交互式基准测试(Interactive Benchmarks)
作者:Baoqing Yue, Zihan Zhu, Yifan Zhang, Jichen Feng, Hufei Yang, Mengdi Wang — Princeton University, InteractiveBench
论文的核心突破在于提出了一种统一的交互式评估范式(Interactive Benchmarks),将模型评估从静态问答转变为有预算约束的多轮交互过程,通过 Interactive Proofs(逻辑/数学)和 Interactive Games(扑克/信任博弈)两大类任务,评估模型主动获取信息并进行推理的能力。
1. 引言
论文的核心论点是:现有评估范式忽视了智能的一个关键维度——主动信息获取能力。当前主流 benchmark 可分为三类,各有缺陷:
- 静态基准(如 GSM8K、MMLU):逐渐饱和、易受数据污染
- 偏好竞技场(如 ChatBot Arena):依赖主观判断,无法可靠评估推理能力
- Agent 基准(如 SWE-bench、AgentBench):依赖复杂环境搭建,泛化性受限
论文指出,在现有 benchmark 中模型只是被动接收信息,而真实世界的任务很少是完全指定的。一个智能 agent 必须能够识别自身知识的不足、确定最有信息量的缺失证据、并采取有针对性的行动来获取它。
受计算复杂性理论中 Interactive Proofs 概念的启发,论文提出了 Interactive Benchmarks,将模型放在 prover 的位置上,要求它与一个全知但预算受限的 verifier 进行结构化交互。框架分为两大类:
- Interactive Proofs(收敛型):Agent 与 Judge 交互,通过提问收窄搜索空间,目标是最小化不确定性,收敛到客观真相。实例化为 Situation Puzzle(逻辑推理)和 Math(数学推理)
- Interactive Games(发散型):Agent 与环境/其他 agent 交互,目标是最大化长期效用。实例化为 Texas Hold'em Poker(扑克)和 Trust Game(信任博弈)
核心洞察:评估模型智能不应只看"给定信息后能否回答正确",更应看"模型能否决定获取什么信息、何时获取、如何高效获取"——这才是真实世界中智能行为的本质。
2. Interactive Benchmarks 形式化框架
论文将每个 benchmark 实例建模为模型
:环境在第 轮的消息(verifier 回复或状态更新) - 当模型提交最终答案或预算耗尽时,episode 终止
Interactive Proofs 形式化
给定实例
Interactive Games 形式化
没有专门的 judge,模型与其他 agent 交互并获得任务定义的奖励
:折扣因子
这一统一的数学框架使得不同任务之间可以在相同的原则下进行比较:Interactive Proofs 关注在约束预算内的正确性最大化,Interactive Games 关注折扣累积奖励最大化。
3. Interactive Proofs: Logic(情境谜题)
论文使用 Situation Puzzle(海龟汤)作为逻辑推理的交互式评估实例。每个谜题呈现一个看似矛盾的短叙述,背后有一个隐藏的、定义明确的 ground-truth 解释。
交互协议:
- Player(被测模型)在固定预算(如 20 轮)内向 Judge 提问
- 每轮可以提出 yes/no 问题或直接提交答案,两者均消耗一轮
- 中间查询的回复限定为 {yes, no, both, irrelevant};最终答案提交仅返回 correct 或 incorrect
both表示复合/未充分指定的查询,irrelevant表示与因果链无关的查询
为何是好的逻辑推理代理:
- 要求 溯因推理(abductive reasoning):生成能解释观察到的异常的合理假设
- 测试 策略性提问(strategic inquiry):在预算约束下优化信息增益,高效二分假设空间
- 需要 上下文整合(contextual integration):将分散的二元约束综合为全局一致的因果闭合叙事

所有模型在无交互时准确率均为 0%,证明成功完全依赖于交互行为——模型必须通过与 Judge 的交互才能获得足够信息来回答问题。
论文精心构建了包含 46 个高质量、极具挑战性的实例数据集,经过标准化处理和严格筛选,确保满足两个核心原则:(1) 交互必要性——仅凭表面问题无法求解;(2) 歧义消解——ground truth 足够详细以解释表面问题。
4. Interactive Proofs: Math(数学推理)
论文指出传统的 pass@k 评估有两个显著局限:
- 计算效率低:由于每个 sample 必须生成完整解答,推理早期的错误会浪费后续全部计算量,导致 pass@k 低估了模型的潜在能力
- 缺乏过程可解释性:只衡量最终正确的概率,无法洞察模型自纠错或验证中间步骤的能力
交互式数学评估协议:Player 与持有参考推导或最终答案的 Judge 交互。每轮可以查询中间声明的有效性(如某个引理或推导方程是否正确),回复同样限定为 {yes, no, both, irrelevant}。这使得 Player 能够早期剪枝错误分支,提升单位 token 的搜索效率。
公平比较机制:为与 pass@k 进行公平对比,论文采用 token 预算匹配策略,选择使推理总预算差距最小的

各模型的交互式 token 用量差异很大(Grok 仅 279 tokens vs. Qwen3 高达 15803 tokens),匹配后的
5. Interactive Games: Texas Hold'em(扑克)
论文使用 No-Limit Texas Hold'em 作为不完全信息博弈的策略推理评估。扑克要求 agent 在不确定性下推理、管理风险、并建模对手心理(Theory of Mind)。
环境设置:
- 标准 No-Limit 规则,经过 Preflop → Flop → Turn → River → Showdown 的标准流程
- Agent 在每个决策点接收结构化观察(当前阶段、底牌、公共牌、筹码、底池赔率、近期行动历史)
- 输出合法动作之一:FOLD、CHECK、CALL、RAISE、ALL_IN
- 严格的超时和格式验证;无效输出先给一次重试机会,双重失败则自动 fold
6. Interactive Games: Trust Game(信任博弈)
论文使用重复的 Prisoner's Dilemma(囚徒困境)变体作为 Trust Game 测试平台。与 Interactive Proofs 不同,这里双方都能通过行动影响未来,模型必须对对手行为做出反应、在线更新策略、并在时间维度上最大化收益。
博弈规则:
- 每轮双方同时选择 cooperate (
) 或 defect ( ) - 选择前可观察到截至上一轮的完整行动历史
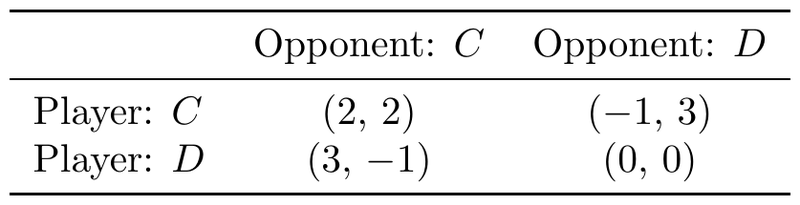
收益矩阵遵循经典囚徒困境结构:双方合作各得 2 分;双方背叛各得 0 分;单方背叛获 3 分而被背叛方得 -1 分。
随机 horizon 机制:为避免固定已知终止轮次带来的激励扭曲,每轮后博弈以概率
期望长度为
评估指标:
- 平均每轮得分
:跨所有对局汇总 - 合作率
:选择合作的总体频率 - 背叛率
:在对手上一轮合作的条件下选择背叛的频率
Trust Game 没有对所有对手都最优的单一策略,高绩效取决于模型如何回应对手行为、多快适应对手策略变化。
7. 实验结果
论文评估了六个前沿 LLM:Grok-4.1-fast、Gemini-3-flash、GPT-5-mini、Kimi-k2-thinking、DeepSeek-v3.2、Qwen3-max。
7.1 Logic 结果
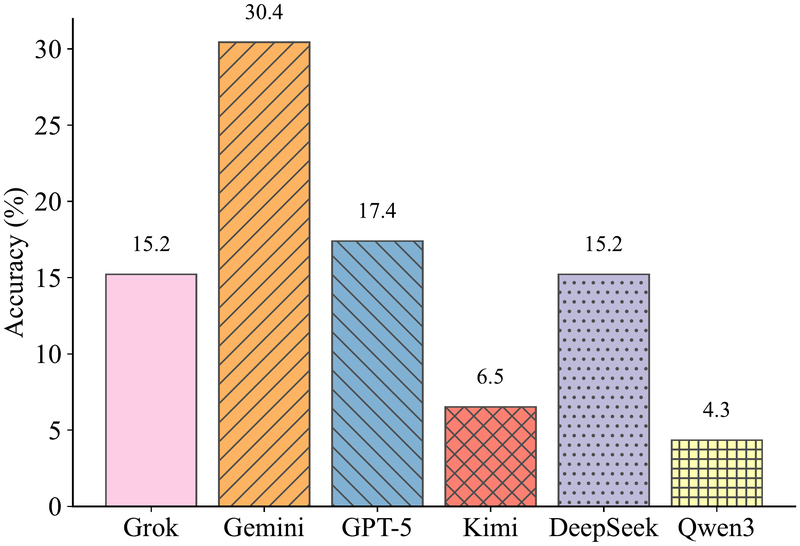
柱状图展示六个模型在 46 道情境谜题上的准确率。Gemini-3-flash 以 30.4% 的准确率领先,其次是 GPT-5-mini(17.4%)和 Grok/DeepSeek(并列 15.2%)。Qwen3-max 表现最差(4.3%)。
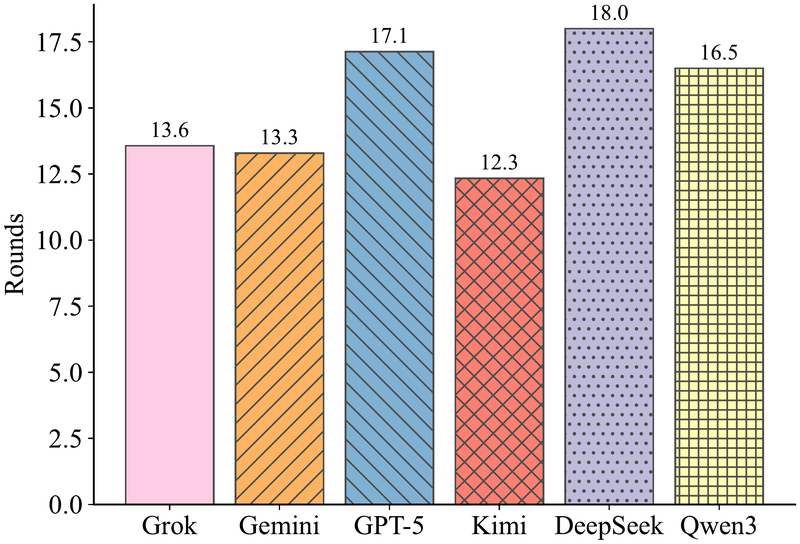
仅统计已解决的谜题,图中展示各模型的平均求解轮次。Kimi-k2-thinking 最高效(12.3 轮),Gemini 紧随其后(13.3 轮)。DeepSeek 即使在成功时也需要最多轮次(18.0 轮),表明收敛速度最慢。
准确率与效率并不完全一致:Gemini 准确率最高且效率第二;Kimi 效率最高但准确率仅 6.5%,说明它能解决的少数谜题解得很快,但泛化能力不足。
7.2 Math 结果
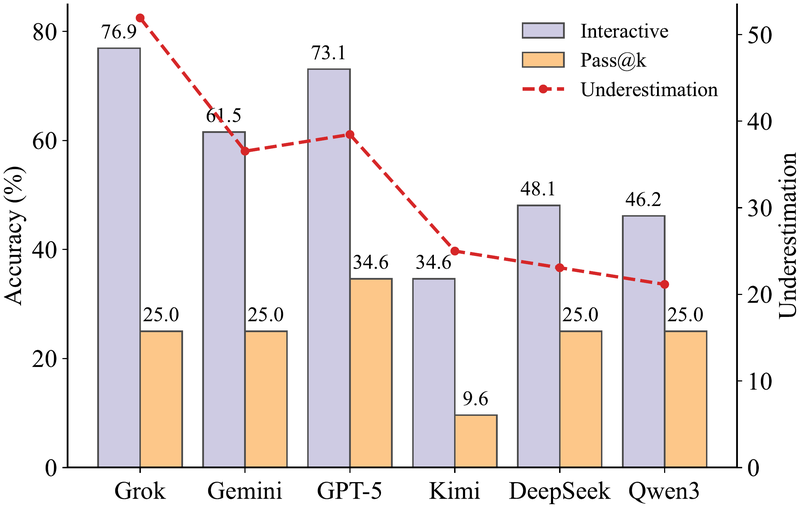
双轴柱状图对比了交互式评估与预算匹配的 pass@k 评估。蓝色柱为交互式准确率,橙色柱为 pass@k 准确率,红色虚线为低估幅度。关键发现:
- Grok-4.1-fast 交互式准确率最高(76.9%),其次是 GPT-5-mini(73.1%)、Gemini(61.5%)
- Kimi-k2-thinking 表现最弱(34.6%)
- pass@k 普遍比交互式评估低 20%-50%,证实了 pass@k 在固定预算下会系统性低估模型的实际能力
- Grok 的低估幅度最大(约 50 个百分点),说明交互式协议对该模型释放了最多的潜在能力
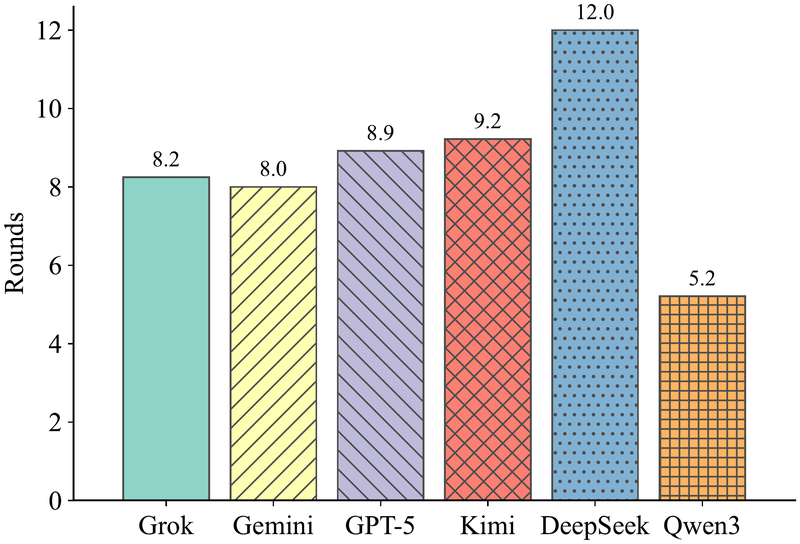
Qwen3-max 平均仅需 5.2 轮,但准确率仅 46.2%——说明它能高效解决一部分问题,但难以跨实例类型泛化。DeepSeek 再次需要最多轮次(12.0 轮),且准确率仅 48.1%。Grok、GPT-5、Gemini 在 8-9 轮左右取得了较好的准确率-效率平衡。
7.3 Poker 结果
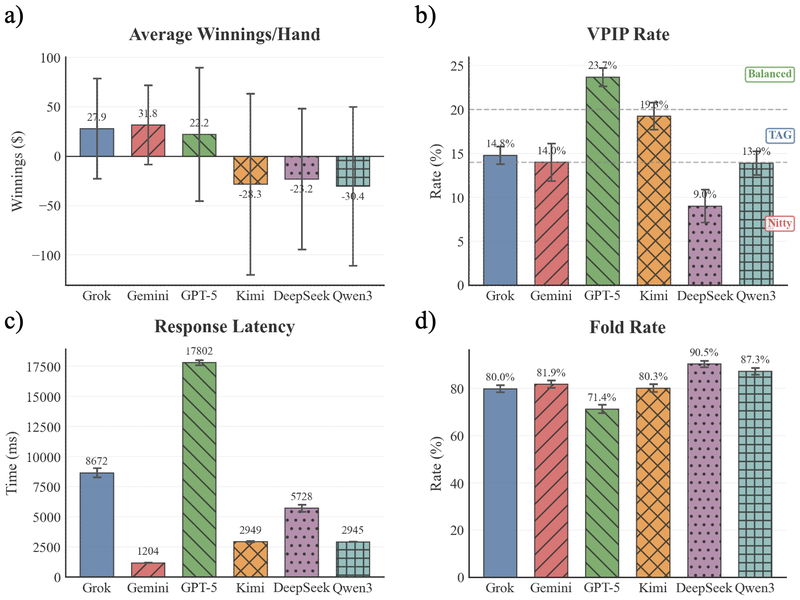
四面板图展示扑克实验结果:(a) 平均每手盈利,(b) VPIP 率(自愿入池率),(c) 响应延迟,(d) Fold 率。
- Gemini-3-flash 综合最优:平均每手盈利
,跨桌稳定性最高 - Grok(
)和 GPT-5( )也盈利,但方差更大 - GPT-5 是最激进的玩家:VPIP 最高(23.7%)、Fold 率最低(71.4%),高参与但高波动
- DeepSeek 是最保守的玩家:VPIP 最低(9.0%)、Fold 率最高(90.5%),但仍然亏损
- 响应延迟差异显著:DeepSeek 最慢(~17.8s),Grok 最快
低选择性不足以盈利,高激进性也不保证最优收益——Gemini 在利润、稳定性和执行速度之间取得了最好的平衡。
7.4 Trust Game 结果
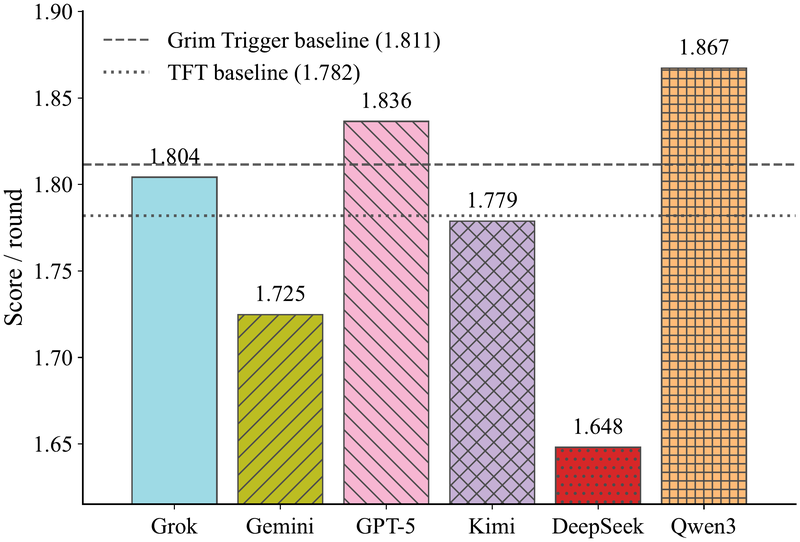
柱状图附带两条启发式 baseline 虚线(Grim Trigger: 1.811, Tit-for-Tat: 1.782)。Qwen3-max 得分最高(1.867),GPT-5-mini 紧随其后(1.836),两者是仅有的超过两个启发式 baseline 的模型。DeepSeek 得分最低(1.648),大幅低于两个 baseline。
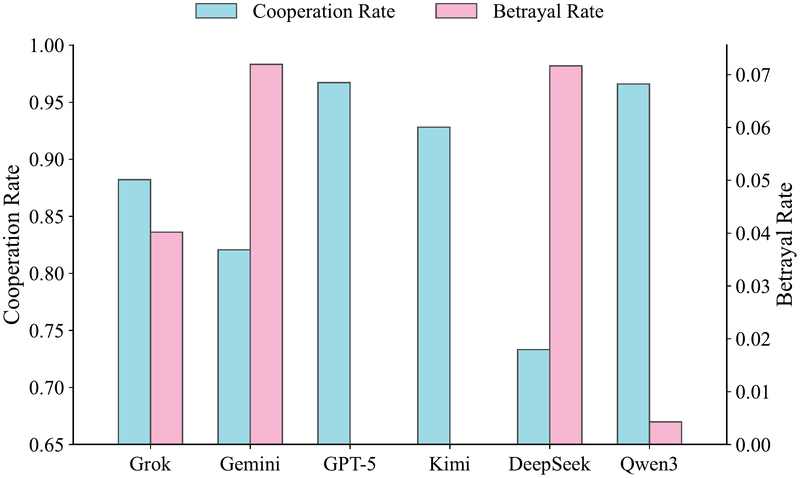
双轴柱状图,蓝色柱为合作率,粉色柱为背叛率。
- Qwen3 和 GPT-5 表现出高度合作策略:合作率约 97%,背叛率极低(2% 和 0%)——这种"近乎无条件合作"的策略在本锦标赛中获得了最高收益
- Gemini 和 DeepSeek 合作率较低(82% 和 73%),背叛率最高(约 7%),对应了较低的平均得分
- Grok 合作率 88%,背叛率约 4%,得分居中
在重复博弈中,高合作率 + 低背叛率的"善良"策略在本设置下胜出——但这一结论高度依赖对手池的组成。Qwen3 和 GPT-5 的策略在面对主要为合作型对手的群体中效果最好。
8. 相关工作
论文将相关工作分为三类:
静态基准:提供固定输入和唯一参考答案(HotpotQA、GSM8K、HumanEval 等),但随着模型和训练语料规模扩大,越来越容易受到数据污染和 benchmark 过拟合的影响。
动态与 Agent 基准:
- 偏好型(ChatBot Arena、MT-Bench):捕捉人类偏好对齐,但依赖标注者行为,难以作为客观能力度量
- Agent 型(SWE-bench、BrowseComp、DeepSearchQA):更接近部署场景,但暴露的是固定工具接口和评估协议,主要测试模型能否在预定义规则内操作
需要交互的基准:TurtleBench(海龟汤)、Entity-deduction Arena(20 问)、ARC-AGI、Alpha Arena 等虽然需要交互才能成功,但:
- 没有显式隔离交互对性能的贡献
- 交互过程缺乏清晰的数学原则支撑
- 不能推广为统一的评估范式
论文的 Interactive Benchmarks 正是针对这些空白,提供了理论有据、跨任务可比、可复现的交互式评估框架。
9. 局限性与未来方向
方向一:交互中的信息增益失衡——为什么有些模型"问得多但问得差"?
论文的一个突出现象是:DeepSeek 在逻辑和数学任务中均需要最多交互轮次(18.0 轮 / 12.0 轮),但准确率并不高。这说明更多的交互并不等于更好的信息获取——存在"低效提问"的问题。当前框架将所有提问等价地消耗预算,但不同问题的信息增益差异极大。一个自然的研究问题是:能否用信息论工具(如 Expected Information Gain)来刻画 LLM 在交互式推理中的提问质量,进而理解为什么某些模型能用更少的轮次达到更高的准确率?核心思路是将每个 yes/no 问题视为对假设空间的一次二分操作,衡量模型实际选择的问题与理论最优问题(最大化熵减少)之间的差距,从而将"推理能力"分解为"搜索空间建模能力"和"信息获取效率"两个可独立研究的维度。
可借鉴的邻近工作:
- Pedrozo et al., 2026 "Do Reasoning Models Ask Better Questions? A Formal Information-Theoretic Analysis on Multi-Turn LLM Games"(从信息论角度分析了 20-questions 风格博弈中 LLM 的提问质量,但仅限于简单层级知识游戏,未涉及复杂推理任务中的假设空间建模)
- Li et al., 2025 "QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?"(28 citations,NeurIPS 2025,提出了主动信息获取的 benchmark,但关注的是单轮最优问题选择,未研究多轮交互中累积信息增益的动态优化)
方向二:交互式评估揭示的"能力解锁缺口"——pass@k 低估现象的认知机制
论文发现 pass@k 系统性地低估模型能力 20%-50%,且低估幅度在不同模型间差异显著(Grok 约 50%,Qwen3 约 20%)。这个缺口本身是一个值得深入研究的现象:它反映的不仅是计算效率问题,更可能揭示了模型"在外部反馈辅助下自纠错"的潜在能力。为什么某些模型(如 Grok)从交互中获益巨大而另一些(如 Kimi)获益甚少?一种假设是,这种"可解锁能力"与模型在预训练中学到的"内隐验证器"质量有关——模型本身对中间步骤正确性有部分判断力,但不足以在单次生成中可靠地自纠,而外部 verifier 的反馈恰好补充了这一短板。研究这种内隐验证能力与外部反馈之间的互补关系,可以指导我们设计更高效的推理范式——不是简单地重复采样,而是在关键步骤引入最小量的外部验证。
可借鉴的邻近工作:
- Jiang et al., 2025 "PAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier"(提出多轮 RL 框架让 LLM 在策略与验证器角色间切换进行选择性修正,但关注的是训练方法而非分析模型内隐验证能力的来源和边界)
- Wang et al., 2025 "Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods"(18 citations,研究了无验证器条件下推理时计算扩展的效率,提供了理解"模型何时需要外部验证vs.何时能自主纠错"的对比视角)
方向三:重复博弈中策略涌现的脆弱性——"善良策略"在对抗性环境下的崩溃边界
Trust Game 的结果显示,近乎无条件合作的策略(Qwen3 合作率 97%,背叛率 2%)在当前锦标赛中获得了最高收益。但这一结论高度依赖对手池的组成——当大多数对手也倾向合作时,"善良策略"自然占优。真正值得研究的问题是:这些策略在面对专门设计的对抗性或exploitative策略时会如何表现?经典博弈论中的 Folk Theorem 告诉我们,在折扣因子足够高时几乎任何可行收益向量都可以被支撑为均衡——但 LLM 的策略并非由理性计算产生,而是从预训练语料中涌现。研究 LLM 涌现策略的鲁棒性边界——在什么样的对手分布下策略会崩溃、崩溃的模式是什么——可以揭示预训练中获得的"社会直觉"的本质和局限。
可借鉴的邻近工作:
- Liu et al., 2026 "Scaling Inference-Time Computation via Opponent Simulation: Enabling Online Strategic Adaptation in Repeated Negotiation"(在重复谈判中构建辅助对手模型实现在线适应,提供了对手建模的技术基础,但未研究 LLM 预训练涌现策略本身的鲁棒性边界)
- Lin et al., 2026 "How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"(ICLR 2026,在扑克场景中研究 LLM 的博弈论推理与工具增强,揭示了 LLM 与专业玩家之间的策略差距,但聚焦于工具辅助提升而非策略脆弱性分析)
参考链接: