CodeHacker:自动化生成对抗测试用例以检测竞赛解法漏洞(CodeHacker: Automated Test Case Generation for Detecting Vulnerabilities in Competitive Programming Solutions)
作者:Jingwei Shi, Xinxiang Yin, Jing Huang, Jinman Zhao, Shengyu Tao
机构:上海财经大学、西北工业大学、美团、多伦多大学
论文的核心突破在于:把“构造 hack 反例”形式化为可自动执行的对抗测试生成任务,并通过“评测工具校准 + 多策略攻击生成”两阶段框架,显著提升代码基准对错误解法的识别能力(TNR),同时证明这类对抗样本可提升 RL 训练后的泛化表现。
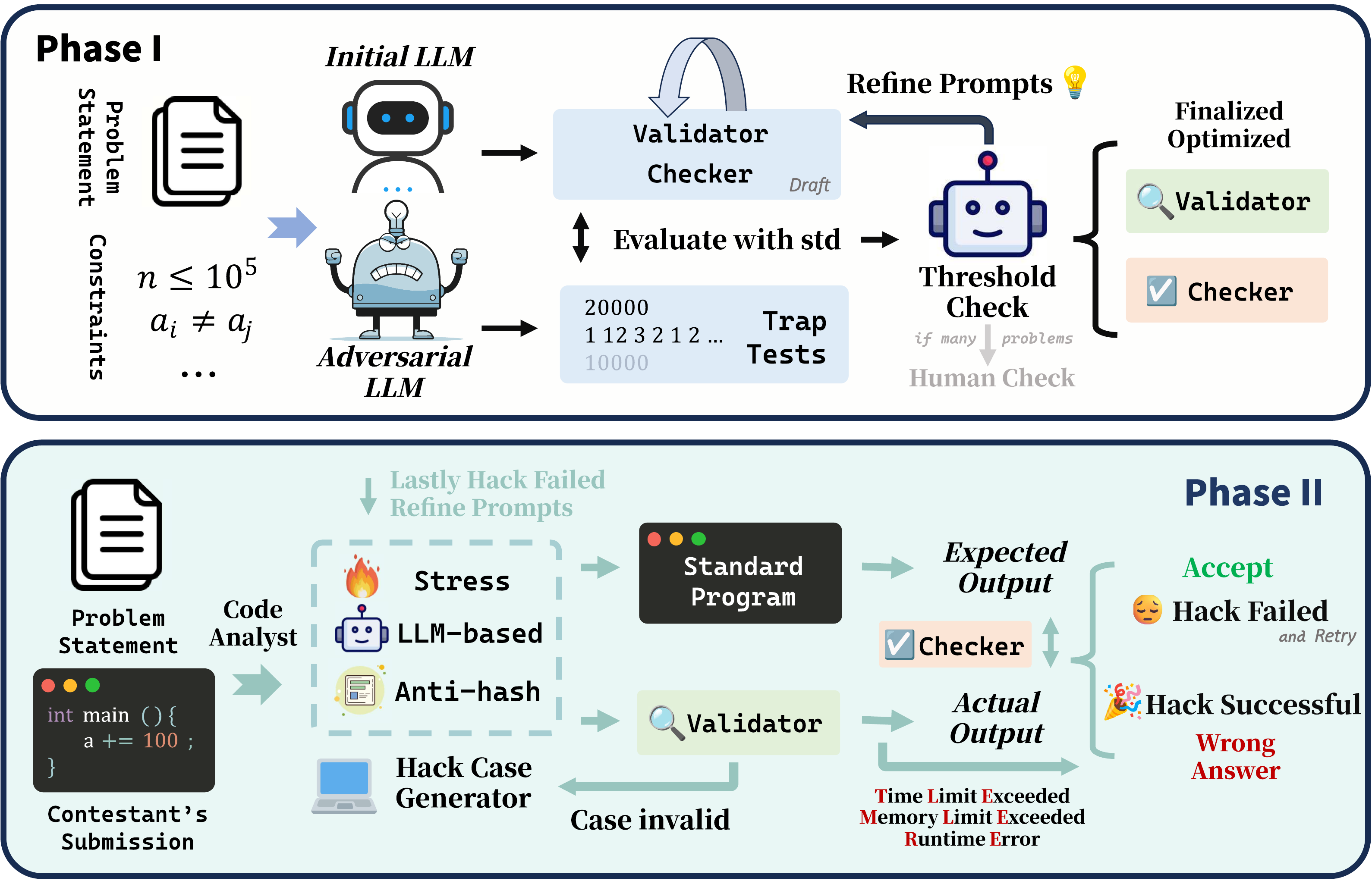
图1展示了论文主流程:
- Phase I:先校准评测基础设施(Validator、Checker),确保“输入合法性”和“判题正确性”本身可信。
- Phase II:在可信评测环境上生成对抗样例(Stress / LLM / Anti-Hash),针对具体提交触发 WA/RE/TLE/MLE。
1. 问题背景与动机
现有代码评测基准常见问题不是“题目不够难”,而是“测试覆盖不够尖锐”:
- 很多错误提交会在稀疏测试集上“侥幸 AC”;
- 黑盒式 fuzz 往往只能扩覆盖率,未必能命中具体程序的逻辑薄弱点;
- 人工构造强反例效果好,但不可扩展。
论文提出:应把“能否构造失败诱导样例(hack)”当作一种更高阶的程序推理能力信号,而不只是“随机测得更多”。
2. 方法:CodeHacker
2.1 形式化定义
对问题
论文把成功 hack 定义为:在最多
总体 Hack Success Rate(HSR)定义为:
核心点:这一定义强调“对具体提交的针对性反例搜索”,不是泛化的随机输入探索。
2.2 Phase I:评测工具校准(Calibration)
Validator Refinement
通过双向攻击发现验证器漏洞:
x_invalid被错误接受(False Positive);x_valid被错误拒绝(False Negative)。
若触发任一错误,就把失败样例回灌到 prompt,迭代修复 validator。
Checker Refinement
同样双向攻击 checker:
- 构造“格式像对但语义错误”的输出看是否被误接收;
- 构造“合法替代答案”看是否被误拒绝。
另外加入 anti-hallucination 流程(小规模输入 + 显式推理 + 独立 LLM 交叉核验)来降低 checker 更新时的误修复。
人工介入边界
论文明确:复杂校验逻辑下仍有小比例案例需人工介入(文中给出 <5%),主要是高难题上的验证逻辑实现成本过高。
2.3 Phase II:对抗样例生成
三类生成器互补:
- Stress Test:极限规模与结构模式,偏向触发 TLE/RE;
- LLM Generator:根据代码分析定向生成语义反例,覆盖 WA/RE/TLE/MLE;
- Anti-Hash Generator:针对 rolling hash,使用格约简(LLL 方向)与生日攻击构造碰撞样例。
并采用级联策略:优先 LLM 定向攻击,失败再回退 Stress;同时观察到“同题多提交共享漏洞”的跨提交泛化现象(一次生成可打掉多个提交)。
2.4 CodeHackerBench 构建
基于 CodeContest+ 的判题分歧样本构建基准,并采用双层人工核验:
- 对校准后的 Validator/Checker 进行基础设施审计;
- 对生成 hack case 随机抽样 600 条,报告 100% 有效性与可触发性。
3. 实验设置
- 主评估:从 CodeContest+ 随机抽取 2000 题(Traditional Judge 1000 + Special Judge 1000);
- 语言聚焦:C++(竞赛主流);
- 编译环境:对齐 Codeforces Windows toolchain(避免判题偏差);
- RL 验证:Qwen3-4B + DAPO,在 LiveCodeBench(AtCoder 子集)评估 pass@k。
4. 主要结果
4.1 基准质量对比(关键是 TNR 提升)
| 数据集 | VPR↑ | Traditional TPR↓ | Traditional TNR↑ | Special TPR↓ | Special TNR↑ |
|---|---|---|---|---|---|
| CodeContests | 71.41 | 98.96 | 76.33 | 84.73 | 77.69 |
| HardTests | 97.32 | 98.33 | 79.25 | 86.56 | 75.37 |
| TACO | 81.84 | 96.46 | 83.70 | 82.67 | 85.48 |
| CodeContest+ | 99.66 | 96.02 | 85.72 | 96.62 | 84.04 |
| CodeContest++ (Ours) | 100.00 | 95.86 | 96.31 | 96.38 | 96.05 |
解读:论文把“TPR略降 + TNR大幅升”解释为纠正指标膨胀,即把原本“误判为正确”的提交重新识别出来。
4.2 HSR:推理模型显著更强
| Backbone | HSR(%) | Avg.#T |
|---|---|---|
| DeepSeek V3.2 | 64.83 | 1.24 |
| GPT-5-Mini | 51.40 | 1.35 |
| Qwen3-Next-80B-A3B | 38.37 | 1.58 |
| Gemini-3.0-Flash-Preview | 35.65 | 1.62 |
| Qwen3-32B | 23.64 | 1.89 |
| DeepSeek V3.2*(non-thinking) | 23.76 | 2.45 |
论文重点强调:同模型关闭显式推理后,HSR 断崖式下降,支持“hacking 是推理任务”这一判断。
4.3 评测修正后的 Pass@1 变化
| 模型 | 原 Pass@1 | 调整后 Pass@1 | Δ |
|---|---|---|---|
| DeepSeek V3.2 | 83.3% | 81.6% | -1.7% |
| GPT-5-Mini | 78.4% | 76.7% | -1.7% |
| Gemini-3.0-Flash | 78.6% | 76.5% | -2.1% |
| DeepSeek V3.2* | 61.9% | 59.7% | -2.2% |
| Qwen3-32B* | 51.0% | 47.5% | -3.5% |
4.4 RL 训练收益
论文报告:使用增强后的对抗数据训练,LiveCodeBench 上表现稳定提升(尤其 medium/hard 难度),例如 pass@5:
- Easy:97.01 → 98.51
- Medium:73.53 → 80.88
- Hard:25.00 → 27.63
含义:对抗样本不仅提升“测评筛错能力”,也能作为更高密度训练信号,改善策略泛化。
5. 消融实验
5.1 组件消融(HSR)
| 变体 | HSR(%) |
|---|---|
| CodeHacker (Full) | 51.40 |
| w/o Code Analyst | 49.86 |
| w/o Stress Test | 50.12 |
| w/o Anti-Hash Generator | 51.00 |
| w/o Refinement Loop | 46.60 |
结论最明确:Refinement Loop 是刚需,去掉后跌幅最大。
5.2 数据增强流水线消融(Special Judge)
| 配置 | TNR(%)↑ | TPR(%) |
|---|---|---|
| Baseline (CodeContest+) | 82.18 | 95.34 |
| + Refined Validator | 82.08 | 95.50 |
| + Refined Checker | 84.04 | 96.62 |
| + Hack Cases (Ours) | 96.05 | 96.38 |
其中“仅加 validator 时 TNR 微降”是个有价值观察:旧数据里部分“非法输入误杀错误解”会虚高 TNR,清理后反而更真实。
6. 论文中的典型案例价值
文中给了多类具体案例:
- 弱 checker:把“多解题”当单解严格比对,导致误拒真解;
- 错误 validator:约束范围写错(过严或过松)导致错误评测;
- 启发式解法漏洞:在特定构造输入下暴露逻辑漏洞;
- 构造题 distinctness 漏检:固定模板构造导致重复元素未处理。
这些案例说明 CodeHacker 的价值不只在“大规模自动化”,还在于能逼近人类出题人/黑客常用的“针对性反例思路”。
7. 局限性与后续研究方向(含文献线索)
方向1:降低评测工具(Validator/Checker)的人力兜底比例
论文说明当前仍有少量高难题需要人工介入修复评测工具(主要集中在高难题与复杂判题逻辑)。下一步可以把“判题逻辑生成”从一次性代码产出,升级为可验证的合成流程:
- 先把约束与判题条件结构化;
- 再由模型生成可检查中间表示;
- 最后自动回归测试与一致性验证。
这样能减少“生成了 checker 但无法证明 checker 正确”的问题。
相关文献:
- HardTests(高质量测试构造):https://arxiv.org/abs/2505.24098
- CodeContests+(竞赛题高质量测试基线):https://arxiv.org/abs/2506.05817
- TCGBench(测试生成器可靠性评估):https://arxiv.org/abs/2506.06821
方向2:从竞赛题对抗评测迁移到更广义软件工程评测
论文在结论中明确提出可迁移到 SWE 类场景。关键挑战是:
- 竞赛题通常是“单程序 + 明确 I/O”;
- SWE 场景往往是“多文件 + 依赖环境 + 工程构建链 + 回归测试集”。
迁移时需要把“对单提交构造 hack 输入”扩展成“对工程系统构造回归失败触发条件”。
相关文献:
- LiveCodeBench(污染控制与持续评测协议):https://arxiv.org/abs/2403.07974
- OpenHands(面向软件任务的通用 Agent 平台):https://arxiv.org/abs/2407.16741
方向3:把离线对抗数据增强升级为在线闭环 RL 训练
论文已给出 RL 收益(增强数据训练后在 LiveCodeBench 有提升),但当前主流程仍偏离线。可继续演进为在线闭环:
- 模型生成解法;
- 对抗代理自动构造失败样例;
- 失败模式回灌策略更新;
- 再次生成并验证。
这样可把“是否被 hack”直接变成可验证训练信号,持续压缩模型在边界条件上的失败率。
相关文献:
- DAPO(文中采用的 RL 系统):https://arxiv.org/abs/2503.14476
- PPO(经典策略优化基线):https://arxiv.org/abs/1707.06347
- DeepSeekMath / GRPO 思路来源:https://arxiv.org/abs/2402.03300
8. 文献清单(按主题整理,便于继续深挖)
A. 代码基准与评测
- CodeHacker(本文):https://arxiv.org/abs/2602.20213
- CodeContests+:https://arxiv.org/abs/2506.05817
- LiveCodeBench:https://arxiv.org/abs/2403.07974
- TACO:https://arxiv.org/abs/2312.14852
- HardTests:https://arxiv.org/abs/2505.24098
B. 对抗样例与测试生成
- TCGBench(test case generator 可靠性):https://arxiv.org/abs/2506.06821
- LLM-powered test case generation for plausible programs(ACL 2025):https://aclanthology.org/2025.acl-long.29/
- Codeforces rolling-hash 对抗构造参考(文中 Anti-Hash 相关实践来源):https://codeforces.com/blog/entry/129538
C. 强化学习与训练方法
- DAPO:https://arxiv.org/abs/2503.14476
- PPO:https://arxiv.org/abs/1707.06347
- DeepSeekMath(GRPO):https://arxiv.org/abs/2402.03300
D. 竞赛代码能力背景
- AlphaCode(Science):https://www.science.org/doi/10.1126/science.abq1158
- HumanEval / Evaluating LLMs Trained on Code:https://arxiv.org/abs/2107.03374
原论文入口:
- arXiv Abstract:https://arxiv.org/abs/2602.20213
- arXiv HTML:https://arxiv.org/html/2602.20213
- DOI:https://doi.org/10.48550/arXiv.2602.20213