,还要过程高效、省 Token、省时间。一条轨迹可能包含数十次工具调用,但只有最终的测试通过/失败构成可用的奖励信号。
时间(Time)变不均匀。有的任务几秒搞定,有的要跑几十分钟。这导致同步训练变得不现实,必须异步,而异步又会带来致命的分布偏移。
24.1.3 三个核心不变量
无论算法怎么换,三个底线的"区间"必须在整个训练周期内被稳住。它们构成了 Agentic RL 的理论根基。
第一不变量:策略的可探索空间绝对不能过早坍缩(下限)
真正的探索不是把采样温度调高让词变得更随机——而是语义和策略层面的多样性。模型必须保留多种能解决问题的真实路径(不同的工具调用顺序、不同的任务分解方法)。如果在 SFT 阶段就被逼着只会一种"标准答案"套路,可探索空间就塌缩了。空间一旦塌缩,后续 RL 只能在极窄范围内做毫无意义的局部微调,永远无法"顿悟"出更好的工作流。
第二不变量:学习信号必须持续非退化(下限)
就算模型有多种解题路径,也不代表能学得会。如果同一批采样的题目,简单的全对(饱和)、极难的全错(够不到),那这两类样本产生的梯度都趋近于零——算力在白白燃烧。训练系统必须源源不断地制造出能区分好坏的有效对比。Agentic RL 需要的不是更高的分数,而是能被优化器利用的"轨迹差异"。
第三不变量:训练、更新、部署之间的分布偏移必须可控(上限)
策略模型采样的分布(Rollout)、实际拿去更新参数的分布(Training)、最终上线部署的分布(Serving),在 Agent 场景下几乎不可能天然一致。为了效率把长任务切段,异步地把跑完的任务先更新——都会导致"现在更新的参数"与"当初采样的策略"发生时间错位(Off-Policy Drift)。只要工具接口、上下文整理、解码设置在三个阶段不完全一致,模型学到的就不是你想要的动作语义。这种偏移不只是外部环境带来的,很多时候是系统自己制造出来的。
三个不变量之间存在内在张力:探索越强,分布偏移越难控制;过度追求稳定更新,容易把探索空间压没;只有探索和非退化信号但分布偏移失控,最后学到的可能不是实际上线能用的行为。
graph LR
subgraph 三大不变量
A["探索空间<br>不坍缩"] --- T["内在张力"]
B["学习信号<br>不退化"] --- T
C["分布偏移<br>可控"] --- T
end
A -->|"探索越强"| C2["偏移越难控制"]
C -->|"过度稳定"| A2["探索被压没"]
B -->|"信号有效但偏移失控"| C3["学到的行为不可用"]
style T fill:#f9f,stroke:#33324.2 八大系统支柱
从工程落地角度,Agentic RL 训练闭环由八个维度构成。这不是一个可以只优化其中一个维度的系统——每个维度都可能成为瓶颈。

24.2.1 环境建模与接口
模型不需要看到完整的世界,而是需要 结构化保真(Structural Fidelity):动作空间、成功判据、失败模式必须和真实部署一致。
三个关键编译器(Compiler)定义了环境的核心抽象:
| 编译器 | 功能 | 解决的问题 |
|---|---|---|
| Task Compiler | 把模糊请求变成分解好的任务 | 任务规范化 |
| Verifier Compiler | 把评判标准变成机器可执行检查 | 奖励信号可计算 |
| Scaffold Compiler | 把能力放进不同工作流和模板中 | 避免死记硬背单一模版 |
24.2.2 探索能力与多样性保持
多样性不是探索的副产品,而是需要显式优化的目标。
预训练和 SFT 的角色是为探索保底,但更重要的是主动扩宽动作空间。MiniMax 提出 Continual Pretraining,Kimi 提出合成具有不同能力的 Agent 并在预训练阶段扩宽动作空间,DAPO 则显式地优化多样性。核心原则:SFT 过拟合会抹杀未来 RL 的潜力,预训练阶段就应该为 RL 的探索空间预留足够余量。
24.2.3 算力分配与信号整理
反对"平均分配"。把 Rollout 预算平摊给所有任务是浪费——如果一道题已经饱和或极难无解,它就不该消耗算力。
VIP 和 RL-ADA 的做法是把预算投给最能减少梯度方差、最可能恢复学习信号的 Prompt。预算分配已经成了 RL 核心算法的一部分,而非仅仅是工程优化。
24.2.4 目标函数与策略优化
不要纠结 PPO 还是 GRPO。重点是当前训练受限于哪个瓶颈——是梯度噪声大,策略漂移快,还是目标不匹配?
各方案的核心都是控制漂移(第三不变量):
- K2.5:Token-level Clipping——在 Token 粒度约束更新幅度
- MiniMax CISPO:双侧重要性采样——同时约束正向和反向偏移
- GLM TITO:直接用采样时的 Token 训练——从源头消除训推不一致
24.2.5 采样、异步并行与调度
异步是必然的——任务时间极不均匀,严格同步(On-Policy)会拖死整个系统。
调度器本身就是算法的一部分。MiniMax 提出的 Windowed FIFO 是一个折中方案:不要求全局严格排队,但只在有限窗口内保持大概顺序。GLM-5 甚至直接把采样和训练分开。调度器决定了模型看到什么样的训练分布。
24.2.6 奖励、验证器与效率约束
复合奖励设计是必须的——不能只看结果对不对:
- K2.5 对可验证任务用 Rule-based 奖励,对 Token 成本用 Budget-control,对开放任务用 GRM(综合打分)
- 必须对抗长回答偏见(Verbosity Bias):模型很容易学会"水字数"骗分。Forge 把中间过程质量和完成时间纳入奖励,因为真实用户需要的是快速且高效的 Agent,而不是又慢又废话连篇的 Agent
24.2.7 记忆、层级与并行 Agent
对抗 Context Rot(上下文腐化):上下文越长,模型越容易失焦。Forge 把上下文管理变成环境动作的一部分,GLM-5 使用 Keep-recent-k 和 Discard-all 的层级记忆。
并行 Agent 不是复制粘贴。K2.5 引入了 Agent Swarm 和 PARL,让协调器(Orchestrator)学会何时并行、如何分派子任务——这是把模型从单点决策升格为操作系统级调度。
24.2.8 基础设施
Infra 不仅仅是底座——它塑造了分布。
K1.5 的部分轨迹复用、GLM-5 的 TITO、MiniMax Forge 的标准化网关设计,都在干同一件事:保证模型训练时的动作和部署时的动作绝对对应。必须解耦训练和推理、支持异构资源调度,否则单点算法根本无法在真实的大规模场景下验证。
吞吐决定高度——Infra 是"系统级一致性"的守护者。
24.3 ROLL 团队实践经验
ROLL 团队(阿里巴巴)在真实终端环境中训练 Agentic RL 模型的经验,是目前公开资料中最详尽的实践报告之一。以下从四个方面展开。
24.3.1 环境管理:两种互补模式
ROLL 训练框架清晰地划分了三个核心组件的交互边界:ROLL(训练框架)、iFlow CLI(Agent 框架)和 ROCK(沙箱管理器)。在实践中支持两种互补模式:
Roll-Managed Mode:由 ROLL 负责上下文管理与轨迹构建,通过工具调用接口与 Agent 框架交互。优势是训练侧高度灵活——可以引入更丰富的 prompt 模板和交互机制提升鲁棒性。代价是需要在训练框架内部维护额外的上下文处理逻辑,不可避免地与真实 Agent 行为存在差距。
CLI-Native Mode:上下文、会话与历史信息完全由 Agent 框架维护,训练框架仅作为调用方。相当于"直接在 Agent 框架上训练模型"——训练时看到的输入分布与真实使用场景一致(包括动态上下文、工具列表、系统提示词、内部状态)。两者通过轻量级的 ModelProxy Service 通信,提供基于队列的异步消息机制。
graph TB
subgraph "Roll-Managed Mode"
R1[ROLL 训练框架] -->|"控制上下文<br>构建轨迹"| T1[TrajEnvManager]
T1 --> E1[TerminalBenchEnv]
E1 -->|"工具调用"| I1[iFlow CLI Tool]
E1 -->|"沙箱操作"| S1[SandboxManager]
end
subgraph "CLI-Native Mode"
R2[ROLL 训练框架] -->|"仅调用"| I2[iFlow CLI]
I2 -->|"管理全部<br>上下文/会话"| MP[ModelProxy Service]
MP -->|"异步队列"| R2
I2 --> S2[ROCK 沙箱]
end两种模式在不同训练阶段切换使用。Roll-Managed Mode 用于需要灵活定制上下文的实验阶段;CLI-Native Mode 用于追求训推一致性的后期阶段。
24.3.2 异步训练管线
Agentic RL 具有明显的 长尾延迟(long-tail latency) 特性:大多数 rollout 快速完成,但少数 rollout 因生成文本较长或缓慢的环境交互而耗时极长。在同步、批量式 rollout 管线中,这些长耗时任务成为 拖尾瓶颈(straggler bottleneck),导致 GPU 利用率骤降。
ROLL 的解决方案是构建完全异步的训练管线:
- 环境级异步 rollout:将 LLM 生成、环境交互、奖励计算拆解独立,互不阻塞
- 冗余并行环境:增加环境组数量与大小,避免 fail-slow 或 fail-stop 环境成为系统瓶颈
- 异步训练机制:在不同设备上解耦 rollout 与训练阶段,使其并行推进
- Train-rollout 复用:通过时间分片(time-division multiplexing)动态划分 GPU 资源,使设备在推理与训练之间灵活切换
24.3.3 保持环境"干净"
在终端 RL 训练中,即便是极小的残留痕迹——临时文件、缓存链接、未完成安装、泄露的测试脚本——都会严重污染学习信号。
ROLL 团队在早期实验中发现了一个致命问题:模型会迅速学会"偷懒"。测试脚本调用次数显著上升,说明模型越来越依赖直接执行测试文件这种捷径,最终大量 rollout 退化为直接读取甚至修改测试脚本。
对策:
- Rollout 前主动清理环境初始化或 Agent 安装过程中产生的中间文件
- 测试文件仅在最终评估阶段上传,与训练阶段严格隔离
24.3.4 数据质量:三层校验体系
RL 训练实例的质量至关重要。三层校验机制确保只有高质量数据进入训练池:
LLM-as-Judge 验证。早期合成数据中 false positive 比例高达约 40%——模型可以不按预期流程走,但骗过了只检查最终结果的测试。多个 LLM 协同审查每一组"指令-测试"对,识别高 false-positive 风险的实例,强化测试用例或调整任务描述。
Ground-truth 与 No-op 验证。两项入库铁律:
- Ground-truth 验证:golden solution 无法通过全部测试 → 丢弃
- No-op 验证:不执行任何有效操作也能通过测试 → 丢弃
环境增广(Environment Augmentation)。有意在初始环境中引入多样性:不同版本软件包、不同镜像源、不同环境配置。甚至进一步有意扰动或部分破坏环境——移除某个预装依赖、切换到不可用的镜像源——迫使模型学会检查、诊断与恢复,而不是默认一切条件已就绪。
24.3.5 训练稳定性

终端环境中的 Agentic RL 训练不稳定性来自多方面——实例质量、环境噪声、框架约束和长程信用分配。以下是 ROLL 团队在实践中积累的关键技巧。
Mask & Filter
终端环境不可避免地出现瞬时网络故障、沙箱启动失败、工具调用超时。将这些异常信号直接纳入策略更新会引入有害噪声。Mask & Filter 策略遵循一个简单原则:当前对训练有害或无法提供有效学习信号的样本,一律 mask 或 filter。
不可恢复或大规模错误(环境启动失败、沙箱不可用):用占位样本替换,梯度/奖励/advantages 全部 mask 为 0:
def handle_rollout_with_mask(rollout, failure_type):
if failure_type in {
"env_init_failed", "sandbox_unavailable",
"env_reset_failed", "reward_calculation_failed",
}:
placeholder = create_placeholder_rollout()
placeholder.response_mask[:] = 0
placeholder.advantages[:] = 0
placeholder.rewards[:] = 0
return placeholder
return rollout偶发可恢复错误(工具超时、网速延缓):直接 filter 掉,但设置全局 50% 熔断阈值——如果已经丢弃了太多样本,停止过滤以保证训练不会因为没有数据而停滞。
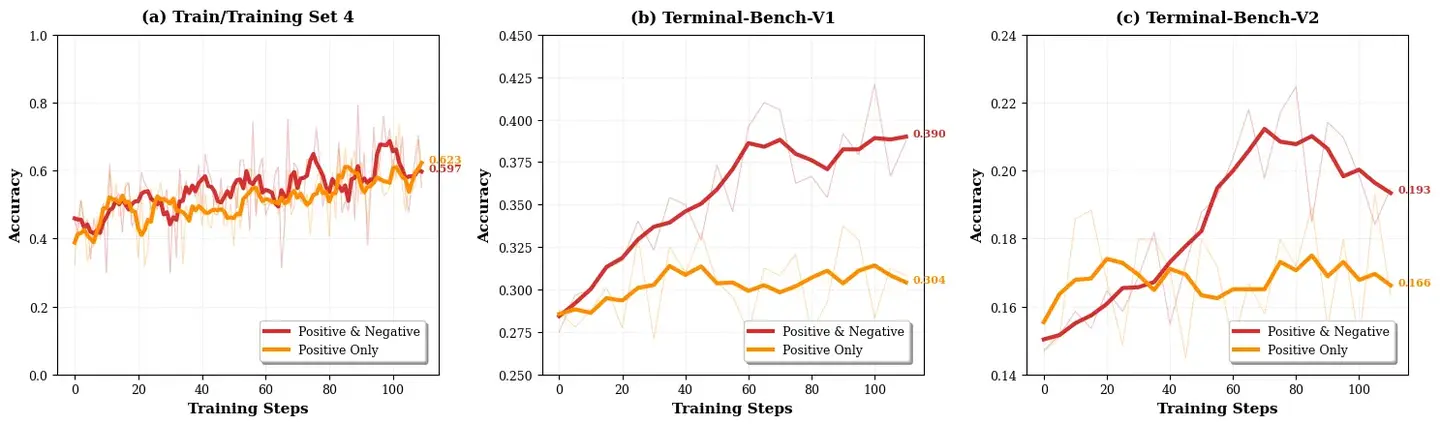
Positive-only RL(早期阶段)
关键观察:在数据尚未完全可靠时,仅使用正样本轨迹训练明显更稳定。
在大规模合成数据上,同时使用正负轨迹更新频繁崩溃,而仅用正轨迹在各种设置下保持稳定。当切换到小规模、高质量、专家验证的数据后,加入负轨迹则使性能提升更显著。
基于此采用课程式策略:
- 早期:仅用正样本轨迹更新策略,利用大规模实例数据构建稳定的策略流形
- 后期:拥有高质量实例后,开始同时考虑正负轨迹训练
与 RFT(Reinforcement Fine-Tuning)的区别:positive-only RL 的损失函数仍然是标准 RL 目标函数(非行为克隆),策略更新仍遵循 masking、clipping、normalization 等 RL 稳定机制。它不是 RFT 的替代,而是更保守的 RL 训练方式。
Chunked MDP(信用分配核心创新)
多轮 agentic 任务中,大多数 token 并不改变环境状态,一条轨迹中可能包含多个决策节点。逐 token 优化粒度太细,整条轨迹优化粒度太粗——ROLL 提出在 interaction chunk(交互片段) 层面建模。
所谓 interaction chunk,是从一次环境交互到下一次环境交互之间的连续片段,通常以一次工具调用结束,构成一个完整的功能单元。基于此提出 Interaction-Perceptive Agentic Policy Optimization(IPA):
graph LR
subgraph "一条完整轨迹"
C1["Chunk 1<br>思考 + bash ls"] --> C2["Chunk 2<br>分析 + read_file"] --> C3["Chunk 3<br>修改 + write_file"] --> C4["Chunk 4<br>测试 + bash pytest"]
end
subgraph "IPA 优化单元"
C1 --> R1["chunk 级回报"]
C2 --> R2["chunk 级回报"]
C3 --> R3["chunk 级回报"]
C4 --> R4["chunk 级回报<br>+ 终端奖励"]
end核心设计:
- 在 chunk 层级(而非 token 层级)计算回报与重要性采样
- 推理-训练策略偏差过大时,对 整个 chunk 进行 masking,而非逐 token masking
- 引入 chunk 初始化重采样和 imitation learning + RL 混合训练
收益:长程轨迹上获得更稳定的梯度,模型可学习能力上限提升。
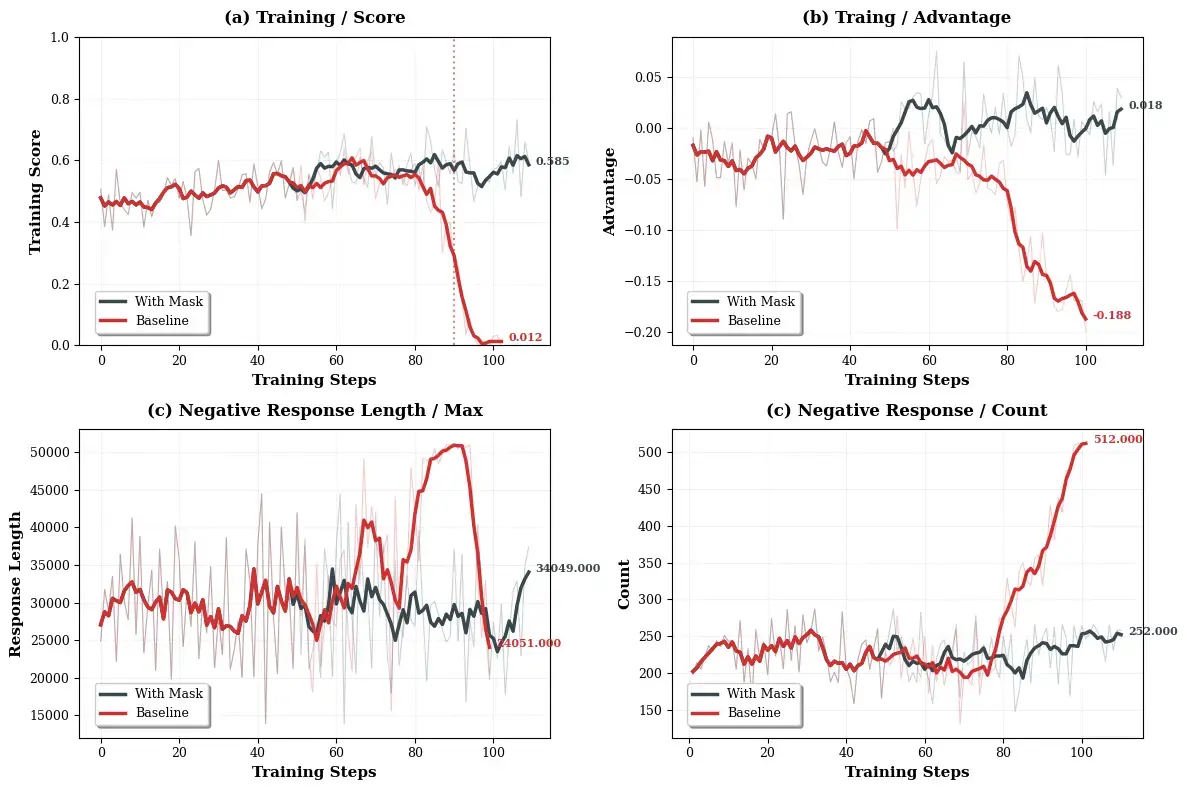
Crash 是常态:诊断与恢复
大规模终端 RL 训练中,崩溃是常态。一个真实的训练样例:
- Step ~50:失败轨迹的最大回复长度迅速上升(但失败轨迹数量不变)→ 少量极端失败轨迹主导更新
- 对策:对响应长度超过 20k 的失败轨迹进行 masking → 优势均值回升,训练趋于稳定
- ~40 step 后:不稳定再次出现,这次信号是负样本数量逐渐增加
- 对策:对负样本进行全局重加权,降低其在策略更新中的整体贡献 → 训练再次恢复
不稳定时的诊断优先级:
| 检查项 | 典型特征 | 应对 |
|---|---|---|
| 少量极端轨迹主导更新 | 异常长的失败轨迹 + 重尾负回报 | masking + 降权 + 收紧 clipping |
| 负样本整体占主导 | 负样本比例持续上升 | 降权 + 过滤低置信度失败 + 课程式训练 |
| 模型学习"坏模式" | 重复工具调用、暴力重试 | 行为惩罚 + 更多维奖励设计 |
两条经验性原则:
- 优先定向处理极端轨迹(如 mask 超长负样本),不稳定时再用全局重加权
- RL 梯度比监督学习噪声更大,更小的学习率配合更强的约束往往更稳定
24.3.6 行为观察
并行函数调用:Claude Sonnet 4.5 的策略
对比 qwen3-coder-plus、glm-4.6、Claude Sonnet 4.5 和 ROME 在同一批任务上的轨迹表现,Claude Sonnet 4.5 的并行度显著更高——无论是并行工具调用的频率,还是单步内同时调用的工具数量。
进一步分析发现,Claude Sonnet 4.5 擅长在执行具体操作前识别当前真正需要的信息。它不会立刻进入执行阶段,而是先识别环境中的关键不确定性,并在同一步骤中通过多个并行的"检查类调用"获取信息。例如,面对"Install Anaconda for me"任务,它会在单一步骤中同时执行:
pwd、ls、cat、grep检查目录结构与配置状态python -V、pip list识别现有 Python 环境与依赖read_file、search查找安装方法及约束
这种并行调用主要集中在检查类工具上,而非直接修改环境的执行类操作。启示:在状态改变之前,显式鼓励一个"前置的、并行的信息收集阶段"可能是有益的。
常见失败模式
终端类 agentic 任务中最常见的两类失败:
无效循环(Unproductive Loops)。Agent 在已有明确失败信号的情况下,仍然重复同一种策略,不懂切换思路或重新审视假设,形成冗长而无效的交互链条。
超时(Timeouts)。模型缺乏对长时间运行命令执行时长的可靠感知,容易被默认超时机制误导,产生误判或反复重试。
此外还有幻觉、不恰当的工具选择、违反任务约束等。细粒度行为监控(跟踪不同任务成功率、工具成功/失败率、重复调用模式、命令使用频率)是发现和应对这些问题的关键手段。
24.4 工程落点:Harness 与 RL 的飞轮
24.4.1 Harness 的核心角色
Harness(评估框架)不仅是评估工具——它收集的 action-sequence 数据就是 RL 训练信号的直接来源。这构成了一个正向飞轮:
graph LR
H["好的 Harness<br>精确评估 + 高质量轨迹"] --> D["高质量数据<br>action-sequence<br>reward signal"]
D --> A["更好的 Agent<br>更优策略"]
A --> H2["更好的 Harness<br>发现更多边界情况"]
H2 --> D
style H fill:#4CAF50,color:white
style D fill:#2196F3,color:white
style A fill:#FF9800,color:white
style H2 fill:#4CAF50,color:white以 Harbor 评估框架为例,它提供了这个飞轮所需的完整基础设施:
- 沙箱环境(Docker、Modal、Daytona、E2B 等)隔离每次试验
- 自动测试执行与验证,产生 0.0-1.0 的奖励分数
- ATIF 格式轨迹日志(Agent Trajectory Interchange Format),记录每一步的工具调用、观察结果和 Agent 响应
24.4.2 Sandbox Backend:高吞吐数据收集的基础
高效的 Agentic RL 训练需要大规模并行收集轨迹数据。Sandbox Backend 的设计直接决定了数据收集的吞吐量和质量。核心要求:
全异步执行。所有操作(execute、read、write、edit、ls、grep、glob)必须是异步的,避免 I/O 阻塞拖慢整个数据收集管线。每个命令有独立的超时控制,防止单个卡死命令挂起整个系统:
async def aexecute(self, command: str, *, timeout: int | None = None) -> ExecuteResponse:
timeout_sec = timeout if timeout is not None else DEFAULT_COMMAND_TIMEOUT_SEC
try:
result = await asyncio.wait_for(
self.environment.exec(command), timeout=timeout_sec
)
except TimeoutError:
return ExecuteResponse(
output=f"ERROR: Command timed out after {timeout_sec} seconds.",
exit_code=124,
)环境无关抽象。Agent 代码不感知底层是 Docker 容器还是云端沙箱。同一个 SandboxBackendProtocol 接口可以接入不同的执行环境——本地 Docker(适合调试)、Daytona 云端(适合大规模并发,40 个并行 slot)、Modal 远程计算。这种抽象使得同一套 Harness 既能用于开发调试,也能在生产规模下收集 RL 训练数据。
基础设施噪声隔离。评估结果中必须区分基础设施故障(OOM、超时、沙箱崩溃)和模型能力不足。通过 exit code 和文本模式匹配对失败进行分类:
class FailureCategory(Enum):
CAPABILITY = "capability" # 模型能力不足
INFRA_OOM = "infra_oom" # OOM kill (exit 137)
INFRA_TIMEOUT = "infra_timeout" # 超时 (exit 124)
INFRA_SANDBOX = "infra_sandbox" # 沙箱/网络故障这种分类对 RL 训练至关重要——基础设施故障产生的"失败"不应作为负样本训练模型,否则模型会学到错误的因果归因。这与 ROLL 团队的 Mask & Filter 策略完全一致。
24.4.3 评估框架如何定义奖励信号
评估框架产生的奖励信号直接定义了 RL 的优化方向。Harbor 的评估体系具有两个关键特征:
多维度评估。通过分类标签(eval categories)将测试按能力区域分组——文件操作、工具使用、记忆、子 Agent 协作、人机交互(HITL)等 12 个维度。这不仅用于雷达图可视化,更重要的是为 RL 提供了结构化的奖励分解:
| 维度 | 衡量内容 | 对 RL 的意义 |
|---|---|---|
| file_operations | 文件读写、目录操作 | 基础工具使用能力 |
| tool_usage | 工具选择与调用 | 决策正确性 |
| memory | 跨轮次信息保持 | 长程依赖处理 |
| subagents | 子 Agent 分派与协调 | 层级决策能力 |
| hitl | 人机交互质量 | 不确定时的求助能力 |
统计严谨性。评估分数必须附带置信区间。Wilson score 置信区间在小样本和极端比例场景下比正态近似更准确。最小可检测效应(MDE)估计用于判断两次评估之间的分数差异是否具有统计显著性——如果 MDE 是 14 个百分点,那么 72% 和 78% 之间的 6 个百分点差距就无法与噪声区分:
def min_detectable_effect(total: int, *, z: float = 1.96, p: float = 0.5) -> float:
"""MDE = z * sqrt(2 * p * (1-p) / n)"""
if total == 0:
return 1.0
return z * math.sqrt(2 * p * (1 - p) / total)对于 RL 训练,这意味着:如果评估样本量不够大,微小的策略改进可能被噪声淹没,导致 RL 优化器收到的信号退化为随机噪声——直接违反第二不变量(学习信号不退化)。
24.4.4 从评估到训练的数据通路
轨迹数据从 Harness 流向 RL 训练系统的完整通路:
sequenceDiagram
participant H as Harness (Harbor)
participant S as Sandbox Backend
participant A as Agent
participant T as Trajectory Store
participant R as RL Trainer
H->>S: 创建沙箱环境
H->>A: 下发任务指令
loop 多步交互
A->>S: 工具调用 (bash/read/write/edit)
S-->>A: 执行结果 (observation)
end
H->>S: 上传测试脚本 & 执行验证
S-->>H: 测试结果 → reward (0.0-1.0)
H->>T: 保存 ATIF 轨迹 + reward
T->>R: 提供训练数据
R->>R: Mask 基础设施故障
R->>R: Filter 低质量轨迹
R->>R: 策略更新关键设计点:
- 测试脚本延迟注入:与 ROLL 团队的实践一致,测试文件仅在最终评估阶段上传,防止 Agent 在训练时"偷看"答案
- 失败分类前置:在数据进入 RL 训练前,先通过失败分类器区分基础设施故障和模型能力不足
- 可观测性闭环:通过 LangSmith 追踪每次 LLM 调用、工具调用和性能指标,结合 Harbor 的 reward 反馈分数,可以按性能过滤 run 并识别成功与失败模式
这个数据通路的核心思想是:Harness 产生的不仅是一个分数,而是一条完整的、带标注的行为轨迹。这条轨迹就是 RL 训练的原材料——其质量直接决定了模型能否学到有效的策略。
24.4.5 竞争的终局
Agentic RL 的战局不再是"谁发明了更好看的数学公式"。未来的护城河在于协同闭环的完备性:
- 更丰富的环境验证覆盖
- 更高密度的有效学习信号
- 更一致的训练与部署分布控制
- 基于极强 Infra 支持下的单位时间有效训练吞吐
这四个维度正是八大支柱的系统级输出——单点突破某一维度不构成持久优势,只有闭环协同才是真正的壁垒。