第 22 章 Agent Memory 系统
Agent 的记忆系统本质上是在解决一个问题:如何让一个无状态的概率模型在多次交互中积累经验、保持一致性、并持续自我改进——这比表面上的"把对话存起来"要复杂几个数量级。
22.1 Memory in the Age of AI Agents
"Memory in the Age of AI Agents: A Survey" 是目前对 Agent 记忆研究最系统的综述,提出了通过形式 (Forms)、功能 (Functions)、动态 (Dynamics) 三个维度审视记忆系统的统一框架。
记忆的形式化定义
Agent 记忆被形式化为随时间演变的记忆状态
| 阶段 | 算子 | 作用 |
|---|---|---|
| Formation | 将交互制品 | |
| Evolution | 整合到现有记忆库:冗余消除、冲突解决、低效信息丢弃、结构重组 | |
| Retrieval | 构建上下文相关查询,返回相关记忆 |
关键洞察:短期记忆和长期记忆并非独立模块,而是 Formation / Evolution / Retrieval 操作在不同时序尺度上的自然涌现。
与相邻概念的边界
Agent Memory vs RAG:经典 RAG 增强对静态知识源的访问,不维护内部演化记忆。Agent Memory 在持续交互中不断整合自身行动和环境反馈到持久记忆库。即使是最接近的 Agentic RAG,操作的也是外部任务特定数据库,而 Agent Memory 维护内部的、持久的、自演化的记忆库。
Agent Memory vs Context Engineering:上下文工程将上下文窗口视为受限计算资源,优化信息负载以最大化推理效率。Agent Memory 具有更广泛的认知范围——包括事实知识的持久存储、经验痕迹的积累与演化、以及记忆内化到模型参数中。
记忆形式的三层分类
graph TD
subgraph "Token-level Memory(显式记忆)"
F1D["Flat 1D<br>序列/片段袋"] --> |"无拓扑结构"| A["检索质量决定效果"]
F2D["Planar 2D<br>图/树/表格"] --> |"单层拓扑"| B["结构化查找 + 关系遍历"]
F3D["Hierarchical 3D<br>金字塔/多层结构"] --> |"多层级"| C["不同抽象程度的表示"]
end
subgraph "Parametric Memory(参数记忆)"
PI["内部参数<br>权重/偏置"] --> D["直接调整基础模型"]
PE["外部参数<br>LoRA/适配器/辅助 LLM"] --> E["模块化添加/替换"]
end
subgraph "Latent Memory(潜在记忆)"
LG["Generate<br>独立模块生成内部表示"]
LR["Reuse<br>直接重用 KV 缓存"]
LT["Transform<br>压缩/重构 KV 缓存"]
endToken-level Memory 按复杂度递增分为三级:
- Flat (1D):单元间无显式拓扑,如对话历史片段、用户偏好序列。优点是简单可扩展,缺点是连贯性完全依赖检索质量。
- Planar (2D):引入显式拓扑(图、树、表格),实现从"存储"到"组织"的飞跃。适用于知识图谱、动态对话树等,但所有记忆在单一层级,面对复杂场景性能受限。
- Hierarchical (3D):多层级组织——原始观察、事件摘要、高层主题模式交织。编码最全面的上下文知识,但结构复杂度和检索效率是核心挑战。
Parametric Memory 将信息编码到模型参数中:
- 内部参数记忆:通过预训练 / 中期训练 / 后期训练在权重中嵌入知识。结构简单零推理开销,但更新需要重新训练且易遗忘。
- 外部参数记忆:通过 LoRA、适配器、辅助 LLM 等模块化添加。典型方法如 MLP-Memory、K-Adapter、WISE、ELDER 等。平衡了适应性与稳定性,避免灾难性遗忘。
Latent Memory 利用模型内部表示(KV 缓存、隐藏状态、潜在嵌入):
- Generate:由专用模块生成高信息密度表示(Gist、AutoCompressor、Titans 等),无需重复处理完整上下文,但可能引入信息损失或状态漂移。
- Reuse:直接重用前向传递的 KV 缓存(Memorizing Transformers、LONGMEM 等),保留完整激活,但缓存随上下文长度线性增长。
- Transform:压缩或重构 KV 缓存(Scissorhands、SnapKV、PyramidKV 等),生成更紧凑的记忆表示,代价是潜在的信息丢失。
记忆的三大功能
| 功能 | 核心问题 | 认知对应 |
|---|---|---|
| Factual Memory | Agent 知道什么? | 声明性记忆(episodic + semantic) |
| Experiential Memory | Agent 如何改进? | 程序性记忆(技能学习、策略优化) |
| Working Memory | Agent 现在在想什么? | 工作记忆(容量受限的暂存器) |
Factual Memory 确保交互的连贯性、一致性和适应性。其核心属性:
- 连贯性 (Coherence):召回并整合相关交互历史,保持主题连续性。
- 一致性 (Consistency):维护用户特定事实和自身承诺的持久内部状态,避免矛盾。
- 适应性 (Adaptability):根据用户画像和历史反馈个性化行为。
这三类记忆形成认知循环:编码(整合到长期记忆)→ 处理(工作记忆中即时推理)→ 检索(从事实和经验记忆获取上下文),彼此并非孤立。
22.2 Agentic Plan Caching
"Agentic Plan Caching: Test-Time Memory for Fast and Cost-Efficient LLM Agents"(NeurIPS 2025)针对 LLM Agent 应用中重复推理开销巨大的问题,提出了一种缓存可复用规划模板而非输入-输出对的方案。
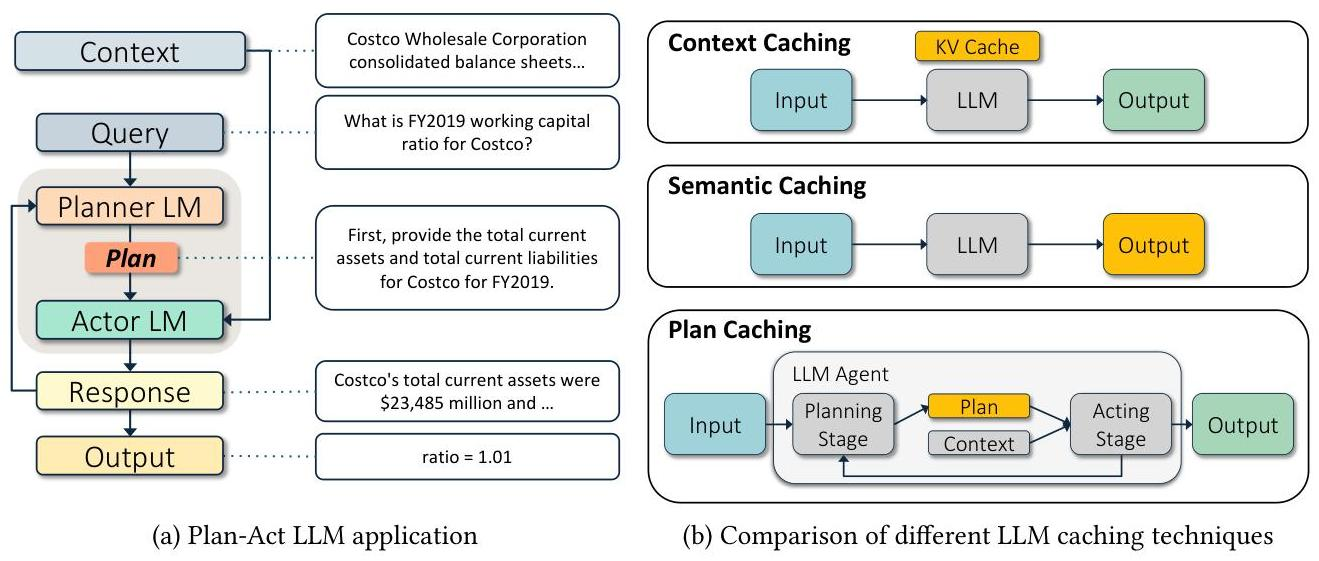
现有缓存方案的局限
| 缓存方案 | 原理 | 在 data-dependent 任务中的问题 |
|---|---|---|
| Context caching | 缓存 KV 缓存等模型内部状态 | 要求近乎精确的文本匹配 |
| Semantic caching | 缓存语义相似的输入-输出对 | 高假阳性——相同查询在不同外部上下文下需要不同行动 |
| Full-history caching | 提供完整执行日志作为 in-context 示例 | 信息过载导致准确率和成本双劣(FinanceBench 72% vs Plan Caching 85.5%) |
语义缓存的根本问题在于无法区分表面文本相似性和任务级等价性。在数据依赖型场景中,两个看起来相同的查询可能因外部上下文不同而需要完全不同的行动序列。
系统架构
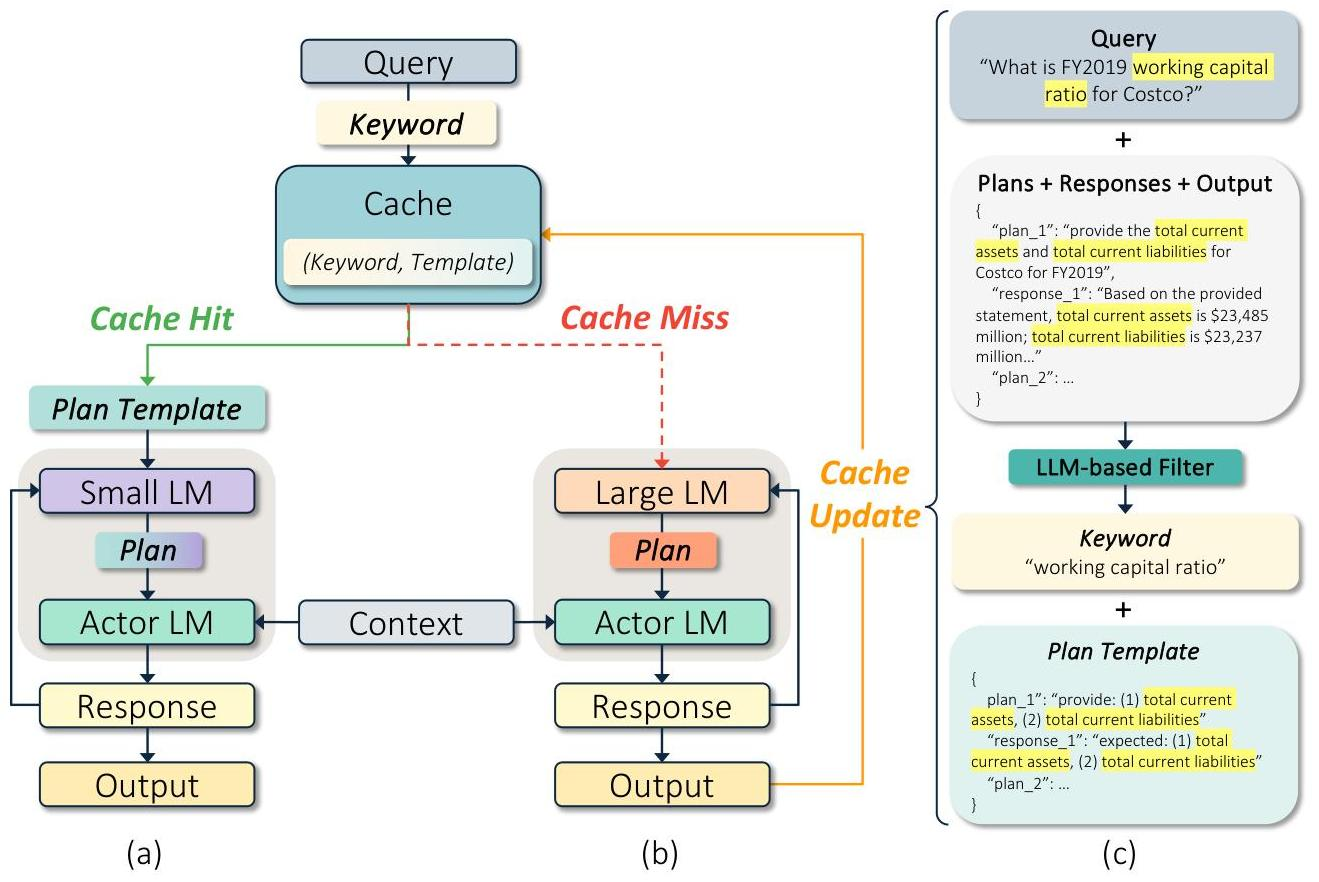
核心流程分四步:
- 关键词提取:轻量级模型从新请求中提取任务关键词。
- 缓存查找:以关键词在缓存中检索匹配的规划模板。
- 命中路径:小型低成本 planner 将模板适配到当前上下文。
- 未命中路径:大型高成本模型生成新规划,执行流程被提炼为新模板存入缓存。
关键设计选择:缓存的是抽象的执行计划模板,而非具体的 QA 对。模板保留了任务的逻辑骨架(步骤序列、工具调用模式、条件分支),但剥离了数据相关的具体细节。适配阶段由小模型完成,将模板中的占位逻辑绑定到当前任务的具体数据上下文。
实验结论
在 FinanceBench 和 TabMWP 两个 data-intensive reasoning 任务上:
- 维持 96.67% 最优准确率,成本平均降低 46.62%。
- 关键词提取和模板生成的额外开销仅占总成本 1.04%。
- 缓存命中时性能一致稳定,而语义缓存和全历史缓存在"成功"命中时反而出现准确率下降。
局限性:仅验证了 Plan-Act 架构,在多 agent 系统中的适用性未知;高度动态任务中缓存优势可能减弱;缺乏延迟维度的分析。
22.3 Memory 系统的设计维度
从工程视角出发,Memory 系统的设计可以沿四个正交维度展开:集成方式、索引策略、更新机制、遗忘策略。
集成:结构化 vs 非结构化
结构化集成将记忆组织为有明确 schema 的数据结构:
# 结构化记忆条目示例
class MemoryEntry:
task_group: str # 任务分组标识
scope: str # 适用范围
applies_to: str # cwd / workflow 边界
keywords: list[str] # 可检索关键词
preference_signals: list # 用户偏好证据
reusable_knowledge: list # 可复用知识
failure_shields: list # 失败防护规则
rollout_refs: list[str] # 来源 rollout 引用优势在于支持精确检索、冲突检测和增量更新。代价是 schema 设计需要领域知识,且灵活性受限。
非结构化集成以自由文本存储记忆,依赖 embedding 检索。简单灵活但难以做冲突检测和去重。
工业实践中的折衷是半结构化方案:用 markdown 作为载体,通过 frontmatter 元数据(task、task_group、task_outcome、cwd、keywords)提供结构化索引,正文保留自由文本的表达力。这种方案在 Codex 的记忆系统中得到了验证。
索引:信号增强、图、时间线
索引策略决定了"给定查询,能多快、多准地找到相关记忆"。
信号增强索引:在记忆条目上叠加额外的检索信号。典型做法包括:
- 关键词标注:为每条记忆提取可搜索的 handle(工具名、错误名、repo 概念)。
- 使用频率跟踪:记录每条记忆被引用的次数和最近引用时间,用于排序和淘汰。
- CWD 绑定:将记忆绑定到特定工作目录,防止跨项目误匹配。
图索引:将记忆组织为知识图谱,支持多跳关系推理。适用于需要关联推理的场景(如"这个 bug 修复与哪些配置变更相关"),但构建和维护成本高。
时间线索引:按时间戳排序记忆,最新的优先级最高。简单但对理解"事态演变"至关重要——同一个 bug 的修复历史按时间排列比乱序更有价值。
更新:参数化 vs 非参数化
参数化更新通过训练将记忆编码到模型参数中(fine-tuning、LoRA、adapter)。优势是推理时零额外开销,劣势是更新周期长、存在灾难性遗忘风险、难以精确删除特定记忆。
非参数化更新将记忆存储在外部存储中,通过检索注入上下文。优势是实时更新、可精确删除,劣势是增加检索延迟和上下文窗口占用。
实际系统通常采用两阶段策略:日常运行使用非参数化更新保持灵活性,定期将高频使用的稳定记忆通过参数化更新内化到模型中。
遗忘:被动 vs 主动
被动遗忘:记忆自然衰减——超过时间窗口的未使用记忆被自动淘汰。实现简单但可能丢弃偶尔有用的低频记忆。
# 基于使用频率和新鲜度的淘汰策略
def should_retain(memory, max_unused_days: int) -> bool:
if memory.last_usage:
days_since_use = (now() - memory.last_usage).days
return days_since_use <= max_unused_days
# 从未被使用过的记忆,按生成时间判断
days_since_generated = (now() - memory.generated_at).days
return days_since_generated <= max_unused_days主动遗忘:在记忆整合阶段显式决定删除哪些记忆。需要"遗忘代理"评估每条记忆的当前价值——被反驳的事实、过时的工作流、已解决的 bug 应主动清除。
主动遗忘的一个精妙变体是选择性遗忘 (selective forgetting):当新记忆与旧记忆冲突时,不是简单替换,而是保留冲突的历史轨迹("之前认为 X,现在发现 Y"),让未来的 agent 理解认知演变。
22.4 EverMemOS:自组织记忆操作系统
EverMemOS("A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning")提出了一种将记忆管理抽象为操作系统层的架构,针对需要长期结构化推理的 Agent 任务。
核心设计理念
EverMemOS 的核心洞察是:传统的记忆系统将记忆视为被动的数据存储,而实际上记忆应该是一个主动的、自组织的系统——它不仅存储信息,还能自主决定何时整理、何时遗忘、如何建立关联。
graph TD
A["Agent 交互层"] --> B["EverMemOS 记忆层"]
B --> C["自组织索引<br>动态建立记忆间关联"]
B --> D["分层压缩<br>原始→摘要→模式"]
B --> E["主动遗忘<br>淘汰过时/低价值记忆"]
B --> F["上下文路由<br>按任务类型选择检索策略"]
C --> G["持久化存储"]
D --> G
E --> G将记忆管理类比为操作系统的资源管理:
| OS 概念 | 记忆对应 |
|---|---|
| 文件系统 | 记忆的持久化存储与组织 |
| 内存管理(缓存/换页) | 工作记忆的加载与淘汰 |
| 进程调度 | 多个记忆操作的优先级与并发控制 |
| 垃圾回收 | 过时/冗余记忆的主动清理 |
与传统方案的区别
传统记忆系统通常是读写分离的:写入时追加,读取时检索,两个操作彼此独立。EverMemOS 引入了自组织机制——记忆在被写入后会经历自主的重组过程:相关记忆被自动聚合,冗余信息被压缩,高层模式被抽取。这使得后续检索不再依赖查询质量——即使查询不够精确,自组织后的记忆结构本身就提供了导航能力。
22.5 AMemGym:Agent Memory Benchmark
AMemGym("Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations")解决的是一个元问题:如何系统地评估一个 Agent 的记忆能力?
评估维度
传统的记忆评估通常只测试"能不能记住",AMemGym 将评估分解为多个维度:
graph LR
A["AMemGym Benchmark"] --> B["记忆准确性<br>能否正确回忆存储的事实"]
A --> C["时序一致性<br>能否维护跨对话的一致性"]
A --> D["选择性遗忘<br>能否正确丢弃过时信息"]
A --> E["记忆利用<br>能否在正确时机调用记忆"]
A --> F["长对话鲁棒性<br>长时间交互后是否退化"]- 记忆准确性 (Accuracy):给定 N 轮对话后,Agent 能否正确回忆第 K 轮中用户提到的偏好?
- 时序一致性 (Temporal Consistency):当用户偏好发生变化时("我之前喜欢 Python,现在转到 Rust 了"),Agent 能否正确跟踪最新状态?
- 选择性遗忘 (Selective Forgetting):被用户明确否定的信息("那个方案不行,忘了它"),Agent 是否还会错误地使用?
- 记忆利用 (Memory Utilization):即使记忆系统中存储了相关信息,Agent 是否能在正确的时机检索并应用它?
- 长对话鲁棒性 (Long-horizon Robustness):经过数百轮交互后,记忆系统的准确性是否显著退化?
基准设计的挑战
设计 memory benchmark 面临几个独特挑战:
- 交互性:不同于静态 QA benchmark,memory benchmark 需要模拟多轮动态交互,用户行为影响后续记忆状态。
- 开放性:正确答案不唯一——"记住用户偏好"的方式可以是精确复述、也可以是语义等价的概括,评估标准需要语义级的判断。
- 长尾效应:真正有价值的记忆测试发生在数百轮对话之后,而非前几轮,构建和运行这样的测试成本很高。
22.6 工程落点
理论框架和论文方法最终要落到可运行的代码中。本节从三个层面展开:工业级记忆管道的完整实现、对话状态的持久化、以及最小化记忆方案。
持久化记忆模块的实现
Codex 的记忆系统是目前公开可见的最完整的工业级 Agent Memory 实现。其架构分为两个 phase,通过 state DB 协调:
flowchart TD
subgraph "Phase 1: Rollout Extraction"
S1["会话启动"] --> S2["从 State DB 认领<br>符合条件的 rollout jobs"]
S2 --> S3["并行提取(concurrency=8)"]
S3 --> S4["LLM 生成<br>raw_memory + rollout_summary"]
S4 --> S5["Secret 脱敏"]
S5 --> S6["写回 State DB"]
end
subgraph "Phase 2: Global Consolidation"
S6 --> S7["认领全局 consolidation 锁"]
S7 --> S8["从 DB 加载 stage-1 outputs"]
S8 --> S9["同步文件系统<br>raw_memories.md + rollout_summaries/"]
S9 --> S10["Spawn consolidation subagent"]
S10 --> S11["生成 MEMORY.md +<br>memory_summary.md + skills/"]
endPhase 1(Rollout Extraction) 的核心设计:
- 准入条件:只处理来自交互式会话的、在配置年龄窗口内的、空闲足够久的 rollout。通过 lease 机制防止多个 worker 重复处理同一个 rollout。
- 提取模型:默认使用轻量级模型(推理努力度为 Low),通过 structured output schema 约束输出格式。
- 截断策略:大 rollout 按模型有效上下文窗口的 70% 截断,保留头尾上下文。
- 安全措施:提取结果经过
redact_secrets处理,密钥 / token / 密码被替换为[REDACTED_SECRET]。 - 失败处理:失败的 job 设置指数退避重试(默认 3600 秒),不会热循环。
Phase 1 的输出是结构化的 JSON,包含三个字段:
{
"raw_memory": "详细的 markdown 记忆,包含任务分组、偏好信号、可复用知识、失败防护",
"rollout_summary": "紧凑的 rollout 摘要,未来 agent 通常无需重新打开原始 rollout",
"rollout_slug": "文件系统安全的标识符,如 fix-auth-token-refresh"
}Phase 1 的提取 prompt 要求模型执行严格的信号门控——在输出之前必须回答:"未来 agent 是否会因为这条记忆而做得更好?" 如果答案是否定的,返回空字段。这防止了低质量记忆的积累。
对于记忆内容的提取,prompt 要求按优先级阅读 rollout:
- 用户消息(最强信号):偏好、约束、不满、纠正。
- 工具输出 / 验证证据:repo 事实、失败、命令、实际结果。
- Assistant 消息(最弱信号):仅用于重构尝试过程,不作为用户偏好的主要来源。
Phase 2(Global Consolidation) 的核心设计:
- 全局锁:同一时刻只有一个 consolidation 运行,通过 DB 层的 job claim 机制实现,带 heartbeat 保活和 lease 续约。
- 输入选择与 diff:按使用频率排序选择 stage-1 outputs,然后与上一次成功的 Phase 2 选择做 diff,产生
added、retained、removed三种标签。
Diff since last consolidation:
- selected inputs this run: 15
- newly added since the last successful Phase 2 run: 3
- retained from the last successful Phase 2 run: 10
- removed from the last successful Phase 2 run: 2- Consolidation Subagent:以受限权限运行——禁止网络访问、禁止递归委托、仅允许在
codex_home下写入。使用更强的模型(默认推理努力度 Medium),将分散的 raw memories 整合为三层渐进式记忆结构。 - Watermark 机制:Phase 2 维护 completion watermark,记录已处理到的最新 stage-1 时间戳。后续运行通过比对 watermark 判断是否有新数据(dirty vs clean),避免无意义的重复整合。
- 遗忘机制:被移除的 thread 记忆不是立即删除,而是在 consolidation 期间仍可见(保留证据),由 consolidation agent 评估后决定是否保留或清理相关条目。
Phase 2 输出的文件系统布局实现了渐进式披露 (progressive disclosure):
memories/
├── memory_summary.md # 注入 system prompt,导航级摘要
├── MEMORY.md # 可 grep 的知识手册,聚合洞察 + 指针
├── raw_memories.md # Phase 1 合并输出(Phase 2 输入)
├── rollout_summaries/ # 每个 rollout 的详细摘要
│ ├── 2026-03-01T10-30-00-aB3x-fix-auth-bug.md
│ └── ...
└── skills/ # 可复用的过程性知识
└── <skill-name>/
├── SKILL.md # 入口指令
├── scripts/ # 辅助脚本
├── templates/ # 模板
└── examples/ # 示例读取路径 (Read Path) 的设计同样精妙:
当新会话启动时,memory_summary.md 的内容被截断到 5000 token 后注入 system prompt。Agent 在处理用户请求时执行 Quick Memory Pass:
- 扫描
memory_summary提取任务相关关键词。 - 用关键词搜索
MEMORY.md。 - 仅当
MEMORY.md直接指向特定 rollout summary 或 skill 时,才打开 1-2 个最相关的文件。 - 无命中则停止查找。
总预算控制在 4-6 次搜索以内,避免在记忆查找上花费过多时间。读取路径还包含记忆引用 (memory citation) 机制——Agent 在回答中使用了记忆信息时,必须在回复末尾附加结构化的引用块,包含文件路径、行号范围和引用说明,形成完整的溯源链。
<oai-mem-citation>
<citation_entries>
MEMORY.md:234-236|note=[auth token refresh procedure]
rollout_summaries/2026-03-01T10-30-00-fix-auth-bug.md:10-12|note=[error pattern]
</citation_entries>
<rollout_ids>
019c6e27-e55b-73d1-87d8-4e01f1f75043
</rollout_ids>
</oai-mem-citation>使用量追踪 (Usage Tracking) 支撑了记忆淘汰决策:
系统通过 shell 命令拦截追踪 Agent 对记忆文件的实际读取行为。每次 Agent 通过 shell 读取记忆路径时,系统根据路径模式匹配分类(memory_md / memory_summary / raw_memories / rollout_summaries / skills),并发出 OpenTelemetry 指标。这些使用数据回流到 Phase 2 的输入选择——使用频率高的记忆在 consolidation 中获得更高优先级。
LangGraph Checkpointer 保存对话状态
LangGraph 的 Checkpointer 机制提供了一种在图执行的每个 super-step 自动持久化状态的方案。其核心接口:
from langgraph.checkpoint.memory import MemorySaver
from langgraph.checkpoint.sqlite import SqliteSaver
# 最简内存 checkpointer
checkpointer = MemorySaver()
# 持久化到 SQLite
checkpointer = SqliteSaver.from_conn_string("checkpoints.db")
# 构建图时注入
graph = workflow.compile(checkpointer=checkpointer)
# 通过 thread_id 恢复对话
config = {"configurable": {"thread_id": "user-123-session-456"}}
result = graph.invoke({"messages": [new_message]}, config)Checkpointer 在每个 super-step 完成时序列化整个 graph state(包括 messages、中间状态、pending sends 等),以 (thread_id, checkpoint_id) 为键存储。恢复时只需提供同一个 thread_id,graph 自动从最新 checkpoint 加载状态继续执行。
这解决了 Agent 记忆的一个子问题——会话级状态持久化。但 checkpointer 不负责跨会话的知识积累和整合,它更接近于"存档 / 读档"而非"学习"。
# 获取对话历史
history = graph.get_state_history(config)
for state in history:
print(f"Step: {state.metadata['step']}")
print(f"Messages: {len(state.values['messages'])}")
print(f"Timestamp: {state.created_at}")可选的后端包括内存(开发调试)、SQLite(单机部署)、PostgreSQL(生产环境),以及自定义实现(实现 BaseCheckpointSaver 接口)。
Transcript Archive 作为最简记忆
当不需要复杂的记忆管道时,最简方案是直接将对话 transcript 作为记忆存档:
import json
from datetime import datetime
from pathlib import Path
class TranscriptArchive:
"""最简记忆:原始对话存档 + 按时间索引"""
def __init__(self, archive_dir: str):
self.archive_dir = Path(archive_dir)
self.archive_dir.mkdir(parents=True, exist_ok=True)
def save(self, session_id: str, messages: list[dict]) -> Path:
record = {
"session_id": session_id,
"timestamp": datetime.utcnow().isoformat(),
"message_count": len(messages),
"messages": messages,
}
path = self.archive_dir / f"{session_id}.jsonl"
with open(path, "a") as f:
f.write(json.dumps(record, ensure_ascii=False) + "\n")
return path
def load_recent(self, session_id: str, n: int = 10) -> list[dict]:
path = self.archive_dir / f"{session_id}.jsonl"
if not path.exists():
return []
lines = path.read_text().strip().split("\n")
records = [json.loads(line) for line in lines[-n:]]
return records
def search(self, keyword: str) -> list[dict]:
results = []
for path in self.archive_dir.glob("*.jsonl"):
for line in path.read_text().strip().split("\n"):
record = json.loads(line)
for msg in record["messages"]:
if keyword.lower() in msg.get("content", "").lower():
results.append(record)
break
return results这种方案的价值在于:
- 零抽象开销:不需要 embedding、不需要 LLM 提取、不需要 consolidation。
- 完整保真:原始对话一字不改地保留,不会因摘要而丢失上下文。
- 可审计:任何决策都可以追溯到原始对话记录。
代价是不可扩展——当 transcript 积累到数千条时,线性搜索和全量注入上下文都不可行。但对于个人工具、小型项目、或作为更复杂记忆系统的底层存储层,它是一个完全合理的起点。
从 Transcript Archive 到 Codex 级别的记忆管道,中间的演进路径是清晰的:
graph LR
A["Transcript Archive<br>原始对话存档"] --> B["+ Summarization<br>LLM 摘要提取"]
B --> C["+ Structured Index<br>元数据 + 关键词索引"]
C --> D["+ Consolidation<br>跨会话知识整合"]
D --> E["+ Progressive Disclosure<br>渐进式披露 +<br>Usage Tracking"]每一步都在解决上一步的可扩展性瓶颈,但也引入了额外的复杂度和运维成本。选择哪一层停下来,取决于你的 Agent 需要跨多少个会话积累多少知识。