X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests(论文重做版)
作者:Jie Wu, Haoling Li, Xin Zhang, Jiani Guo, Jane Luo, Steven Liu, Yangyu Huang, Ruihang Chu, Scarlett Li, Yujiu Yang
原文:https://arxiv.org/abs/2601.06953
核心问题:竞赛编程数据稀缺且污染风险高,是否可以只用“全合成任务+解答+测试”把 7B/8B 代码模型推到专家级表现?论文答案是:可以,但前提是合成质量控制必须足够强。
1) 动机与目标
论文认为 competitive programming 的数据瓶颈主要在三点:
- 任务要“可解且难”,随便合成容易变成简单题或歧义题;
- SFT 需要高质量长推理解答,错误解会污染监督;
- RL 依赖可靠测试信号,弱测试会导致奖励噪声。
因此作者构建了一个端到端合成框架:
- 合成任务;
- 合成测试输入;
- 合成候选解;
- 用 dual-verification 同时校验“测试标签质量”和“gold solution 质量”。
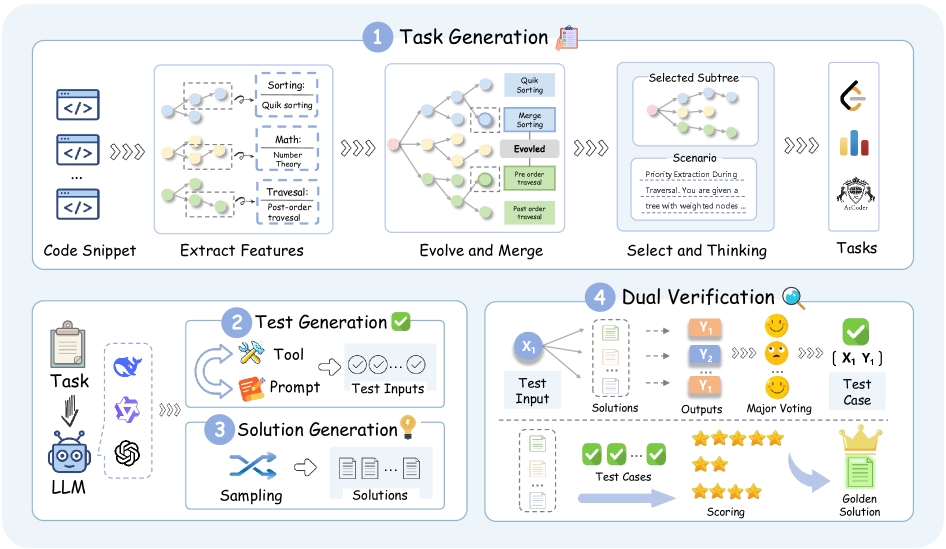
2) 数据合成框架(论文第3节)
2.1 任务合成:feature-based + 竞赛域适配
在 EpiCoder 的 feature-tree 思路上,作者做了 domain adaptation:
- 从 TACO 10k 题解中抽竞赛特征(算法、数据结构、复杂度、优化等);
- 宽度 + 深度双向演化特征树;
- 采用两阶段生成:先选兼容子树,再生成题面(避免一步法过度简化)。
并支持多风格题面:Codeforces / LeetCode / AtCoder。
2.2 测试输入合成
论文对比:
- prompting-based 测试生成;
- tool-based(CYaRon)测试生成。
文中结果显示 tool-based 在覆盖与区分性上更强(但成本更高)。
2.3 候选解合成与过滤
每题生成多候选解,过滤标准包含:
- 含完整 reasoning + code;
- AST 语法有效;
- 去除异常长、格式破损、多代码块干扰样本。
3) Dual-Verification(本文关键)
3.1 Step 1:投票得到临时测试标签
对于输入
并给每个测试样例赋权
3.2 Step 2:加权选 golden solution + hold-out 验证
在
再到
论文还额外做 solvability filtering:用强模型(如 GPT-5 高推理)筛掉明显不可解/高歧义任务。
4) 训练与评测设置
- 训练范式:SFT-then-RL
- backbone:Qwen2.5-Coder-7B-Instruct、Qwen3-8B-Base
- 评测主基准:LiveCodeBench v5 / v6
- 主指标:avg@8
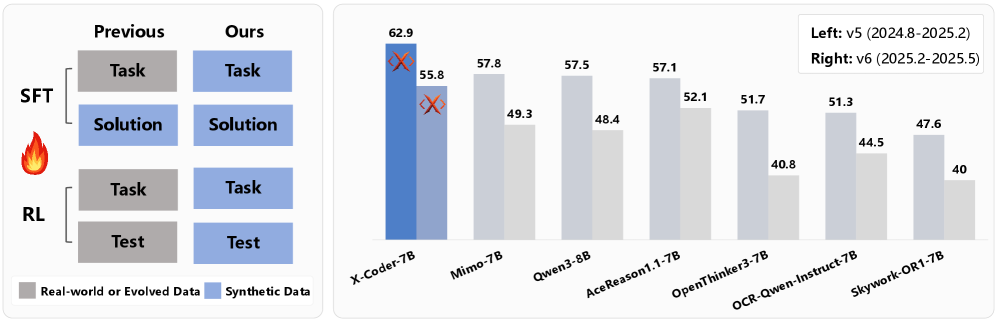
5) 主结果(论文表1核心)
5.1 SFT 阶段
- X-Coder-Qwen2.5-SFT:v5 60.3±2.5,v6 53.5±1.7
- X-Coder-Qwen3-SFT:v5 59.4±2.0,v6 55.4±2.3
5.2 SFT+RL 阶段
- X-Coder-Qwen2.5:v5 62.9±1.8,v6 55.8±1.9
- X-Coder-Qwen3:v5 64.0±2.5,v6 56.5±1.3
结论:在论文对比设定下,7B/8B 模型可达到并超过一批更大模型或 real-data 路线基线。
6) 关键消融
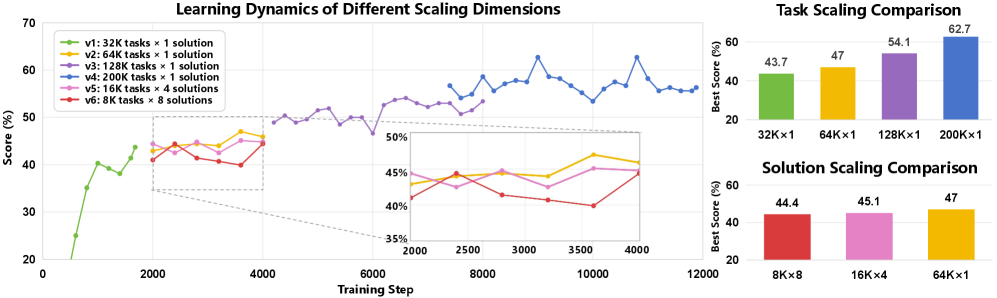
6.1 数据规模扩展有效
随着 synthetic data 规模从小到大,性能单调上升(论文给出明显 scaling 曲线)。
6.2 “任务多样性”优于“同题多解”
在 token 预算固定下,增加 unique tasks 比增加每题 solution 数更有效。
6.3 Dual-verification 显著提升质量
论文示例(64k 规模):
- raw solutions:LCB v5 = 47.0
- verified solutions:LCB v5 = 53.4
- 提升:+6.4
6.4 Long-CoT 明显优于 Short-CoT
同等训练设定下,长推理轨迹带来显著更高上限,但收敛更慢、训练更贵。
6.5 领域特化演化是必要条件
相比通用合成策略,domain-adapted feature evolution 在竞赛题上提升显著。
7) 误差与行为分析(论文第6节)
论文统计失败类型分布:
- Wrong Answer 仍是主因;
- 其次是 No Code Block(长推理导致截断)与 TLE。
此外,论文还分析了:
- reasoning token 越长并不保证更高 pass,往往反映题更难;
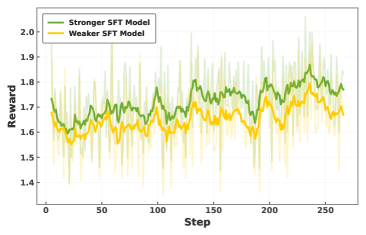
- RL 可显著提 pass@1,但其收益受 SFT 初始化质量影响(good-gets-better)。
8) 局限
- dual-verification 成本高(轨迹与执行代价大);
- 合成质量依赖验证器和候选池强度;
- 主要验证集中在 competitive programming,跨到复杂 SWE 任务需新设计。