第 9 章 RAG 与知识工程 —— 检索增强的真实挑战
大多数 RAG 教程只教"装上就跑",回避了真正决定系统能否上线的全部痛点:分块策略、检索噪声、混合检索、reranking、多文档冲突、query rewriting、答案接地与评估。
9.1 RAG 的真实痛点
教程告诉你的 vs 生产环境需要的
主流 RAG 教程的标准流程:
文档加载 → chunk 大小照抄默认 → top-k 恒定 5 → embedding 不解释
→ 检索不分析 → 不做 rerank → 不做 query rewrite
→ 不谈 evaluation → 不讲 error case最后系统"能跑起来"。但能跑和能上线之间隔着一条鸿沟。
真正决定 RAG 质量的痛点矩阵:
| 痛点 | 典型症状 | 教程覆盖情况 |
|---|---|---|
| 分块策略 | 答案被切断,或噪声过多 | 极少讲 |
| 检索噪声 | top-k 中超过一半不相关 | 不分析 |
| 混合检索 | 型号/人名/数字搜不到 | 通常不做 |
| Reranking | 相关文档排在第 5 以后 | 很少提 |
| 多文档融合 | 新旧版本答案混在一起 | 基本不写 |
| Query Rewriting | 用户表述模糊,召回率低 | 偶尔提及 |
| 答案接地 (Grounding) | 模型"合理补充"导致幻觉 | 几乎不谈 |
| 评估 (Evaluation) | 不知道系统到底好不好 | 一片空白 |
不少标榜企业级 RAG 的开源项目,chunk 策略没有、rerank 没有、多文档处理没有、query rewrite 没有、metadata 过滤没有、结构化知识处理没有。跑起来的效果跟"PDF 搜索 + LLM 总结"几乎没区别。
模型太强会掩盖 RAG 的问题
这是最隐蔽的陷阱。现在的基座模型足够强,有时候检索完全没命中正确文档,模型凭自身知识也能答出八九不离十的结果。于是开发者看到模型回得还行,以为 RAG 工作良好。
实际上是模型自己懂,跟你的检索没关系。
验证方法很简单:关掉检索,看模型还能不能答对。如果能,说明你的 RAG 在这个问题上没有贡献。进一步:故意注入错误文档,看模型是跟着错误文档走还是拒绝。如果模型忽略了你注入的文档继续给正确答案,说明它根本没在看你的检索结果。
痛点一:分块策略是"知识单元"的定义
分块(Chunking)不是预处理细节,而是在定义"什么叫一个可检索的最小语义单元"。
固定大小分块的问题:
原文:
一、年假规定
1. 入职满1年不满10年,每年5天带薪年假。
2. 入职满10年不满20年,每年10天。
chunk_size=50 的切分结果:
块1: "一、年假规定\n1. 入职满1年不满10年" ← 条件和结论被分开
块2: ",每年5天带薪年假。\n2. 入职满10年" ← 信息碎片化条件和结论被切断,检索到前半截的块,模型看不到完整规则。
语义分块按自然边界切分:
def smart_chunk(text, max_size=300):
# 第一步:按段落切分(双换行、中文标题标记)
paragraphs = re.split(
r'\n\s*\n|(?=\n[一二三四五六七八九十]+、)|(?=\n\d+\.)', text
)
paragraphs = [p.strip() for p in paragraphs if p.strip()]
chunks = []
for para in paragraphs:
if len(para) <= max_size:
chunks.append(para)
else:
# 第二步:段落过长时按句子切分
sentences = re.split(r'([。.!?!?\n])', para)
current = ""
for sent in sentences:
if len(current) + len(sent) <= max_size:
current += sent
else:
if current:
chunks.append(current.strip())
current = sent
if current:
chunks.append(current.strip())
return chunks核心判断标准不是"300 字是不是最佳值",而是:
- 优先保语义完整,不追求均匀切块
- 中文制度/FAQ/手册类文档天然按标题和段落组织,利用这个结构
- 一旦查询经常落在某个局部规则上,分块就应该围绕该规则来定义
经验值:中文文档 chunk_size 在 200-500 字符之间比较合适。API 文档、代码注释偏小(100-200),技术文章偏大(300-500),长篇报告取 500-800。
重叠分块(Overlap)是固定大小分块的缓解方案:
chunkSize=200, overlap=40:
块1: 字符 0-200
块2: 字符 160-360 ← 与块1 重叠 40 字符
块3: 字符 320-520重叠不解决语义割裂问题,但显著降低关键信息"恰好被切断"的概率。
痛点二:Embedding 模型决定"相似"的含义
如果文档是中文制度、中文 FAQ,却用一个不匹配中文语义的模型做向量化,召回从底层就偏了。
先观察两个指标再做任何调优:
- 区分度:相关文档和无关文档的分数能不能明显拉开
- 鲁棒性:近义表达、改写表达、问句表达能不能召回到同一类片段
如果这两个指标都不稳定,先别调 top-k 或加 rerank,先确认 Embedding 模型是否匹配语料的语言和领域。
常用 Embedding 模型选型:
| 模型 | 适用场景 | 特点 |
|---|---|---|
| OpenAI text-embedding-3-large | 通用中英文 | 效果好,API 成本高 |
| OpenAI text-embedding-3-small | 英文为主 | 成本低,维度小 |
| BCE (netease-youdao/bce-embedding-base_v1) | 中文优化 | 中文区分度高 |
| all-MiniLM-L6-v2 | 离线/隐私敏感 | 零 API 成本,效果一般 |
| BGE-M3 | 多语言混合 | 支持 100+ 语言 |
痛点三:混合检索 —— BM25 + Embedding
纯向量检索最常见的线上事故来源之一:型号、版本号、人名、金额、日期等精确关键词被向量召回排错顺序。
查询: "A7-Pro 多少钱?"
纯向量检索结果:
1. "所有产品均提供一年质保..." ← 语义像但不含 A7-Pro
2. "产品型号 C9-Max 售价 4999 元..." ← 有"产品型号"但不是 A7-Pro
3. "产品型号 A7-Pro 售价 2999 元..." ← 正确答案排第三
混合检索结果(BM25 0.4 + 向量 0.6):
1. "产品型号 A7-Pro 售价 2999 元..." ← BM25 精确命中,直接拉到第一混合检索的实现核心:
class HybridSearch:
def __init__(self, bm25_weight=0.4):
self.bm25_weight = bm25_weight
self.vector_weight = 1 - bm25_weight
def search(self, query, top_k=3):
# BM25 关键词检索
tokenized_query = list(jieba.cut(query))
bm25_scores = self._bm25_index.get_scores(tokenized_query)
bm25_normalized = normalize(bm25_scores)
# 向量语义检索
vector_scores = self._vector_search(query)
# 加权融合
for i in range(len(self._docs)):
score = (self.bm25_weight * bm25_normalized[i] +
self.vector_weight * vector_scores[i])必须带关键词权重的查询类型:
- 型号、工单号、订单号、员工编号
- 日期、金额、数字阈值
- 专有名词、产品名、API 接口名
权重经验值:从 BM25:向量 = 0.4:0.6 开始。关键词匹配很重要则提高到 0.5-0.6;语义理解更重要则降到 0.3。根据评估数据集调整。
痛点四:RRF 排名融合
加权求和之外,RRF(Reciprocal Rank Fusion,倒数排名融合)是另一种更稳健的多路融合算法:
RRF_score(d) = sum( 1 / (k + rank_i(d)) )rank_i(d)是文档 d 在第 i 路检索中的排名(从 1 开始)k是平滑参数,默认 60
文档A 在两路中排名分别为 1 和 3:
RRF = 1/(60+1) + 1/(60+3) = 0.01639 + 0.01587 = 0.03226
文档B 仅在第一路出现,排名为 2:
RRF = 1/(60+2) = 0.01613文档 A 得分更高——在多路中同时出现,比仅在一路中排名靠前更可靠。这是 RRF 的核心直觉:跨多个检索系统的一致认可比单系统的高排名更有说服力。
RRF 的优势在于它不关心原始分数的绝对值,只关心排名。因此词频分数和余弦相似度量纲不同也可以直接融合,无需归一化。
痛点五:Reranking
初步检索(BM25 + embedding)拿到的 top-k 候选,排序通常不够精确。Reranker 用一个 cross-encoder 模型对 (query, document) 对逐一打分,重新排序。
初检 top-5:
1. 语义相关但不直接回答问题的文档
2. 正确答案
3. 噪声
4. 部分相关
5. 噪声
Rerank 后 top-3:
1. 正确答案(cross-encoder 给高分)
2. 语义相关的文档
3. 部分相关Reranker 比 bi-encoder(embedding 模型)精度更高,但计算成本也更高——它需要对每个 (query, doc) 对做一次前向传播,不像 embedding 可以预计算。因此 reranking 通常只对初检的 top-20~50 做,不对全库做。
常用 Reranker:Cohere Rerank、BGE-Reranker、Jina Reranker。
痛点六:Prompt 约束与答案接地
很多 RAG 系统做坏,不是没检索到,而是检索到了以后又让模型自由发挥。
坏 Prompt:
参考资料:{context}
问题:{question}模型看完参考资料后会"好心"补充资料里没有的信息。编造的内容和真实内容混在一起,用户分不清。
好 Prompt:
你是企业知识库问答助手。请严格根据【参考资料】回答。
【核心规则】
1. 只基于参考资料中明确提到的信息回答
2. 如果参考资料中没有相关信息,必须明确说"资料未提及"
3. 绝对禁止推测、补充、编造参考资料中没有的内容
4. 涉及数字、金额、日期的信息必须原文引用,不能近似四条约束的关键不在措辞华丽,而在可执行性:信息源锁死、缺失时明确拒答、数字类原文引用、编造定义为违规。
痛点七:多文档冲突
只要知识库存在新旧版本、部门补充规定、地域差异或流程变更,冲突就是必然问题。
解法是两步:
1. 每个 chunk 带元数据:
chunk_with_meta = {
"content": "...",
"source": "员工手册",
"version": "v3.0",
"date": "2024-01-01",
"status": "现行有效" # 或 "已废止"
}
# 注入上下文时携带元数据
meta_line = f"[来源: {chunk['source']} {chunk['version']} | " \
f"日期: {chunk['date']} | 状态: {chunk['status']}]"2. Prompt 写清冲突优先级:
多文档冲突时,以"现行有效"且日期最新的为准。
已废止的文档只在用户明确问"历史规定"时引用。没有这些显式规则,模型只能自己猜该信哪份资料。
痛点八:评估
RAG 评估的核心指标:
| 指标 | 衡量什么 | 计算方式 |
|---|---|---|
| 召回率 (Recall) | 相关文档有没有被检索到 | 检索到的相关文档 / 全部相关文档 |
| 精确率 (Precision) | 检索到的文档有多少是相关的 | 相关文档 / 检索到的全部文档 |
| MRR | 第一个相关文档排在第几 | 1 / 第一个相关文档的排名 |
| Faithfulness | 回答是否忠于检索到的内容 | LLM-as-Judge 或人工评估 |
| Answer Relevance | 回答是否真正回答了问题 | LLM-as-Judge |
你需要知道:召回率到底多少、捞不到内容时模型怎么答、噪声 chunk 有多少、排序是否有效、文档融合是否混乱、prompt 是否引导正确、哪类问题容易出错。
评估框架参考:RAGAS、TruLens、DeepEval。
生产级 RAG 的排查顺序
修复 RAG 问题有严格的优先级,因为它们是逐层收敛的:
先保证 chunk 切对(召回单元正确)
→ 再保证 embedding 区分度够(相似度判断靠谱)
→ 再补上关键词召回能力(混合检索)
→ 再把回答边界收紧(prompt 约束)
→ 最后处理多文档冲突与来源追踪不要一上来就全上。渐进式升级路径:
- 基础 RAG(向量检索 + 简单 Prompt)—— 先跑通
- 加语义分块 —— 如果答案经常不完整
- 加混合检索 —— 如果关键词搜不准
- 加 Reranking —— 如果相关文档排名靠后
- 严格 Prompt —— 如果大模型爱编造
- 元数据管理 —— 如果有版本冲突
9.2 知识图谱 + RAG
向量检索的根本局限
向量 RAG 解决了"找相似文档"的问题,但它有一个根本局限:它不理解关系。
问题:"张三的同事负责哪些项目?"
文档库:
- "张三和李四是同事,共同在技术部工作。"
- "李四目前负责项目 A 的研发。"
向量检索会为这两段文本分别生成向量,但它无法把它们串联起来
—— "张三 → 同事 → 李四 → 负责 → 项目A" 这条推理链需要关系遍历,
不是余弦相似度能做到的。知识图谱的结构
知识图谱(Knowledge Graph)把信息表示为节点(Entity)和有向边(Relation),天然支持多跳推理。
节点(实体):
张三 (类型: 人)
李四 (类型: 人)
项目A (类型: 项目)
边(关系):
张三 --[同事]--> 李四
李四 --[负责]--> 项目A
项目A --[使用]--> TypeScript多跳推理示例——"张三的同事负责什么项目?"需要走 2 跳:
起点: 张三
第1跳: 张三 --[同事]--> 李四
第2跳: 李四 --[负责]--> 项目A
答案: 项目A端到端实体/关系抽取
真实系统中知识图谱不可能手动构建。有两条路:
NLP 模型抽取:用 spaCy、HanLP 做命名实体识别(NER)和关系抽取。优点是可控、速度快;缺点是需要标注数据、对新领域迁移成本高。
LLM 端到端抽取:直接用大模型从文本中抽取实体和关系。提示词示例:
从以下文本中抽取所有实体和关系,以 JSON 格式返回:
{
"entities": [{"name": "...", "type": "...", "aliases": [...]}],
"relations": [{"from": "...", "to": "...", "type": "..."}]
}参考框架:Microsoft GraphRAG(完整的 LLM 驱动抽取流程)、AutoSchemaKG(自动关系 schema 提取)。
实体别名问题
嵌入模型对算法的不同名称匹配做得很差。例如 LCA、Lowest Common Ancestor、最近公共祖先 —— 三个名字指同一个算法,但向量距离可能相当远。
解法是在知识图谱层面维护别名列表:
// Neo4j Cypher 别名合并
MATCH (e:Entity {name: "LCA"})
SET e.aliases = reduce(
acc = e.aliases, alias IN ["Lowest Common Ancestor", "最近公共祖先"]
| CASE WHEN alias IN acc THEN acc ELSE acc + alias END
)当不同文本块提到同一实体但使用不同表达时,系统自动合并去重别名列表。效果:
- 提升召回率:用户无论使用英文、中文或缩写提问,都能检索到对应实体
- 减少冗余:避免因命名差异产生重复实体节点
- 增强鲁棒性:适应不同领域文献的命名习惯差异
向量 RAG 与 GraphRAG 的互补
| 维度 | 向量 RAG | GraphRAG |
|---|---|---|
| 擅长 | 语义相似检索 | 关系推理,多跳推断 |
| 数据结构 | 向量索引 | 图(节点 + 边) |
| 检索方式 | 余弦相似度排序 | 图遍历(BFS/DFS) |
| 多跳能力 | 弱(需要拼凑) | 强(原生支持) |
| 典型场景 | 文档问答、语义搜索 | 人员关系、供应链、知识推理 |
生产系统通常将两者结合:向量 RAG 召回候选段落,GraphRAG 补充关系上下文,再一起注入 LLM。
多路检索架构
用户问题
├── 向量检索 → 语义相关段落(解题思路、文档内容)
├── BM25 检索 → 精确关键词命中(型号、人名、数字)
└── 知识图谱检索 → 实体关系链(前置知识、算法依赖)
│
▼
RRF / 加权融合
│
▼
Reranking
│
▼
注入上下文 → LLM 生成Agentic RAG
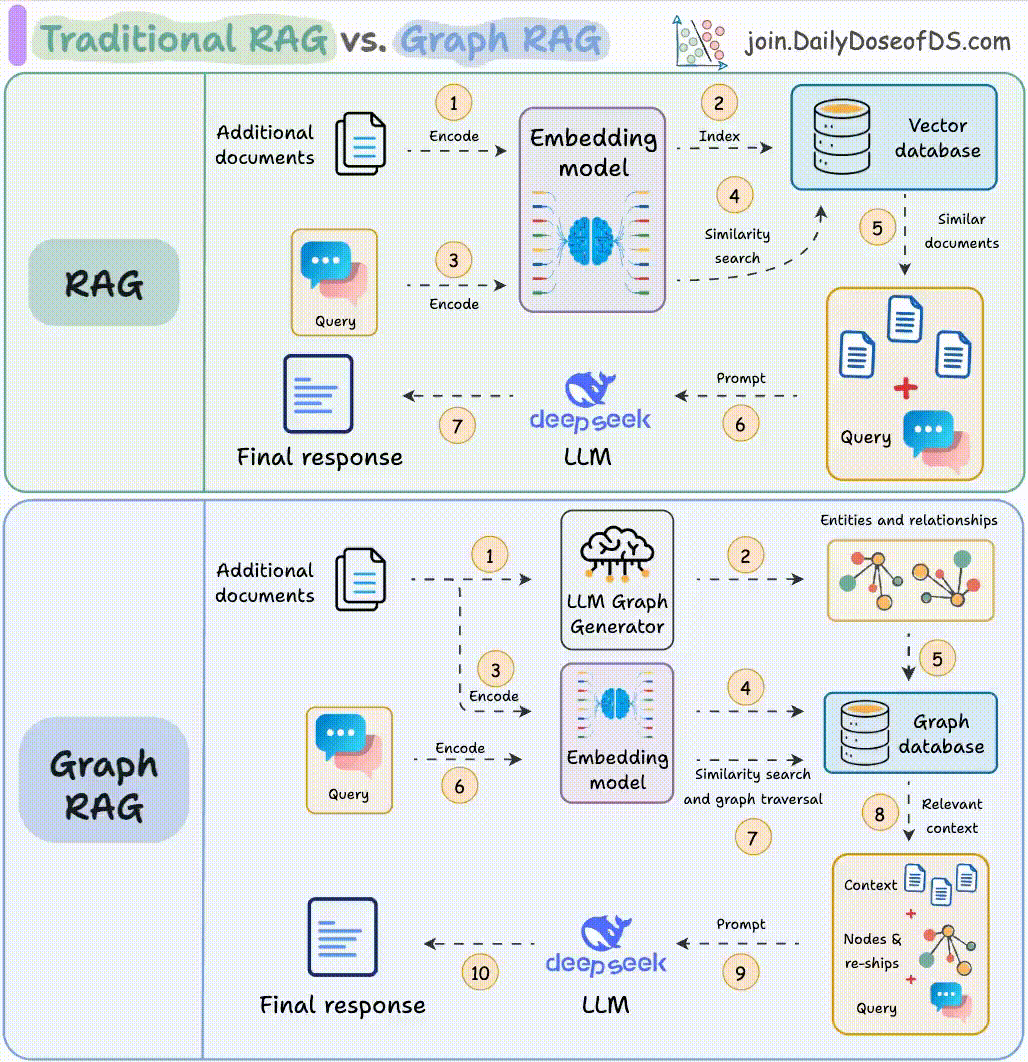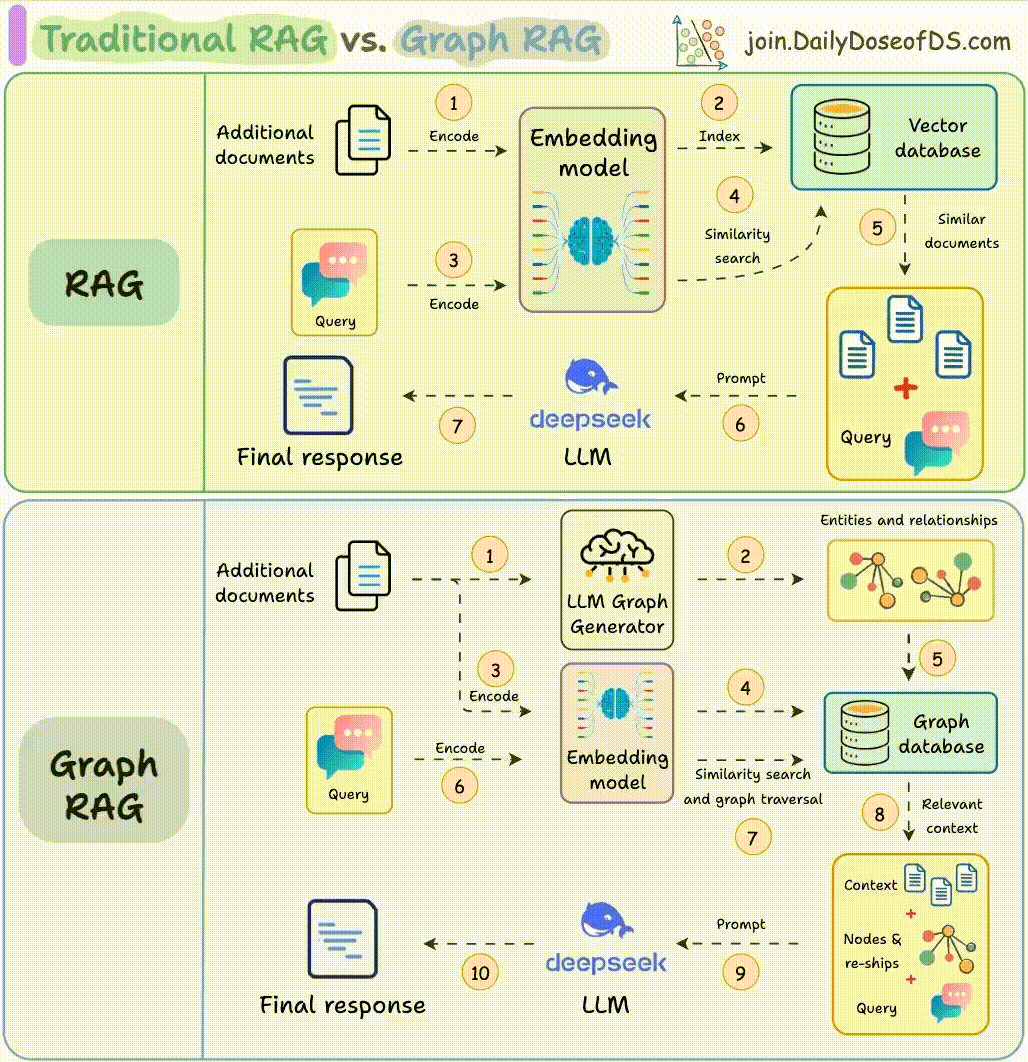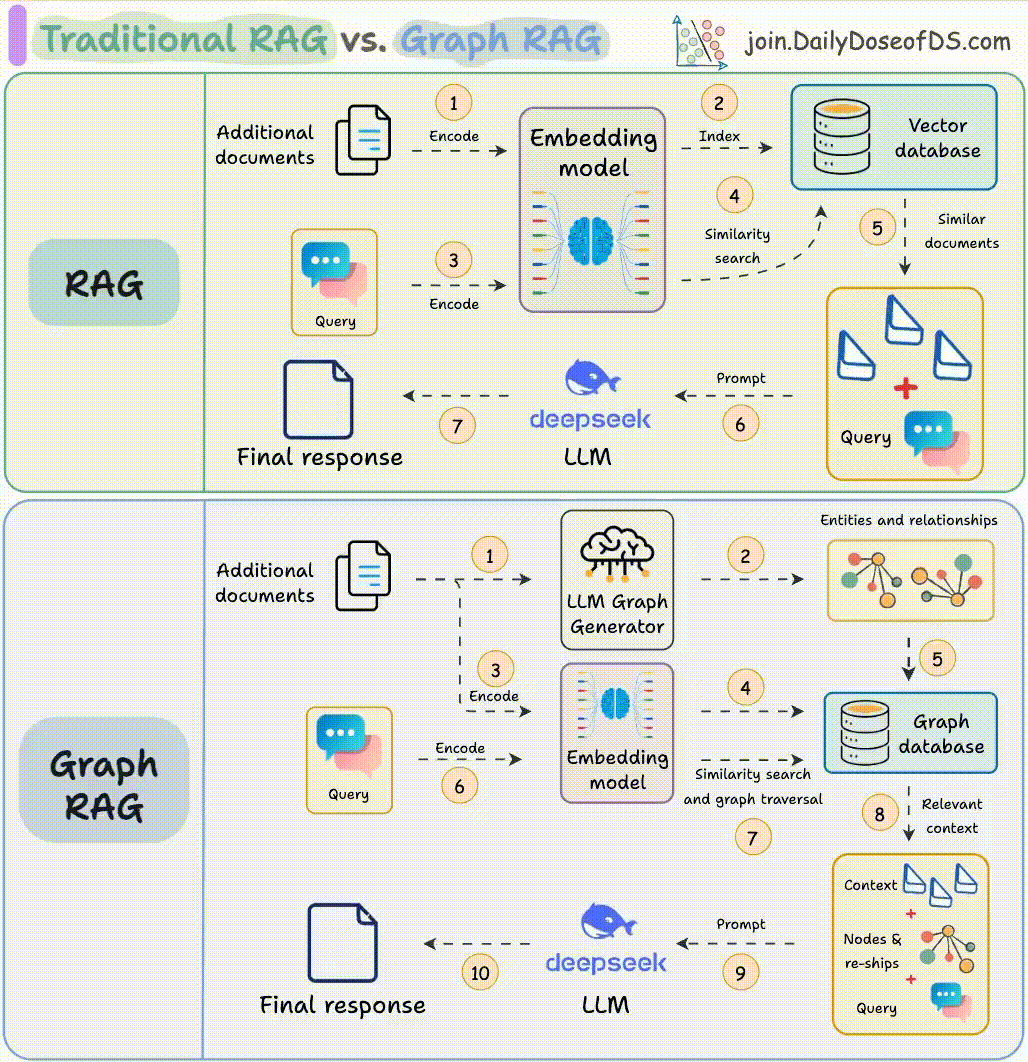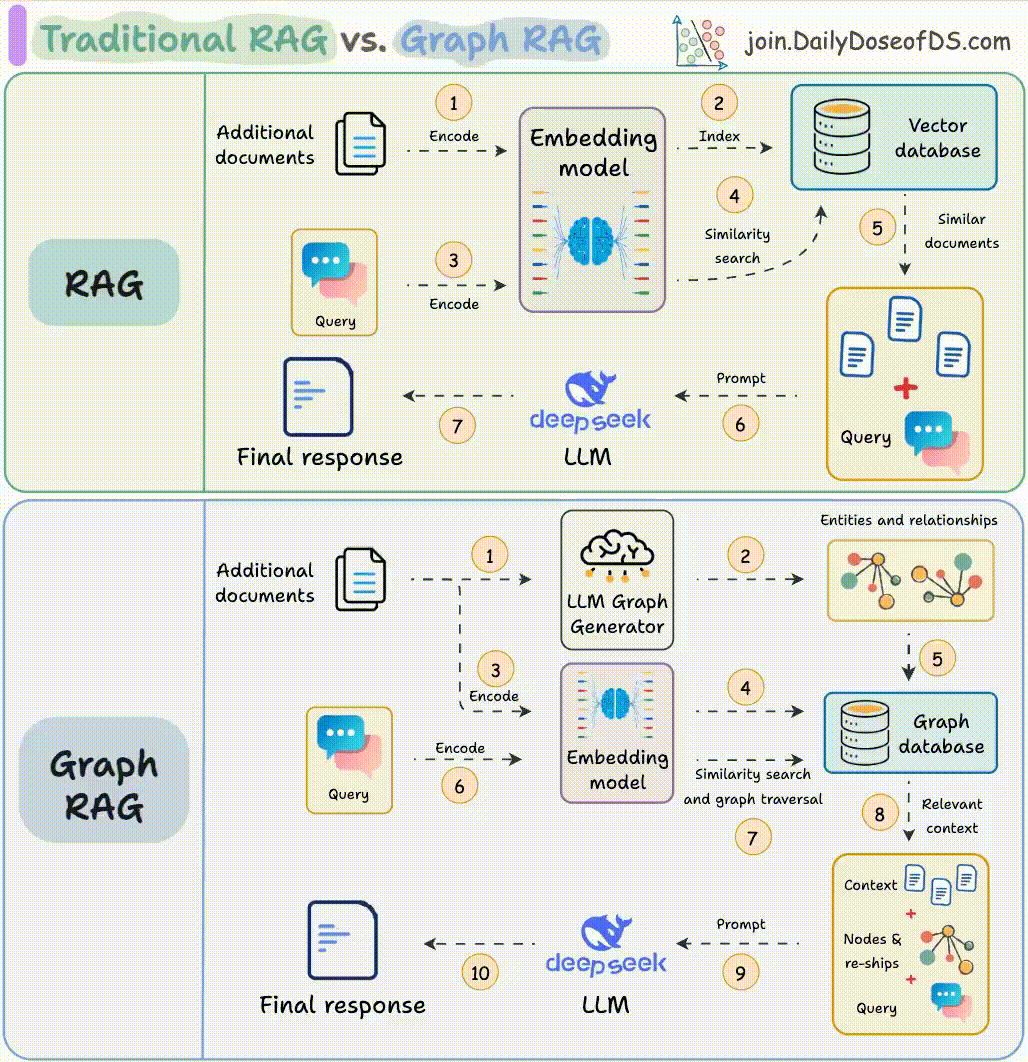
传统 RAG 是一条固定管线:检索 → 注入 → 生成。Agentic RAG 在此基础上引入 Agent 循环,让模型能自主决定:
- 是否需要检索:有些问题模型自身知识足够,不需要检索
- 检索什么:对复杂问题做 query decomposition,将一个问题分解为多个子查询
- 用哪条检索路:向量、关键词、知识图谱、还是联网搜索
- 检索结果是否足够:如果召回质量不够,自主改写 query 再检索
用户问题 → Agent 推理
├── 判断需要检索 → 选择检索路 → 执行检索
│ ├── 结果够用 → 生成回答
│ └── 结果不够 → 改写 query → 再检索(循环)
└── 判断不需要检索 → 直接生成这本质上是 ReAct 循环在 RAG 场景的应用:推理(Thought)决定检索策略,行动(Action)执行检索,观察(Observation)评估检索结果质量,再推理是否需要继续。
RAG 与推理的三个演进阶段
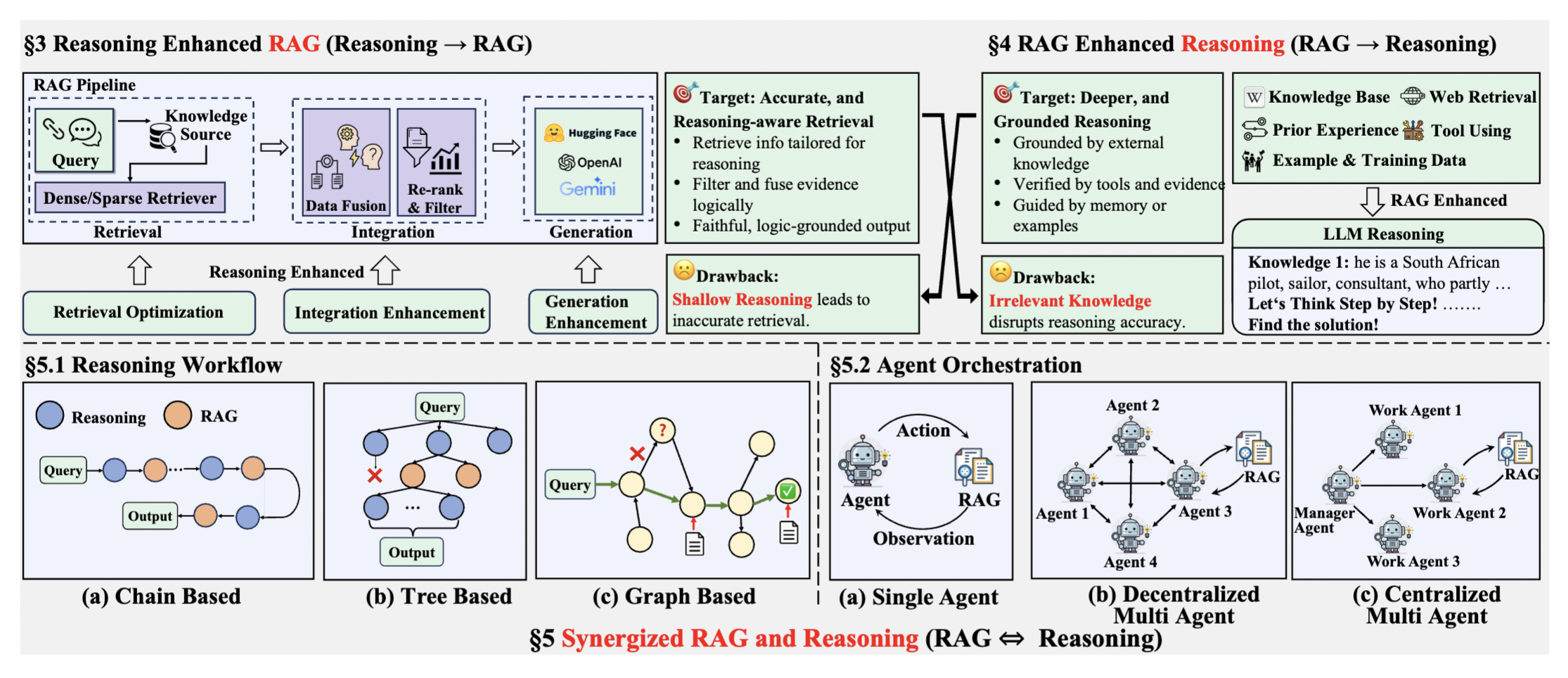
阶段一:推理增强型 RAG(推理 → RAG)
推理技术用于优化传统 RAG 管线的三个核心组件:
- 检索优化:推理感知的查询重构——复杂查询被分解为更简单的子查询,或通过 CoT 提示澄清模糊查询
- 集成增强:推理用于评估检索文档的相关性、过滤噪声、综合异构证据
- 生成增强:确保输出有事实依据且逻辑连贯,实现引文生成将输出链接到来源
阶段二:RAG 增强型推理(RAG → 推理)
检索到的外部知识通过提供缺失前提来增强推理能力。推理失败往往不是因为逻辑不足,而是因为知识不足。包括外部知识库检索(结构化知识、网络内容、工具集成)和上下文内检索(历史经验、有效推理模式)。
阶段三:协同 RAG-推理(RAG ⇔ 推理)
最先进的阶段——检索和推理通过迭代、双向互动深度交织。推理不断完善检索策略,同时新信息塑造持续的推理过程。推理工作流采用复杂结构:链式(交错推理和检索步骤)、树状(探索多个推理路径)、图状(导航知识结构保持事实准确性)。
智能体编排通过单一智能体系统或多智能体框架来管理推理和检索之间的互动:
graph TD
A[用户问题] --> B{Agent 判断}
B -->|简单问题| C[直接回答]
B -->|需要知识| D[检索-推理循环]
D --> E[Query 分解/改写]
E --> F[多路检索]
F --> G[结果评估]
G -->|质量不够| E
G -->|质量足够| H[推理整合]
H --> I[生成回答]
I --> J[事实核查]
J -->|通过| K[输出]
J -->|不通过| D实现参考
- LightRAG:轻量级 GraphRAG 实现,适合快速搭建知识图谱 + RAG 原型
- WeKnora(腾讯开源):企业级知识增强 RAG 框架
- Smolagents(Hugging Face):轻量 Agent 框架,内置 RAG 工具集成
- Neo4j:最成熟的图数据库,Cypher 查询语言,适合生产环境的知识图谱存储
9.3 RAG vs Context Engineering
RAG 是 Context Engineering 的子集
Context Engineering(上下文工程)关注的是系统如何持续、动态、预算化地构造 LLM 的输入。它包含四个核心动作:
选(Select):哪些信息值得进窗口
排(Arrange):进来以后按什么顺序摆放
压(Compress):放不下时保留什么、牺牲什么
拼(Assemble):最后如何组装成 messagesRAG 解决的是"选"的子问题——从外部知识库中选择与当前查询最相关的信息片段。但 Context Engineering 的范围远不止于此:
| 能力 | RAG | Context Engineering |
|---|---|---|
| 外部知识检索 | 核心职责 | 包含 |
| 历史对话管理 | 不涉及 | 包含 |
| 工具输出处理 | 不涉及 | 包含 |
| 上下文预算分配 | 不涉及 | 核心职责 |
| 信息压缩与摘要 | 不涉及 | 包含 |
| 动态 prompt 组装 | 不涉及 | 包含 |
| Few-shot 示例选择 | 偶尔涉及 | 包含 |
| 注意力位置优化 | 不涉及 | 包含 |
真实 Agent 的输入从来不是一段 Prompt,而是一个上下文包:
system prompt
+ 用户当前问题
+ 历史对话(压缩后)
+ 检索结果(RAG)
+ 工具输出(截断后)
+ few-shot 示例
+ 运行时规则这些信息有三个共同特点:都想进入上下文窗口、彼此竞争注意力、组织不好就会出错或成本暴涨。
压缩是实时的 RAG
上下文压缩和 RAG 在本质上解决同一个问题:从大量信息中选出当前最需要的子集。
RAG 的做法是预先索引、按需检索:把文档离线分块、向量化、存储,查询时检索 top-k。
上下文压缩的做法是实时筛选、动态保留:对话进行中,历史消息不断累积,系统实时决定保留什么、摘要什么、丢弃什么。
def progressive_compress(history, max_tokens=4000):
turns = parse_turns(history)
recent = turns[-3:] # 近处:保留原文
middle = turns[-8:-3] # 中段:压成摘要
old = turns[:-8] # 更远:抽成关键事实
compressed = []
if old:
compressed.append(extract_key_facts(old))
if middle:
compressed.append(summarize(middle))
compressed.extend(recent)
return compressed这比"只留最近 N 轮"强得多,因为它承认了一个事实:旧历史里可能还有长期有效的信息,但不值得保留全部原文。
上下文预算分配
Context Engineering 最核心的工程实践是预算化管理:
class ContextBudget:
def __init__(self, max_tokens=8000, reserved_for_output=2000):
self.available = max_tokens - reserved_for_output
def allocate(self):
budget = self.available
return {
"system_prompt": min(1000, budget),
"current_query": min(500, budget),
"retrieved_docs": int(budget * 0.5), # RAG 结果
"tool_results": int(budget * 0.4),
"history": budget, # 最后分配剩余
}关键不是具体比例,而是"先预留输出空间,再给输入分配预算"。很多系统上下文溢出,不是因为输入绝对太大,而是因为没有提前给生成预留空间。
关系总结
Context Engineering
├── 信息选择
│ ├── RAG(外部知识检索) ← RAG 在这里
│ ├── 记忆检索(历史对话)
│ └── 工具结果筛选
├── 信息排序(注意力位置优化)
├── 信息压缩
│ ├── 历史对话摘要
│ ├── 工具输出截断
│ └── 检索结果精简
├── 信息组装(prompt 拼接)
└── 预算管理(token 分配)所以:RAG 做得再好,也只是解决了上下文工程的一个子问题。Agent 系统的输出质量上界,由整个上下文供应系统的质量决定,而不仅仅由检索质量决定。
9.4 实践路线:从基础 RAG → GraphRAG → 混合检索
阶段一:基础 RAG
最小可行的 RAG 系统只需要四个组件:
DocumentStore 分块 + 向量化 + 存储
VectorSearch 余弦相似度检索 top-k
ContextInjector 检索结果格式化注入 system prompt
Agent 调用模型生成回答核心代码骨架:
class DocumentStore {
private chunks: Chunk[] = []
addDocument(content: string, source: string,
chunkSize = 200, overlap = 40): void {
const newChunks = this.splitIntoChunks(content, source,
chunkSize, overlap)
this.chunks.push(...newChunks)
this.rebuildVocabularyAndVectorize()
}
search(query: string, topK = 3): Chunk[] {
const queryVec = vectorize(query)
return this.chunks
.map(chunk => ({
chunk,
score: cosineSimilarity(queryVec, chunk.vector)
}))
.filter(({ score }) => score > 0)
.sort((a, b) => b.score - a.score)
.slice(0, topK)
.map(({ chunk }) => chunk)
}
formatContext(chunks: Chunk[]): string {
return chunks.map((chunk, i) =>
`[文档片段 ${i + 1} | 来源: ${chunk.source}]\n${chunk.content}`
).join('\n\n')
}
}设计要点:
- 词汇表全局共享,保证所有分块向量维度一致
- L2 归一化后余弦相似度退化为点积,计算更快
- 来源标注帮助模型区分参考资料和自身知识
阶段二:GraphRAG
在向量 RAG 基础上,增加知识图谱层处理实体关系和多跳推理。
核心数据结构:
interface Entity {
id: string
name: string
type: string
properties: Record<string, string>
}
interface Relation {
from: string // 起点实体 id
to: string // 终点实体 id
type: string // 关系类型
}BFS 图遍历检索:
class KnowledgeGraph {
getNeighbors(entityId: string, maxHops = 2) {
const visited = new Set([entityId])
const queue: [string, number][] = [[entityId, 0]]
const entities: Entity[] = []
const relations: Relation[] = []
while (queue.length > 0) {
const [currentId, hop] = queue.shift()!
if (hop >= maxHops) continue
for (const rel of this.relations) {
let neighborId: string | null = null
if (rel.from === currentId) neighborId = rel.to
else if (rel.to === currentId) neighborId = rel.from
if (!neighborId || visited.has(neighborId)) continue
const neighbor = this.entities.get(neighborId)
if (!neighbor) continue
visited.add(neighborId)
entities.push(neighbor)
relations.push(rel)
queue.push([neighborId, hop + 1])
}
}
return { entities, relations }
}
}生产环境图数据库选型:
- Neo4j:最成熟,Cypher 查询语言,社区资源最丰富
- ArangoDB:多模型,支持图 + 文档
- Amazon Neptune:云托管,适合 AWS 生态
阶段三:混合检索系统
将向量检索、关键词检索、图谱检索融合为统一的检索层。
统一结果接口:
interface RetrievalResult {
id: string
content: string
source: string
score: number
}RRF 融合实现:
class HybridRetriever {
rrfFusion(resultSets: RetrievalResult[][], k = 60) {
const scoreMap = new Map<string, {
result: RetrievalResult
rrfScore: number
}>()
for (const results of resultSets) {
results.forEach((result, index) => {
const rank = index + 1
const contribution = 1 / (k + rank)
const existing = scoreMap.get(result.id)
if (existing) {
existing.rrfScore += contribution
} else {
scoreMap.set(result.id, {
result,
rrfScore: contribution
})
}
})
}
return Array.from(scoreMap.values())
.sort((a, b) => b.rrfScore - a.rrfScore)
.map(entry => ({
...entry.result,
score: entry.rrfScore
}))
}
search(query: string, topK = 3) {
const kwResults = this.keywordRetriever.search(query, 10)
const vecResults = this.vectorRetriever.search(query, 10)
return this.rrfFusion([kwResults, vecResults]).slice(0, topK)
}
}关键设计决策:
rrfFusion接受列表的列表,不限于两路,加入图谱检索只需传第三路- 融合算法只关心排名,不关心原始分数绝对值,量纲不同不影响融合
- Agent 不关心"怎么检索",只关心"给我相关内容",检索层替换对 Agent 透明
三个阶段的能力矩阵
| 能力 | 基础 RAG | + GraphRAG | + 混合检索 |
|---|---|---|---|
| 语义相似搜索 | 有 | 有 | 有 |
| 多跳关系推理 | 无 | 有 | 有 |
| 精确关键词匹配 | 无 | 无 | 有 |
| 实体别名处理 | 无 | 有 | 有 |
| 多文档冲突处理 | 需手动 | 图层可辅助 | 元数据融合 |
完整的生产级 RAG 清单
把 9.1 到 9.3 的所有痛点串成一个检查清单:
□ 分块策略:是否按语义边界切分,chunk 大小是否经过验证
□ Embedding 模型:是否匹配语料语言和领域
□ 混合检索:是否同时支持关键词和向量检索
□ Reranking:初检 top-k 是否经过 cross-encoder 重排
□ Query Rewriting:是否对模糊查询做改写或分解
□ Prompt 约束:是否锁定信息源、禁止编造
□ 元数据管理:是否支持版本、状态、来源标注
□ 冲突处理:是否有显式的优先级规则
□ 评估体系:是否持续监控 Recall、Precision、MRR、Faithfulness
□ 上下文预算:RAG 结果是否纳入整体 token 预算管理不需要一次全部实现。根据实际问题逐步优化——先定位到底是哪一层出了问题,再针对性地加对应的组件。