自动化构建 SWE 数据集(SWE Data Construction, Automatically!)
作者:Lianghong Guo, Yanlin Wang (通讯), Caihua Li, Wei Tao, Pengyu Yang, Jiachi Chen, Haoyu Song, Duyu Tang, Zibin Zheng 机构:Sun Yat-sen University, Huawei Technologies, Independent Researcher
论文的核心突破在于提出 SWE-Factory,首个开源的全自动 GitHub Issue 解决数据集构建流水线,通过多智能体系统自动化环境搭建、基于退出码的日志解析自动化 fail2pass 验证,并在四种编程语言上验证了有效性,同时证明了所收集数据可显著提升模型的软件工程能力。
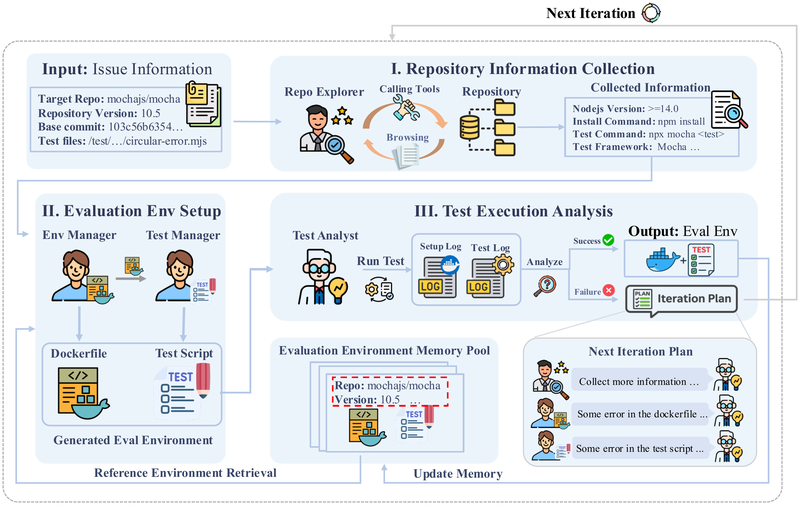
图1展示了 SWE-Builder 多智能体系统的整体架构。系统由四个协作 Agent 组成:Repository Explorer 负责从仓库中自动收集环境信息;Environment Manager 根据收集到的信息生成 Dockerfile;Test Manager 生成测试脚本;Test Analyst 验证生成的环境并在失败时提供反馈指导迭代优化。右侧的 Evaluation Environment Memory Pool 存储历史成功配置,供后续相似版本的 issue 复用。整个流程通过迭代循环不断优化,直到环境验证通过或达到最大迭代次数。
1. 引言与问题背景
GitHub Issue 解决任务(bug 修复、功能增强等)是评估 LLM 软件工程能力的关键基准。SWE-bench 是该领域最具代表性的基准,其成功催生了大量后续工作。然而,现有的数据集构建流水线存在三个核心痛点:

图2展示了传统四阶段流水线:仓库选择 → Issue 数据收集 → 评估环境构建 → Fail2Pass 验证。其中后两个阶段严重依赖人工操作。
论文识别出的三个关键问题:
- P1:二进制测试文件缺失。通过 GitHub API 收集的 test patch 中,涉及二进制文件(如 .png、.tif、.zip)的修改内容为空。这在图像处理库中尤为严重——Pillow 有 30.43% 的实例受影响,matplotlib 有 22.10%
- P2:评估环境构建需要大量人工。不同语言、不同仓库、不同版本的依赖和测试命令差异巨大,需要研究者逐一查阅文档手动配置
- P3:Fail2Pass 验证依赖人工。需要人工检查测试日志并编写自定义解析器提取测试状态,而日志格式在不同项目、不同框架、甚至同一项目的不同版本间都不一致
核心动机:现有流水线的人工密集性严重限制了大规模、高质量 Issue 解决数据集的构建效率和可扩展性。
2. 方法:SWE-Factory
SWE-Factory 从三个层面解决上述问题:二进制文件修复(解决 P1)、SWE-Builder 多智能体环境构建(解决 P2)、基于退出码的 fail2pass 验证(解决 P3)。
2.1 二进制测试文件修复
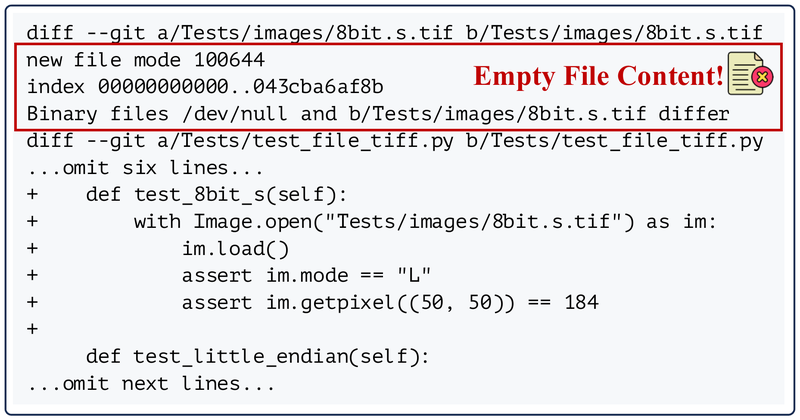
图3展示了一个典型案例:test patch 中对 8bit.s.tif 文件的修改仅显示 "Binary files ... differ" 占位符,实际内容为空。这导致两个后果:(1)测试用例缺少必要输入文件,即使 patch 成功应用也无法执行;(2)git apply 操作本身可能失败,导致后续的代码修改也无法生效。
解决策略简洁有效:通过预定义模式检测二进制文件,自动生成 wget 下载命令恢复文件内容,然后从 test patch 中移除不完整的二进制相关 hunk,确保剩余 patch 可以正常应用。
2.2 SWE-Builder:多智能体自动环境构建
SWE-Builder 由四个专职 Agent 协作完成环境构建(见图1):
Repository Explorer:自动从仓库中收集环境构建所需信息。具体提取三类内容:(1)依赖配置文件(如 Python 的 requirements.txt、Java 的 pom.xml);(2)测试命令(如 pytest、mvn test);(3)文档中的安装说明(如 CONTRIBUTING.md)。Agent 通过迭代式工具调用(browse_file、browse_dir、search_keyword)自主探索仓库,直到收集到足够信息或达到最大轮次。
Environment Manager:根据 Repository Explorer 收集的信息生成 Dockerfile,将复杂的环境配置脚本化为可复现的容器格式。跨迭代保留生成历史,失败时以上一版 Dockerfile 作为 fallback。
Test Manager:生成用于执行测试的 shell 脚本。其 prompt 中包含两条关键指令:(1)插入二进制文件下载命令以确保 test patch 正确应用;(2)在测试命令后追加退出码捕获命令 rc=$? 和 echo "OMNIGRIL_EXIT_CODE=$rc",为自动化验证提供标准化接口。
Test Analyst:验证生成的环境质量。按序调用 build_image → start_container → run_eval 构建并测试环境。若测试通过则任务完成;若失败则分析错误日志,生成针对性优化方案并分派给对应 Agent 进行下一轮迭代。
SWE-Builder 使用的工具集如下:
| 工具签名 | 功能描述 | 输出 |
|---|---|---|
browse_file(fp, q) | 从文件中提取与查询相关的内容 | 相关代码片段 |
browse_dir(fp, d) | 返回指定深度的目录树 | 目录结构 |
search_keyword(kw) | 搜索包含关键词的文件路径 | 匹配的文件路径 |
build_image(df) | 从 Dockerfile 构建 Docker 镜像 | 镜像 ID 或构建日志 |
start_container(img) | 从镜像启动容器 | 容器 ID 或错误日志 |
run_eval(ct, es) | 在容器中执行评估脚本 | 评估日志 |
Evaluation Environment Memory Pool:基于一个关键观察——同一仓库中相近版本的 issue 通常共享相似的依赖环境和测试框架。Memory Pool 归档每个成功验证的环境配置(Dockerfile + 测试脚本),当处理新 issue 时,Environment Manager 和 Test Manager 先从 Pool 中检索同仓库最近版本的配置作为基线,从而加速生成过程并提高一致性。
工作流编排:首轮迭代执行完整流程(Repository Explorer 收集信息 + Memory Pool 检索参考 → Environment Manager 生成 Dockerfile → Test Manager 生成脚本 → Test Analyst 验证)。后续迭代则是定向修复——Test Analyst 仅调度出错组件对应的 Agent,例如仅测试脚本有误时只调用 Test Manager,跳过其他 Agent。迭代持续直到验证通过或达到最大次数(实验中设为 5)。
设计亮点:SWE-Builder 的迭代修复机制不是全量重跑,而是基于错误分析的定向修复,这显著提高了效率。
2.3 基于退出码的 Fail2Pass 自动验证
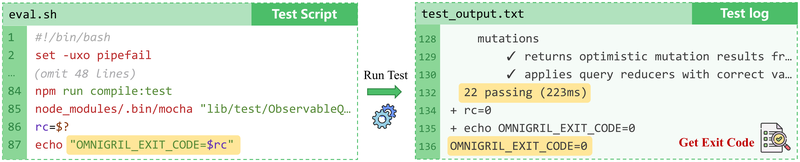
图4展示了退出码捕获机制的具体实现:在测试命令(如 pytest)执行后,脚本追加 rc=$? 捕获退出码,再通过 echo "OMNIGRIL_EXIT_CODE=$rc" 输出带唯一标识符的状态标记。
这一设计将复杂的日志解析问题转化为简单的模式匹配:用正则表达式搜索 OMNIGRIL_EXIT_CODE 标记,退出码为 0 表示测试通过,非 0 表示失败。验证流程为:对每个 issue 分别在应用 gold patch 前后执行测试脚本,仅当状态从 "fail" 变为 "pass" 时保留该实例。
关键洞察:主流测试框架(pytest、JUnit、Jest、Mocha 等)均通过进程退出码报告测试结果,这一通用约定使得退出码成为跨语言、跨框架的统一接口,完全绕过了日志格式多样性的难题。
3. 实验设置
基座模型:选择三个成本效益较高的模型作为 SWE-Builder 的基座——GPT-4.1-mini($0.40/$1.60 per 1M tokens)、Kimi-K2($0.60/$2.50)、DeepSeek-V3-0324($0.27/$1.10)。
评估数据集 SweSetupBench:从 12 个知名开源仓库中采样 671 个 issue,覆盖 Python、Java、JavaScript、TypeScript 四种语言。采用基于版本的分层抽样(每个版本随机抽取 20%),确保版本覆盖的全面性。仓库涵盖 Pillow、click、attrs(Python)、assertj、checkstyle、vert.x(Java)、mocha、dayjs、undici(JavaScript)、apollo-client、tailwindcss、redux-toolkit(TypeScript),GitHub stars 从 2.7k 到 88.3k 不等。
超参数:SWE-Builder 最大迭代次数 5,模型温度 0.1,Repository Explorer 最大检索轮次 10,20 个并行子进程。
4. RQ1:SWE-Builder 的有效性
| 模型 | 数据集 | F2P Rate (%) | Output Rate (%) | 时间 (min) | 成本 ($) |
|---|---|---|---|---|---|
| GPT-4.1 mini | Full | 50.2 (337/671) | 64.8 (435/671) | 26.3 | 0.047 |
| Python | 54.0 (107/198) | 73.7 (146/198) | 19.0 | 0.040 | |
| Java | 43.5 (81/186) | 50.5 (94/186) | 31.8 | 0.061 | |
| TS | 55.1 (97/176) | 68.2 (120/176) | 29.6 | 0.042 | |
| JS | 46.8 (52/111) | 67.6 (75/111) | 25.2 | 0.042 | |
| Kimi-K2 | Full | 47.8 (321/671) | 63.2 (424/671) | 30.2 | 0.056 |
| Python | 54.0 (107/198) | 70.7 (140/198) | 26.5 | 0.051 | |
| Java | 33.9 (63/186) | 48.4 (90/186) | 38.9 | 0.073 | |
| TS | 56.3 (99/176) | 68.2 (120/176) | 27.0 | 0.047 | |
| JS | 46.8 (52/111) | 66.7 (74/111) | 27.7 | 0.050 | |
| DeepSeek-V3 | Full | 42.0 (282/671) | 53.4 (358/671) | 23.0 | 0.037 |
| Python | 54.5 (108/198) | 70.2 (139/198) | 16.2 | 0.030 | |
| Java | 30.1 (56/186) | 39.8 (74/186) | 26.4 | 0.047 | |
| TS | 42.0 (74/176) | 49.4 (87/176) | 28.6 | 0.035 | |
| JS | 39.6 (44/111) | 52.3 (58/111) | 20.9 | 0.035 |
核心发现:
- 三个模型均能有效构建评估环境,F2P Rate 均超过 42%,Output Rate 超过 53%,单任务成本低于 $0.06
- GPT-4.1 mini 综合最优:F2P Rate 50.2%,Output Rate 64.8%
- DeepSeek-V3 性价比最高:每美元可生成约 11.4 个有效实例(GPT-4.1 mini 为 10.7,Kimi-K2 为 8.5),适合大规模预算受限场景
- 语言维度存在模型偏好差异:Python 上三者表现接近(DeepSeek-V3 略优);Java 上 GPT-4.1 mini 显著领先;TypeScript/JavaScript 上 Kimi-K2 和 GPT-4.1 mini 表现相当,均优于 DeepSeek-V3
5. RQ2:消融实验
论文对 SWE-Builder 的四个关键组件进行了消融研究。
二进制测试文件检测(BTFD):在 SweSetupBench 中 44 个涉及二进制文件的实例上,移除 BTFD 后所有模型的 F2P Rate 均降至 0%。原因是原始 test patch 不含二进制文件实际内容,导致 patch 应用失败,代码库停留在 base commit 状态。
其余三个组件的消融结果(671 个 issue):
| 模型 | 设置 | F2P Rate (%) | Output Rate (%) | 时间 (min) | 成本 ($) |
|---|---|---|---|---|---|
| GPT-4.1 mini | Baseline | 50.2 | 64.8 | 26.3 | 0.047 |
| w/o Repo Explorer | 42.9 | 55.3 | 25.9 | 0.021 | |
| w/o Memory Pool | 45.0 | 58.3 | 30.0 | 0.050 | |
| w/o Exec Feedback | 0.3 | 3.8 | 7.25 | 0.096 | |
| Kimi-K2 | Baseline | 47.8 | 63.2 | 30.2 | 0.056 |
| w/o Repo Explorer | 47.1 | 60.4 | 32.6 | 0.032 | |
| w/o Memory Pool | 41.7 | 54.7 | 35.3 | 0.055 | |
| w/o Exec Feedback | 2.7 | 11.5 | 6.1 | 0.077 | |
| DeepSeek-V3 | Baseline | 42.0 | 53.4 | 23.0 | 0.037 |
| w/o Repo Explorer | 33.5 | 44.3 | 20.0 | 0.016 | |
| w/o Memory Pool | 37.7 | 45.8 | 27.5 | 0.038 | |
| w/o Exec Feedback | 0.7 | 16.4 | 15.8 | 0.065 |
核心发现:
- Execution Feedback 是最关键组件:移除后 F2P Rate 崩溃至接近 0%。虽然跳过环境构建和测试执行缩短了时间,但模型因缺乏反馈而反复尝试,导致迭代次数和成本反而增加
- Repository Explorer 提供有价值的上下文:移除后 F2P Rate 平均下降约 7%(Kimi-K2 受影响较小,可能因其训练数据已包含相关仓库信息)。移除后 API 成本显著降低,因为省去了频繁的仓库探索工具调用
- Memory Pool 通过经验复用提升效率:移除后 F2P Rate 平均下降 5.2%,平均时间增加(需要更多迭代弥补缺失的先验经验)
消融实验的核心结论:动态执行反馈是环境构建成功的决定性因素——没有"试错-修正"循环,仅靠静态代码分析几乎无法构建出有效的评估环境。
6. RQ3:退出码验证方法的准确性
论文通过人工评估验证退出码方法的正确性。从三个模型生成的结果中收集 1,201 个任务实例,由三位研究者独立标注每条测试日志的状态,分歧通过讨论解决。
| 数据来源 | 实例数 | TP | FP | TN | FN | Precision (%) | Recall (%) | F1 |
|---|---|---|---|---|---|---|---|---|
| GPT-4.1 mini | 434 | 337 | 0 | 97 | 0 | 100 | 100 | 1.000 |
| DeepSeek-V3 | 352 | 277 | 0 | 71 | 4 | 100 | 98.6 | 0.993 |
| Kimi-K2 | 415 | 309 | 0 | 94 | 12 | 100 | 96.3 | 0.981 |
| 总计 | 1,201 | 923 | 0 | 262 | 16 | 100 | 98.3 | 0.991 |
F1 达到 0.99,Precision 为 100%(零误报)。16 个 False Negative 均源于测试脚本生成错误,分为两类:
- 标识符错误(4/16):LLM 生成了错误的标识符(如
OMNIGRIL_CODE而非OMNIGRIL_EXIT_CODE),导致解析器无法匹配 - 脚本提前终止(12/16):脚本中错误包含了
set -e命令,导致测试失败时脚本立即退出,未能执行到退出码输出行

图5展示了 set -e 导致的问题:当测试命令返回非零退出码时,shell 立即终止,echo "OMNIGRIL_EXIT_CODE=$rc" 行永远不会被执行。这类问题可通过简单的模式匹配检测并手动修正。
此外,论文还单独验证了退出码本身判断测试状态的可靠性:在 2,380 条正确输出退出码的测试日志上,退出码判断与人工检查完全一致,F1 = 1.0。
7. 探索性实验:利用 SWE-Factory 提升模型软件工程能力
论文进一步探索了 SWE-Factory 收集的数据能否用于训练以提升模型能力。
数据构建流程:
- 从 10 个 Python 仓库中使用 GPT-4.1 mini 自动构建 2,877 个任务实例(仓库与 SWE-bench 不重叠以避免数据泄露)
- 使用 Kimi-K2 作为 agent 模型、DeepSWE 作为 agent 框架,为 2,809 个环境生成对应的 agent 交互轨迹
- 在 8 张 A800 GPU 上对 5 个基座模型进行全参数 SFT(3 个 epoch,最大序列长度 65,536,学习率 1e-5)
训练模型:Qwen2.5-Coder-Instruct(3B/7B/14B)、Qwen3-8B-Instruct、Llama-3.1-8B-Instruct
SWE-bench Verified(500 实例)上的结果:
| 模型 | 参数量 | EP Base→SFT | TF Base→SFT | RR Base→SFT |
|---|---|---|---|---|
| Qwen2.5-Coder | 3B | 90.8→16.4 | 92.8→8.9 | 0.0→3.4 (+3.4) |
| Qwen2.5-Coder | 7B | 91.0→4.4 | 82.4→1.01 | 0.0→13.6 (+13.6) |
| Qwen2.5-Coder | 14B | 4.6→6.6 | 5.1→0.5 | 5.8→21.0 (+15.2) |
| Qwen3-Instruct | 8B | 78.0→17.4 | 0.2→4.1 | 3.4→16.2 (+12.8) |
| Llama-3.1-Instruct | 8B | 41.0→19.6 | 43.2→5.6 | 1.2→5.2 (+4.0) |
(EP = Empty Patch Rate,TF = Tool Call Failure Rate,RR = Resolve Rate)
核心发现:
- 所有模型在微调后 Resolve Rate 均提升,最显著的是 Qwen2.5-Coder-14B:从 5.8% 提升至 21.0%(+15.2%)
- 参数量越大,提升越显著:14B 模型提升 15.2%,7B 提升 13.6%,3B 仅提升 3.4%。论文认为这是因为更大模型具有更强的基础编码能力,微调能释放更大潜力
- SFT 主要改善了三个维度:(1)大幅降低 Empty Patch Rate(模型不再频繁提交空 patch);(2)显著降低 Tool Call Failure Rate(工具调用更准确);(3)增加与环境的交互轮次(更充分地探索和修复)
训练实验表明 SWE-Factory 收集的数据具有实际训练价值,仅用 2,809 个 Python 实例就能带来显著的性能提升。
8. 局限性与未来研究方向
方向1:从"环境构建"到"环境理解"——构建可迁移的环境知识图谱
SWE-Builder 当前的 Memory Pool 仅做版本级别的浅层匹配(同仓库最近版本),本质上是一个 key-value 缓存。然而,软件项目的环境配置存在跨仓库的深层结构相似性——例如使用相同测试框架的项目共享类似的环境模式,依赖同一底层库的项目面临相似的版本冲突。一个值得探索的方向是构建结构化的环境知识图谱,将依赖关系、框架版本、常见配置模式编码为可推理的知识表示,实现跨仓库的环境知识迁移。这可以结合 RAG 技术,在遇到全新仓库时检索结构相似的历史配置,而非从零开始。这个方向有足够的工作量:需要设计环境配置的表示学习方法、构建跨仓库的相似性度量、以及验证迁移学习在环境构建中的有效性。 相关工作:Hu et al., 2025 "Repo2Run"(大规模自动构建可执行环境,与 SWE-Factory 目标最接近的并行工作) | Zhang et al., 2026 "DockSmith"(专用 Agent 构建 Docker 环境,探索了环境配置的可复用性) | Li et al., 2026 "HerAgent"(通过分层测试金字塔重新思考环境部署策略)
方向2:退出码方法的边界条件——面向非标准测试框架的自适应验证
论文的退出码方法依赖一个强假设:测试框架通过进程退出码报告结果。虽然主流框架(pytest、JUnit、Jest)遵循这一约定,但现实中存在大量非标准场景:自定义测试脚本可能不遵循退出码约定、某些框架在部分测试失败时仍返回 0、集成测试可能涉及多进程且退出码语义不一致。当前 16 个 False Negative 中的 set -e 问题也暴露了 shell 脚本层面的脆弱性。一个有价值的研究方向是设计自适应的测试状态提取方法:先通过退出码快速判断,对不确定的情况自动切换到轻量级日志分析(例如用小型 LLM 解析关键行),形成分层验证策略。这需要系统性地调研不同测试框架的退出码行为、设计不确定性检测机制、以及评估分层策略的成本-准确率权衡。 相关工作:Xu et al., 2024 "DivLog"(用 LLM in-context learning 做日志模板解析,可作为分层验证中日志分析层的技术基础) | Zhang et al., 2025 "ScalaLog"(LLM 驱动的可扩展日志故障诊断,验证了 LLM 解析非结构化日志的可行性) | Shuai et al., 2025 "RCA of RISC-V Build Failures via LLM and MCTS"(结合 LLM 与 MCTS 推理定位构建失败根因,提供了多步推理验证的思路)
方向3:从 SFT 到 RL——利用自动化环境构建实现在线强化学习训练
论文的训练实验仅使用了离线 SFT(收集固定轨迹后训练),但 SWE-Factory 的核心价值在于它能自动构建可交互的评估环境——这天然适合在线 RL 训练。当前的瓶颈在于:SWE-Factory 构建单个环境平均需要 23-30 分钟,这对需要大量环境交互的 RL 训练来说过于缓慢。一个关键研究方向是设计"环境预构建 + 增量更新"的架构:预先为仓库的多个版本构建基础环境镜像,训练时仅做增量 patch 应用,将环境准备时间从分钟级降至秒级。结合 RLVR(Reinforcement Learning with Verifiable Rewards)范式,测试通过/失败可直接作为 reward signal,无需人工标注。这个方向需要解决环境缓存策略、reward shaping(如何处理部分通过的情况)、以及训练稳定性等问题。 相关工作:Wei et al., 2025 "SWE-RL"(首个将 RL 应用于 SWE-bench 的工作,用 GitHub issue 解决轨迹做 GRPO 训练,证明了 RL 在 SE 任务上的有效性) | Golubev et al., 2025 "Training Long-Context SE Agents with RL"(专门解决长上下文多轮交互场景下的 RL 训练,与 SWE-Factory 的环境交互模式高度契合) | Wei et al., 2025 "Self-Play SWE-RL"(通过自博弈进一步提升 SWE agent 能力,展示了 RL 在该领域的上限潜力)
方向4:Agent 协作拓扑的优化——从固定流水线到动态任务图
SWE-Builder 的四个 Agent 遵循固定的线性依赖关系(Explorer → Manager → Test Manager → Analyst),Test Analyst 的反馈也只能沿预定义路径回传。这种固定拓扑在面对复杂环境问题时可能不够灵活——例如,当 Dockerfile 构建失败的原因实际上是测试脚本中的路径假设错误时,当前架构需要多轮迭代才能定位到真正的问题源头。一个值得探索的方向是将 Agent 协作建模为动态任务图:Test Analyst 不仅能指定"哪个 Agent 需要修改",还能动态创建新的子任务(如"验证某个依赖版本是否可用")并分配给临时 Agent。这需要设计任务图的动态构建和调度算法、Agent 间的信息共享机制、以及防止无限循环的终止条件。 相关工作:Yu et al., 2025 "DynTaskMAS"(动态任务图驱动的异步并行多 Agent 框架,与本方向提出的动态任务图思路直接对应) | Wang et al., 2025 "AnyMAC"(通过 next-agent 预测实现灵活的级联协作,提供了动态路由的替代方案) | Wang et al., 2025 "AgentDropout"(动态裁剪冗余 Agent 以提升效率,为拓扑优化提供了互补视角)
参考链接: