EvoCodeBench:面向“推理时自进化”代码系统的人类对齐评测基准
论文:EvoCodeBench: A Human-Performance Benchmark for Self-Evolving LLM-Driven Coding Systems
作者:Wentao Zhang, Jianfeng Wang, Liheng Liang, Yilei Zhao, HaiBin Wen, Zhe Zhao
链接:https://arxiv.org/abs/2602.10171
核心问题:传统代码基准主要看一次性正确率,难以评估“同一道题内反复修正(self-evolution)”带来的收益与代价。EvoCodeBench 的核心贡献是把正确率、效率(时间/内存)和人类参照指标放在同一个统一协议下评估,并显式支持迭代推理轨迹分析。
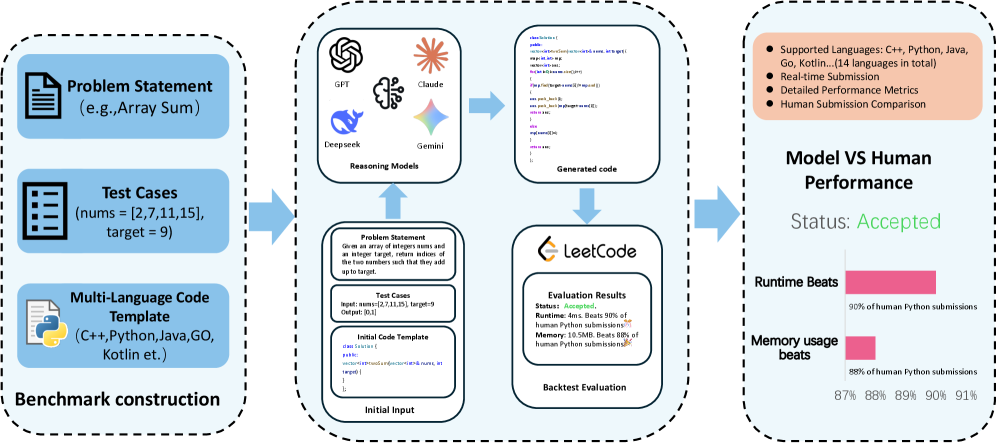
1) 背景与动机
论文指出,现有评测在三点上不够:
缺少推理时演化(inference-time self-evolution)评估
多数基准只看最终一次提交,无法回答“模型是否在反思-修正中变快/变准”。缺少人类参照刻度
单纯 pass rate 不容易解释“到底达到怎样的人类水平”。多语言评测长期偏高资源语言
例如 Python 占主流,而长尾语言(如 Kotlin)常被忽略;论文引用 TIOBE(2026-01)给出 Python 22.61%、Kotlin 0.97%。
2) EvoCodeBench 设计
2.1 评测对象与数据
- 基于 LeetCode 评测接口构建。
- 抓取总问题规模:3,822。
- 论文实验集:从中采样 100 题(降低旧题污染风险,并覆盖多标签)。
- 语言:Python3 / C++ / Java / Go / Kotlin。
2.2 两类 Agent 设定
- Vanilla Coding Agent:单次生成并提交。
- Self-evolving Coding Agent:在同一题内做反思-修订循环;论文设置最多 3 轮迭代。
关键控制变量:问题描述、提示格式、评测接口、模型参数保持不变,仅允许“解答代码”在迭代中改变。
2.3 指标体系
论文给出三组指标:
- 能力类:PR、TLE、MLE、CE、RE、WA、TO、RpE
- 效率类:AR(平均运行时)、AM(平均内存)、APC(平均通过测试数)
- 人类参照类:ARB(runtime beats)、AMB(memory beats)
其中 ARB/AMB 来自平台的人类提交分布分位统计,用于回答“模型在已 AC 解中的速度/内存相对人类处于什么水平”。
3) 实验设置
- 模型:deepseek-v3.2、grok-4.1-fast、gemini-3-flash-preview、gemini-3-pro-preview、claude-4.5-sonnet、claude-4.5-opus、gpt-5.2。
- 统一默认启用 reasoning。
- 单次最大输出 token:65,536。
- self-evolving 版本最多 3 轮反思修订。
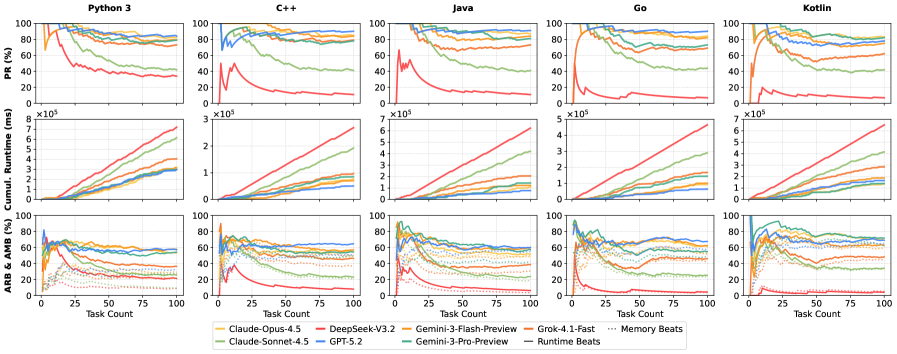
4) 主结果(跨模型、多语言)
4.1 能力层面(Pass Rate)
表 1 中各语言最高 PR:
- Python3:gpt-5.2 = 84
- C++:gpt-5.2 = 90
- Java:gpt-5.2 = 91
- Go:gpt-5.2 = 90
- Kotlin:claude-4.5-opus = 83(gpt-5.2 为 78)
论文观察:高资源语言到长尾语言会出现系统性退化,且不同模型退化形态不同(有的以 CE 激增为主,有的以 TLE 偏高为主)。
4.2 效率层面(时间/内存)
- 不是“pass 高就一定累计耗时低”;累计运行代价受失败惩罚和可执行稳定性共同影响。
- 论文用累计 runtime 轨迹显示:可执行性更稳定的模型长期曲线更低。
4.3 人类参照层面(ARB/AMB)
- 多个前沿模型在不少语言上都能达到 ARB/AMB
。 - 但论文强调要与 PR 联合看:低 PR 模型也可能在“少量成功样本”上给出高 beats,存在条件筛选效应。
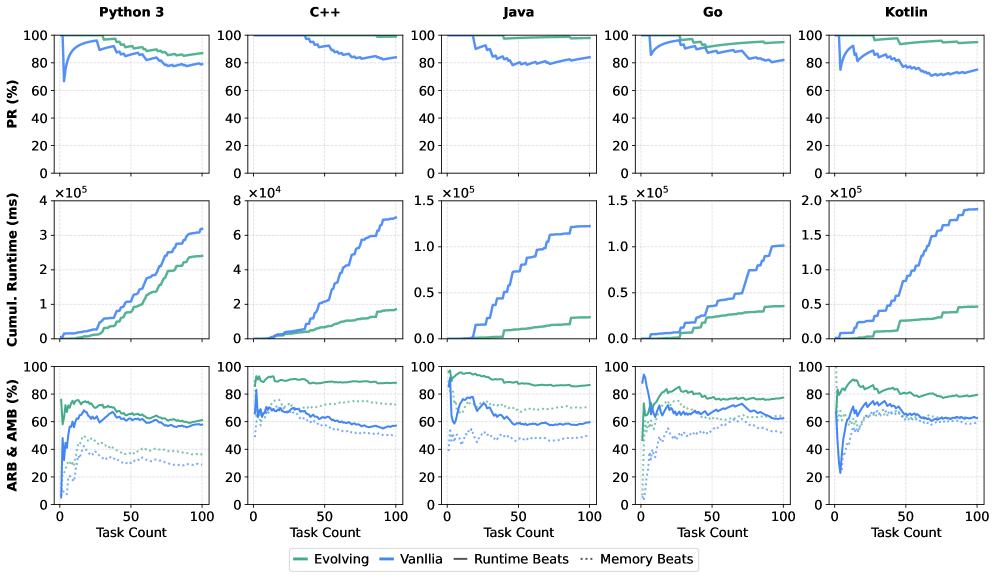
5) Self-evolving Agent 结果(论文表 2)
论文用 gemini-3-flash-preview 对比 vanilla 与 evolving:
- Python3:PR
(+10.1%) - C++:PR
(+17.9%) - Java:PR
(+16.7%) - Go:PR
(+15.9%) - Kotlin:PR
(+26.7%)
同时平均运行时下降:
- Python3:
ms(-7.8%) - C++:
ms(-46.4%) - Java:
ms(-23.0%) - Go:
ms(-19.8%) - Kotlin:
ms(-28.6%)
6) 论文结论(按原文主线)
- 只看最终正确率不足以评价“会迭代修正”的 coding agent。
- 统一评估中,语言资源分布差异会显著影响鲁棒性表现。
- Self-evolving 机制在多语言上都能带来可测的正确率与效率提升。
- 人类参照指标(ARB/AMB)能补充“模型 AC 后在工程效率上的相对位置”。
7) 可追溯链接
- arXiv Abstract:https://arxiv.org/abs/2602.10171
- arXiv HTML:https://arxiv.org/html/2602.10171
- DOI:https://doi.org/10.48550/arXiv.2602.10171