Scaling Agentic Verifier for Competitive Coding(论文重做版)
作者:Zeyao Ma, Jing Zhang, Xiaokang Zhang, Jiaxi Yang, Zongmeng Zhang, Jiajun Zhang, Yuheng Jing, Lei Zhang, Mingze Li, Wenting Zhao, Junyang Lin, Binyuan Hui
机构:Renmin University of China;Qwen Team, Alibaba Group
原文:https://arxiv.org/abs/2602.04254
核心问题:在竞赛编程 rerank 场景中,“随机输入+执行投票”为什么扩容后收益仍有限?核心答案:关键瓶颈不是输入数量,而是输入是否具有区分性(discriminative)。
1) 研究背景
在 competitive coding 中,常见流程是:
- 采样多份候选代码;
- 用 verifier 选最优候选。
已有 execution-based 方法的现实困难:
- 生成“输入+标准输出”的完整测试样例很贵,甚至接近“再解一次题”;
- 退化到 input-only 后,随机输入大量落在“无区分区域”,候选解行为差异暴露不出来。
作者因此提出:把 verifier 从“随机采样器”升级为“可训练的 agent”,主动搜反例输入。
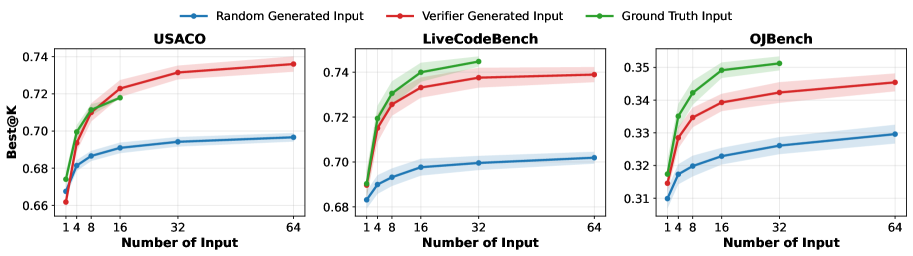
2) 关键观察:随机扩容并不解决问题
作者在 USACO / LiveCodeBench v6 / OJBench 上先做先验实验:
- policy:Qwen3-30B-A3B-Thinking-2507;
- 每题采样 64 个候选解;
- 比较输入来源:随机输入 vs benchmark 原始测试输入(ground-truth inputs)vs 训练后 verifier 输入。
结论:
- ground-truth inputs 在小预算下就明显领先随机输入;
- 随机输入数量从小到大扩容,收益很快饱和;
- verifier 生成输入显著优于随机输入,在 USACO 上甚至超过 ground-truth 输入。
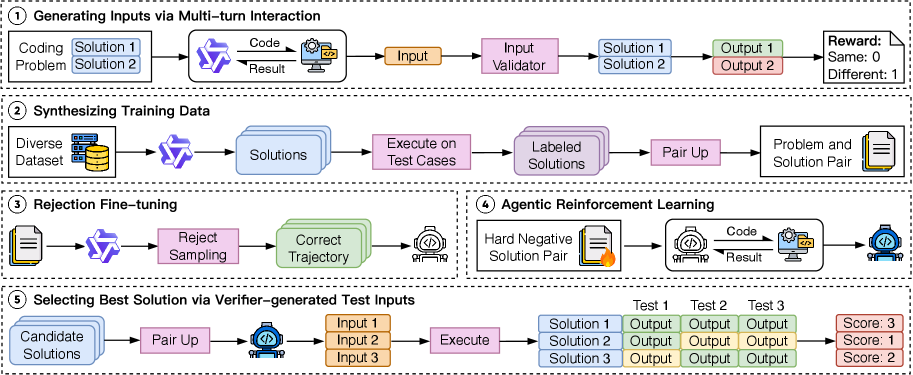
3) 方法细节
3.1 Input-only 执行投票(论文公式)
给定候选解
对每个输入
总票数:
取
3.2 Agentic Verifier 任务定义
单个训练样本是
:题目; :候选解对; - verifier 输出一个输入生成程序
,产生 。
目标:
合法(满足题目输入约束); 可区分(两程序行为不同):
3.3 训练奖励
3.4 三阶段训练流程
- Data Synthesis:构造大规模
,并合成高置信测试环境;论文报告每题平均约 60 个 test cases。 - Rejection Fine-tuning:用强教师采多轮交互轨迹,保留成功区分样本做监督训练;规模约 60K 高质量轨迹。
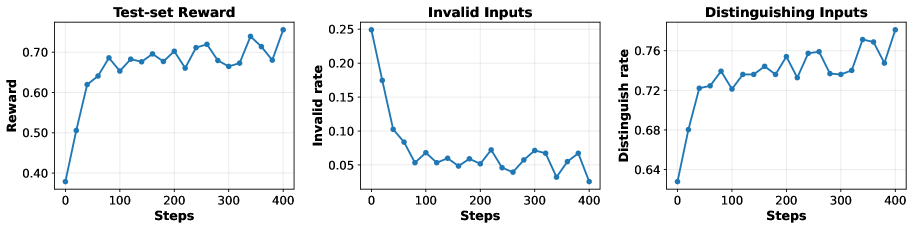
- Agentic RL(GRPO):在难样本上强化,提升“生成合法且可区分输入”的能力(文中报告约 10K queries,保留 500 作为 held-out 监控)。
4) 实验设置(可复核)
- Policy 模型:Qwen3-30B-A3B-Thinking-2507 / Qwen3-235B-A22B-Thinking-2507
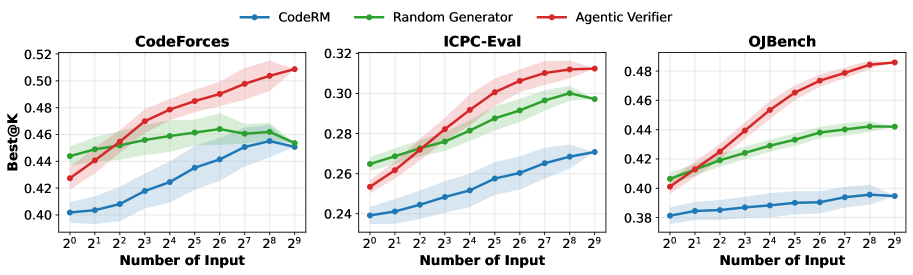
- 基准:USACO、LiveCodeBench、OJBench、ICPC-Eval、CodeForces(文中新增,来自 88 场比赛共 64 题)
- 对比方法:Vanilla、Grading RM、MBR-Exec、CodeT、CodeRM、Random Generator
- 指标:Best@8、Best@64
- 统一预算:输入/测试生成相关 baseline 预算 512
5) 主结果(表格关键信息)
5.1 在 Qwen3-30B policy 下
- USACO:73.1 / 74.5
- LiveCodeBench:73.6 / 73.7
- OJBench:33.5 / 34.9
- ICPC-Eval:23.1 / 25.8
- CodeForces:43.0 / 46.4
5.2 在 Qwen3-235B policy 下
- USACO:83.0 / 84.1
- LiveCodeBench:81.6 / 82.9
- OJBench:45.9 / 48.6
- ICPC-Eval:29.9 / 31.2
- CodeForces:49.9 / 50.9
论文给出的整体量级:相对强执行基线可达 +10~15 绝对点(不同 benchmark / setting 有差异)。
6) 分析结论(论文第5节)
- 输入预算扩容时,Agentic Verifier 的 scaling 更稳。
- 题目越难,优势越大。 在 OJBench hard 子集,增益明显高于 easy 子集。
- 训练型 verifier > 零样本 verifier。 论文报告训练后的 30B verifier 可超过零样本 235B verifier。
- 可用于发现 benchmark false positives。
7) “不完美验证器”案例(论文附录A)
论文给了一个典型反例:
- 输入:
; - 两个都“过了原测试集”的候选,在 verifier 输入下输出冲突:159 vs 167。
论文解释是:
- 一份代码实际上优化了“放松约束问题”(忽略动态邻接约束);
- 固定 benchmark 测试集未覆盖到该漏洞;
- verifier 生成输入把这个 false positive 显式暴露出来。
这部分非常重要:说明该方法不只是 rerank,还可作为 test-suite augmenter。
8) 局限
- 当前核心场景仍是竞赛编程,向 SWE 多文件工程迁移成本更高;
- 训练基础设施重(轨迹采样、执行环境、数据合成);
- 结果仍依赖执行环境的稳定性与输入合法性检查质量。